

视网膜血管分割代码(Pytorch实现)
创建日期: 2021-12-24 17:00:00
update log(2021.12.24):B站视频删除了,回放看了一下,讲的不太行......2333,时间过得真快,转眼就是2022年了啊
2021.08.01更新代码讲解视频:
视网膜血管分割代码分析(Pytorch实现)_哔哩哔哩_bilibili
简介:
本文主要分享我在做视网膜血管分割深度学习算法的过程中,整理出来的一套视网膜血管分割代码。简单介绍一下,我读研期间的研究方向是计算机视觉(侧重于语义分割),主要做一些医学图像分割算法和偏工程的机器视觉部署方面的工作,具体研究课题是基于深度学习的视网膜血管分割算法研究,选择这个课题的原因也比较朴实------实验室硬件计算资源有限。相比于深度学习算法创新,个人也更加偏向于算法落地应用方面,这个寒假还要恶补C++和计算机系统方面的知识。在这之前,把我的视网膜血管分割代码分享给大家,项目地址:
https://github.com/lee-zq/VesselSeg-Pytorch
该项目是基于pytorch深度学习框架实现的视网膜血管分割代码,包括数据预处理、模型训练、模型测试以及可视化等功能,可以在此基础上进一步研究视网膜血管分割算法。最近我把这套代码进行了重构和简化,在比较晦涩的地方也添加了注释,力求任何一个入门者都能看懂。当然也可能存在bug和表述不清的地方,也希望大家能提issue指明问题,我会尽可能快速debug并更新代码,不胜感激。(如果对视网膜血管分割比较熟悉,可以跳过下面的介绍,直接阅读GitHub项目Readme)。Besides,Star⭐是我Git push的动力,后续我会搜集经典和SOTA的视网膜血管分割模型进行复现。
1. 相关知识
基于深度学习做视网膜血管分割任务有一些相关的知识点可能需要说明一下,如果你刚入门建议先了解清楚。如果需要的话,我会单独写篇文章介绍。相关知识主要有以下几点:
① 公开视网膜血管分割数据集。深度学习需要数据来驱动,发表文章需要和其他文献的方法对比,所以建议使用公开视网膜血管分割数据集。视网膜血管分割的公开集最常用的有DRIVE、STARE和CHASE_DB1这三个,还有HRF等等不常用的数据集。当然,医学图像分割领域内私有数据还是比较认可的,也可以使用。
② 基于深度学习的图像语义分割。这方面需要掌握基本的深度学习理论知识、Python和Pytorch深度学习框架,以及语义分割相关的知识点,如FCN和评价指标等等。
③ 视网膜血管分割研究现状。这方面的工作现如今已完全深度学习化,深度学习方法的性能相比于血管跟踪、模板匹配、形态学处理这类传统方法要好很多,机器学习方法如今也逐渐被淘汰。
其他需要的也可以评论区指出。
2. 环境配置
本项目代码在Ubuntu20.04系统中使用Anaconda3创建的python虚拟环境运行,环境主要的包和版本如下:
# Name Version
python 3.7.9
pytorch 1.7.0
torchvision 0.8.0
cudatoolkit 10.2.89
cudnn 7.6.5
matplotlib 3.3.2
numpy 1.19.2
opencv 3.4.2
pandas 1.1.3
pillow 8.0.1
scikit-learn 0.23.2
scipy 1.5.2
tensorboardX 2.1
tqdm 4.54.1
Pytorch1.0以上的版本兼容性很好,API基本没变,所以可以先尝试已存在的环境进运行。GPU为2080Ti,此外为了使训练效率更高,训练数据会一次性加载到内存,所以8G以下内存可能出出现内存溢出Error(具体取决于提取的patches数量)。
3. 使用方法
3.1 下载代码
git clone https://github.com/lee-zq/VesselSeg-Pytorch.git
代码结构以及功能注释如下所示:
VesselSeg-Pytorch # Source code
├── config.py # Configuration information
├── lib # Function library
│ ├── common.py
│ ├── dataset.py # Dataset class to load training data
│ ├── extract_patches.py # Extract training and test samples
│ ├── help_functions.py #
│ ├── __init__.py
│ ├── logger.py # To create log
│ ├── losses
│ ├── metrics.py # Evaluation metrics
│ ├── pre_processing.py # Data preprocessing
├── models # All models are created in this folder
│ ├── denseunet.py
│ ├── __init__.py
│ ├── LadderNet.py
│ ├── nn
│ └── UNetFamily.py
├── prepare_dataset # Prepare the dataset (organize the image path of the dataset)
│ ├── chasedb1.py
│ ├── data_path_list # image path of dataset
│ ├── drive.py
│ └── stare.py
├── test.py # Test file
├── tools # some tools
│ ├── ablation_plot.py
│ ├── ablation_plot_with_detail.py
│ ├── merge_k-flod_plot.py
│ └── visualization
└── train.py # Train file
3.2 数据集准备
从天翼云盘链接下载我打包好的视网膜血管分割数据集,压缩包包含DRIVE, CHASE_DB1和STARE三个数据集。或者你也可以从官网下载对应的数据集(DRIVE,STARE和CHASE_DB1)。
将下载好的datasets.rar文件解压到本地硬盘,得到的数据集目录结构如下:
datasets
├── CHASEDB1
│ ├── 1st_label
│ ├── 2nd_label
│ ├── images
│ └── mask
├── DRIVE
│ ├── test
│ └── training
└── STARE
├── 1st_labels_ah
├── images
├── mask
└── snd_label_vk
3.3 创建数据集路径索引文件
项目根目录下的"./prepare_dataset"目录下有三个文件:drive.py,stare.py和chasedb1.py。分别将三个文件中的“data_root_path”参数赋值为上述3.2准备好的数据集的绝对路径(例如: data_root_path="/home/lee/datasets")。然后分别运行:
python ./prepare_dataset/drive.py
python ./prepare_dataset/stare.py
python ./prepare_dataset/chasedb1.py
即可在"./prepare_dataset/data_path_list"目录下对应的数据集文件夹中生成"train.txt"和"test.txt"文件,分别存储了用于训练和测试的数据路径(每行依次存储原图,标签和FOV路径(用空格隔开))。
3.4 训练模型
在根目录下的"config.py"文件中修改超参数以及其他配置信息。特别要注意 “train_data_path_list"和"test_data_path_list"这两个参数,分别指向3.3中创建的某一个数据集的"train.txt"和"text.txt"。 在"train.py"中构造创建好的模型(所有模型都在"./models"内手撕),例如指定UNet模型:
net = models.UNetFamily.U_Net(1,2).to(device) # line 103 in train.py
修改完成后,在项目根目录执行:
CUDA_VISIBLE_DEVICES=1 python train.py --save UNet_vessel_seg --batch_size 64
上述命令将在1号GPU上执行训练程序,训练结果保存在“ ./experiments/UNet_vessel_seg”文件夹中,batchsize取64,其余参数取config.py中的默认参数。
可以在config中配置培训信息,也可以用命令行修改配置参数。训练结果将保存到“ ./experiments”文件夹中的相应目录(保存目录的名称用参数"--save"指定)。
此外,需要注意一点,config文件中有个“val_on_test”参数。当其为真时表示会在训练的每个epoch结束后在测试集上进行性能评估,并选取"AUC of ROC"最高的模型保存为“best_model.pth”;当其为假时,会用验证集性能评估结果(AUC of ROC)保存模型。当然保存最佳模型依据的指标可以自行修改,默认为AUC of ROC。

训练过程示例(UNet)
3.5 测试评估
在“test.py”文件中构造对应的模型(同上),例如指定UNet模型:
net = models.UNetFamily.U_Net(1,2).to(device)
测试过程也需要"./config.py"中的相关参数,也可以在运行时通过命令行参数修改。
然后运行:
CUDA_VISIBLE_DEVICES=1 python test.py --save UNet_vessel_seg
上述命令将训练好的“./experiments /UNet_vessel_seg/best_model.pth”参数加载到相应的模型,并在测试集上进行性能测试,其测试性能指标结果保存在同一文件夹中的"performance.txt"中,同时会绘制相应的可视化结果。
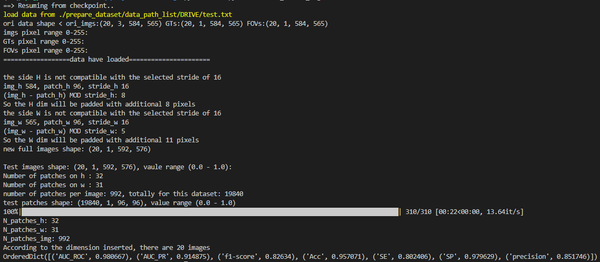
测试过程示例(UNet)
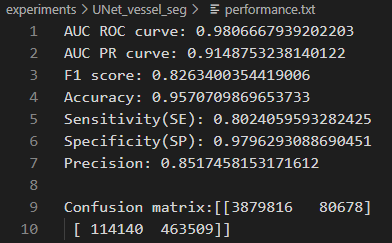
DRIVE数据集预测结果性能指标(UNet)
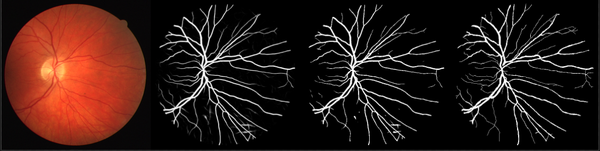
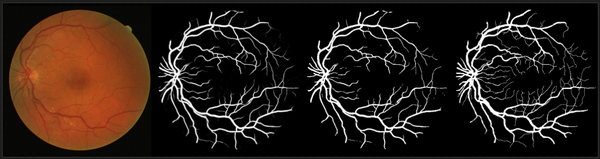
可视化结果示例(LadderNet模型结果):
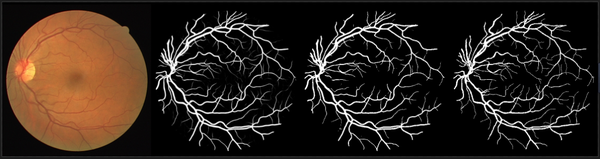
DRIVE数据集分割结果示例(依次为原图、概率预测图、二值预测图和标签图):
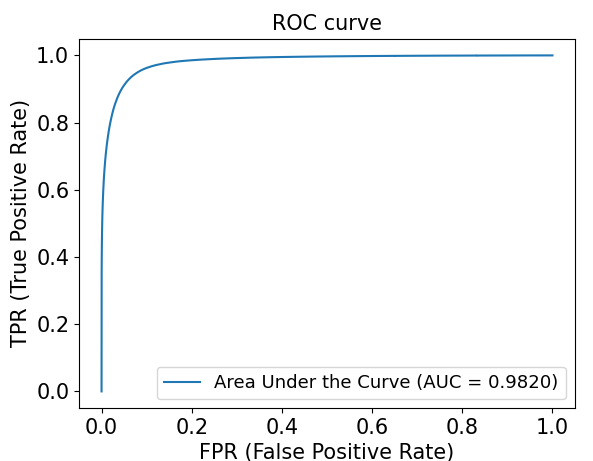
DRIVE测试集ROC曲线
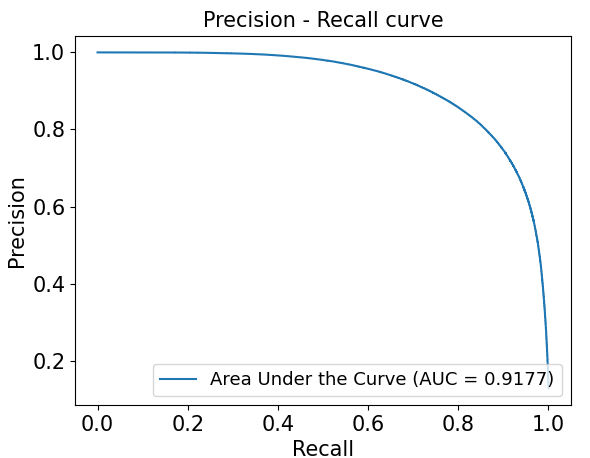
DRIVE测试集PR曲线
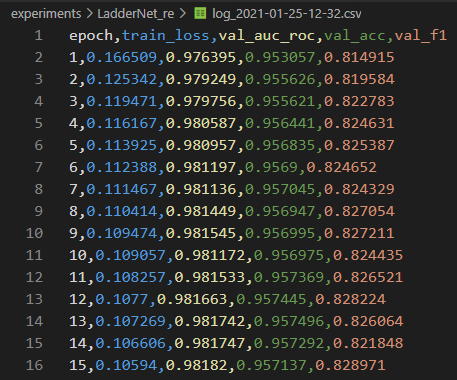
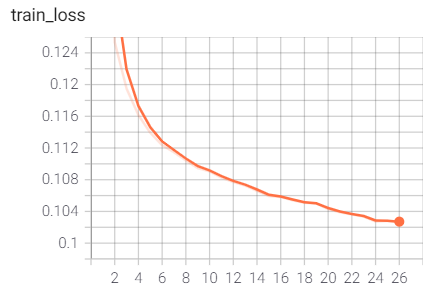
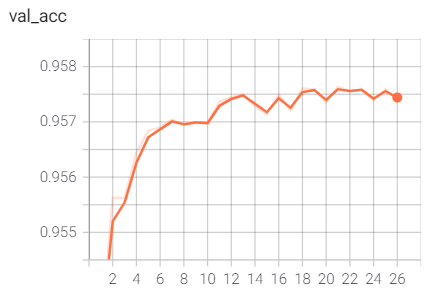
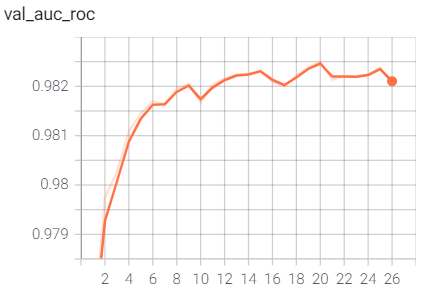
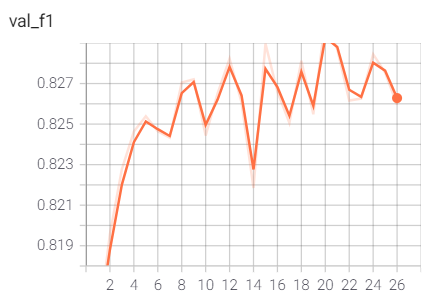
训练过程验证性能变化记录
训练过程的指标记录也可通过Tensorboard日志文件查看:
以上。
- 目前代码整体上已经整理完毕,还有一些注释和细微修改需要更新。有些我一个人考虑不周的地方还请指正。
- 以上介绍部分或者相关内容有表述不详尽的地方,还请提出来。有必要的话,我再写一篇博客或者出一期视频讲解。
PS:该项目代码参考了一些其他已发布代码或设计方法,主要参考:


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· 记一次.NET内存居高不下排查解决与启示
· DeepSeek 开源周回顾「GitHub 热点速览」
· 白话解读 Dapr 1.15:你的「微服务管家」又秀新绝活了