

基于深度学习的自然图像和医学图像分割:综述
创建日期: 2020-01-10 00:01:21
本文基于一篇2019年年底最新的图像分割综述Deep Semantic Segmentation of Natural and Medical Images: A Review,对自然图像语义分割以及医学图像分割的知识点进行了梳理和总结。
摘要:图像语义分割的目标是给每个像素赋予一个类别标签,属于底层的图像感知问题,分割结果可用于更高级别的视觉任务。这篇review将最经典的基于深度学习的医学图像和非医学图像分割问题分为五个子问题进行了总结,分别为:网络结构,损失函数,数据合成(生成),弱监督方法和多任务方法,内容涵盖了经典、最新的基于深度学习的图像语义分割相关论文。最后又对自然图像和医学图像的未来研究热门方向进行了总结。
0. 介绍
近几年深度学习技术在许多领域内大放异彩,当下最热门的研究方向之一就是医学图像分析(医学计算机视觉),其中基于深度学习的医学图像分割应用价值巨大。在医学图像分析领域内,医学图像分割可用于影像引导介入诊疗,定向放疗等过程中。目前很多基于深度学习的医学图像分割可以处理各种形式的医学图像,包括X-ray、显微镜成像(Microscopy)、CT、MRI、PET、超声(Ultrasound,US)等等,这里推荐一个GitHub项目,其中包含了各种类型医学图像分割相关的论文,介绍非常详细。
对基于深度学习的图像分割问题,很多研究者通过模型架构的设计,模型压缩、量化,改进优化方法等方法来提高模型的预测精度和推理速度。相比于其他综述性文章,本文主要的贡献有以下几点:
- 介绍了当下一些经典的自然图像以及医学图像分割模型,包括处理2D和3D数据的模型。
- 本文将图像语义分割相关论文分五个子类:网络结构,损失函数,数据合成(生成),弱监督方法和多任务方法。图1展示了本文覆盖的论文范围(其中的序列模型包含在未来研究方向里面)。
- 在review的基础上,总结和建议了各个子类别的未来研究方向。
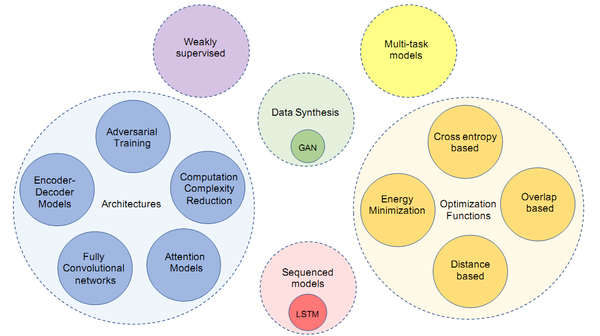
图1 本文覆盖的论文范围
首先对涉及到的相关名词解释一下:
先对图像数据做一个界定,生活中我们一般将由可见光得到的RGB数据称为图像/照片(二维图像),自然图像的分割大多数用的就是这种数据;如果另外加上深度信息,则称为深度图像或RGB-D图像(2.5维图像);由激光雷达或结构光可以得到点云数据(或体素数据)(三维图像)。以上这些都是自然界传递的视觉信息的数据化表达,都可以称为自然图像。而我们说的医学图像基本上都来自于人体或动物组织等(医学相关),是对人体内/外某些部位的成像结果,成像方式也多种多样(包括显微镜、超声、x-ray、ct等等),包括2D和3D数据,以上这些我们都可以称为是图像数据。
总的来说,医学图像属于图像的子类,所以针对图像的方法,应用到医学图像中是没有问题的,但我们通常说的图像特指自然图像(RGB图像),而医学图像包含的图像种类(格式,例如CT、MR等等)范围更加广泛,两者又有一定的区别。所以本文将图像大类直接分为自然图像和医学图像两部分分别做处理,在每个子类别,本文先讨论了自然图像语义分割,随后介绍医学图像分割。
图像分割和图像语义分割又有什么区别?我们通常听到的比较多的名词是图像语义分割,即为图像中每个像素赋予一个指定的标签(像素级类别预测问题),而图像分割泛指将图片划分为不同区域,对于每个区域的语义信息并没有要求,传统图像分割有很多这样的分割算法。但我们现在讨论的自然图像语义分割和医学图像分割,其实都属于图像语义分割范畴。医学图像分割的主要目的还是对图像中具有特殊语义信息(如肿瘤、器官、血管等)赋予标签,但医学图像分割的类别个数一般没有自然图像语义分割那么多。如VOC2012包含20个类别和一个背景类别,但医学图像分割很多都是二分类问题。
1. 网络结构(Network Architectures)
网络结构设计主要包括新神经架构的设计(不同深度、宽度、连接和拓扑结构)和新组件或层的设计。当前的网络结构基本采用全卷积+编解码结构,经典的网络有FCN、SegNet、U-Net、V-Net、DenseU-Net、DeepLab系列、PSPNet、RefineNet等等,这部分内容较多,每个网络的结构和创新点可以浏览下面这篇针对网络结构设计的文章:
李慕清:基于深度学习的自然图像和医学图像分割:网络结构设计zhuanlan.zhihu.com
2. 损失函数(Loss Function)
在图像分割问题中,常用的损失函数包括两大系列:一是基于交叉熵的损失函数,例如:原始交叉熵(CE)、加权交叉熵(WCE)和Focal Loss。二是基于重叠度的损失函数,例如Dice Loss、Tversky Loss(TL)等等。这部分内容较多,具体内容总结在下面这篇文章:
李慕清:基于深度学习的自然图像和医学图像分割:损失函数设计(1)zhuanlan.zhihu.com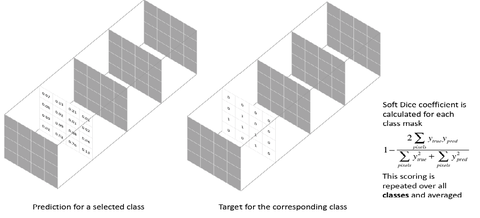
针对医学图像分割中的类别不平衡问题,以及医学图像特有的先验知识,损失函数在医学图像分割问题中的应用时会做一定的改进,大多数方法都是尝试通过在损失函数中加入权重/惩罚项来处理输入图像中的类不平衡问题,具体内容总结在下面这篇文章:
李慕清:基于深度学习的自然图像和医学图像分割:损失函数设计(2)zhuanlan.zhihu.com
3. 图像合成(数据生成)(Image Synthesis)
为避免过拟合和解决类不平衡问题,深度学习模型需要大量的数据来训练才会有好的效果。一种解决训练数据量不足的方案是数据扩充,这是一种在数据空间针对有限数据量的解决思路。一般的数据增强方法有几何变换(旋转平移等)和色彩空间增强等等,此外还有一种基于数据合成的方法,其输出的是全新的图像而非对已存在图像的修改。用于分割任务的基于GAN的数据增强技术在各个领域都有广泛应用(如遥感影像和解剖结构分割)。这一节我们主要总结基于GAN的数据增强技术在医学图像分析中的成果。
- Chartsias使用条件GAN网络从CT图像生成心脏MR图像。 结果表明,利用合成数据可提高分割精度,而仅使用合成数据会导致精度略微下降。(title:Adversarial image synthesis for unpaired multi-modal cardiac data.)
- Zhang等提出了一种基于GAN的3D到3D的转换模型,用于从相应的CT生成MR,反之亦然。 结果表明,合成数据可改善心血管MRI分割的性能。(Translating and segmenting multimodal medical volumes with cycle-and shapeconsistency generative adversarial network.)
- Abhishek使用条件GAN网络来从二值mask生成皮肤病变图像并将病变区域限制在二值蒙版中,实验结果表明使用合成图像可以提高皮肤病变分割的准确性。(Maskconstrained adversarial skin lesion image synthesis.)
- Zhang设计了用于在数字重建的X-ray图像和X-ray图像之间进行翻译的GAN,并获得了与在多器官分割中的有监督训练相似的准确性。(Task driven generative modeling for unsupervised domain adaptation: Application to x-ray image segmentation)
- Shin提出了一种GAN网络来生成具有脑肿瘤的合成MRI图像的方法,网络使用了两个公开的脑MRI数据集进行训练。(Medical image synthesis for data augmentation and anonymization using generative adversarial networks.)
总结:上述是几个比较典型的用GAN来生成数据的例子。总结一下,一种是数据转化的方式,从已有的数据生成新的数据,如CT->MRI或MRI->CT,也有从mask->数据。另一种是用公开数据集训练GAN,然后单独用GAN来生成新的数据。数据量不足的问题在医学图像分析中是非常常见的,当普通的增强方式无法满足需求时,我们可以采用这种基于GAN的数据生成方式来进行数据增强。
4. 弱监督方法(Weakly Supervised Models)
收集大量准确的像素级注释非常耗时耗力,但未标记和弱标记的图像可以以相对廉价的方式大量获取。 因此,图像语义分割的一个值得探索的方向是设计无监督和弱监督的模型。
例如Kim等人提出的一种使用Unpooling(SegNet提出的基于索引的上采样方式 )和Deconvolution(转置卷积)的弱监督语义分割网络,并使用Deconv得到的特征图来学习尺度不变特征。并在VOC和胸部X-ray图像数据集上评估了模型性能。(Scale-invariant feature learning using deconvolutional neural networks for weakly supervised semantic segmentation. ArXiv, abs/1602.04984,2016.)
4.1 弱监督方法在医学图像分割中的应用
对于医学图像而言,带有准确标注的数据比自然图像更加稀缺,这在很大程度上限制了基于监督学习的医学图像分析任务的解决(上一小节我们讨论的数据合成方法也是为了解决数据不足这一问题),一个解决思路是利用弱/无监督学习方法。
- Kervadec等在损失函数中添加了一个可微分项,在具有弱监督标签的数据集(心脏图像)上训练,得到了与全监督分割相似的性能。(Constrained-CNN losses for weakly supervised segmentation.)
- Afshari等使用全卷积架构和一个Mumford-Shah函数启发性的损失函数,在只具有边界框(bounding box)标注的PET图像数据上训练分割模型。(Weakly supervised fully convolutional network for PET lesion segmentation)
- Mirikharaji等提出学习空间自适应权重图,以解决像素级注释中的空间变化,并使用粗糙的标注数据来训练分割皮肤损伤的模型。(Learning to segment skin lesions from noisy annotations.)
- Peng等提出了一种基于乘法器交叉方向的方法(ADMM)训练具有离散约束和正则化先验的CNN的方法。
Perone等人将半监督的 Mean Teacher方法扩展到MRI数据分割任务,并表明可以在小数据方案中带来有效的提升(Deep semi-supervised segmentation with weight-averaged consistency targets)。在他的另一篇文章中,他使用自集成扩展了无监督域自适应方法来实现语义分割任务,实验结果表明,即使使用少量未标记的数据,该方法也可以改善模型的通用性。(Unsupervised domain adaptation for medical imaging segmentation with self-ensembling)
弱/无监督学习目前涉及的不多,没啥看法,有的话再补充。
5. 多任务模型(Multitask Models)
多任务学习是指一种可以同时学习多个任务的机器学习方法(包括深度学习),并且由于任务之间的共性和联系,因此提高了每个任务的学习效率和模型性能。
- Bischke等提出了一种级联的多任务损失函数来保护分割结果的边缘信息,在遥感图像分割任务上取得了SOTA的性能。(Multi-task learning for segmentation of building footprints with deep neural networks)
- Chaichulee等扩展了VGG16网络,使其包含了可进行患者检测的全局平均池化层和用于皮肤分割的全卷积网络层。在来自新生儿重症监护病房的临床研究图像上对提出的模型进行了评估,结果表明该模型对光线,肤色和姿势的变化具有很强的鲁棒性。(Multitask convolutional neural network for patient detection and skin segmentation in continuous non-contact vital sign monitoring)
- He等设计了一个类似U-Net [119]的编码器-解码器架构,能从CT扫描中分割胸腔器官并进行全局切片分类。(Multi-task learning for the segmentation of thoracic organs at risk in CT images)
- Ke等人设计了一个多任务的U-Net结构的模型来解决三个任务:分离错误连接的对象(查错),检测每个对象(检测)并为每个对象按像素标注(分割),然后在食物的显微镜图像数据集上对模型进行了评估。(A multi-task U-Net for segmentation with lazy labels)
- He等人在Faster-RCNN的基础上添加了一个新分支来进行每个对象的mask预测(实现了实例分割),该模型被称为Mask-RCNN,是一个广泛应用的多任务模型,例如为手术机器人提供检测和分割,用北极的遥感图像解释气候变化规律,将遥感图像转换为地图,检测图像伪影等等。(Mask R-CNN.)
总结:多任务模型的优势在于可以提高每个任务的学习效率和性能。针对图像感知问题,多任务模型的每个任务可以共用backbone的特征图(提高了效率),任务之间的信息交流提供了更多可学习的知识,有助于提高模型的性能。
5.1 多任务模型在医学图像分割中的应用
Mask-RCNN也已用于医学图像分割任务,例如在显微镜下自动分割细胞并跟踪细胞洄游;从组织学图像或显微镜图像中检测并分割细胞核;检测并分割口腔疾病;分割胸部X-ray中的肋骨。而且Mask-RCNN已经成功扩展到3D数据处理的任务中,例如针对肺部CT图像的肺结节检测和分割;弥散MRI上的乳腺病变检测和分类。
6. 主流模型在自然图像分割数据集上的性能对比
下表中展示了部分经典模型在PASCAL VOC2012数据集上的测试结果:
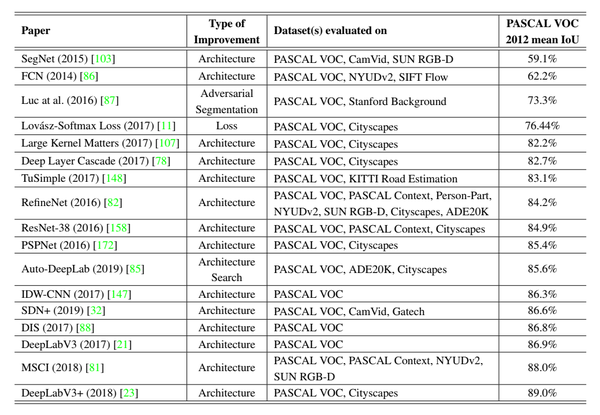
经典模型性能对比
从表中可以看出,模型改进主要集中在模型结构设计方面;2019年NAS技术开始在语义分割任务崭露头角,估计今后NAS技术势必会逐渐取代人工设计;相对而言对损失函数的改进比较少。我们以mIoU作为评价指标对模型进行了排序,可以发现:最初的FCN和最新的DeepLabV3+(2018)以及Autu-DeepLab(2019)对比,mIoU有了很大提升(空洞卷积、ASPP等方法的应用起了很大的作用)。
7. 总结
通过对自然图像和医学图像分割相关文献的对比,我们可以发现医学图像分割问题存在的潜在困难:
- 医学图像(2D和3D)一般分辨率较高,目前的GPUs还无法直接高效的处理整张图片,因此一般需要将图像裁剪为小图像进行处理,而这又会限制模型正确地捕获空间信息和空间关系。
- 不同型号的医疗设备会生成独特且难以检测的噪声模式(偏差),这会降低模型推理的准确性,也使得很难将模型应用到不同型号的设备上,侧面也加大了收集同一型号设备产生的数据的困难。
- 医学图像分割领域的另一个潜在困难是缺少大量准确标注的数据,这鼓励了研究人员对于半监督模型和无监督模型的探索。
- 与自然图像相比,在医学图像分析模型中加入一定的先验知识通常更有可能,很多相关算法也证明了这点。
图像语义分割应用广泛,虽然基于深度学习的图像分割已经取得了巨大的成功,投资商对AI充满了信心,但我们心知肚明,论文中的idea想在现实场景中落地依然困难重重,例如医学领域对漏检率要求极高,自动驾驶要求实时的推理速度,移动端计算资源地限制等等。这些问题还有待进一步研究来解决。

8. (医学)图像语义分割的未来研究方向
这部分主要介绍一下当前或未来几年(医学)图像语义分割领域内值得研究的方向,主要还是集中在网络结构设计、三维数据分割模型设计和损失函数设计三个方面。此外,再介绍一些其他与语义分割方面相关但并不主流的研究方向,这部分的详细内容总结在下面这篇文章里面:
李慕清:对医学图像分割未来发展方向的一些讨论zhuanlan.zhihu.com


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 记一次.NET内存居高不下排查解决与启示
· DeepSeek 开源周回顾「GitHub 热点速览」
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了