OCR横向评测 -- 软工案例分析
第一部分 调研&评测
使用感受
1. 使用门槛
笔者在老师和其他同学的帮助下使用项目测试网站进行了测试。感谢老师提供了配置好的blob storage,降低了我们的"评测"的门槛。
虽然没有亲手配置项目,但是观察项目设置,需要配置的主要有Azure blob container和Form recognizer service URI & API key,应该说配置门槛还是不高的。
2. 界面设计
界面设计简洁明了。这里截取了项目网页的侧边栏,几个图标分别对应:Home,Tags Editor,Train,Predict,Setting和Connections。中间的三个也是分别对应了Deep Learning的数据标注、训练和预测三个过程。使用起来比较方便,知道应该去哪里干什么。(为了便于查看,已将截图旋转90°)

3. 数据标注
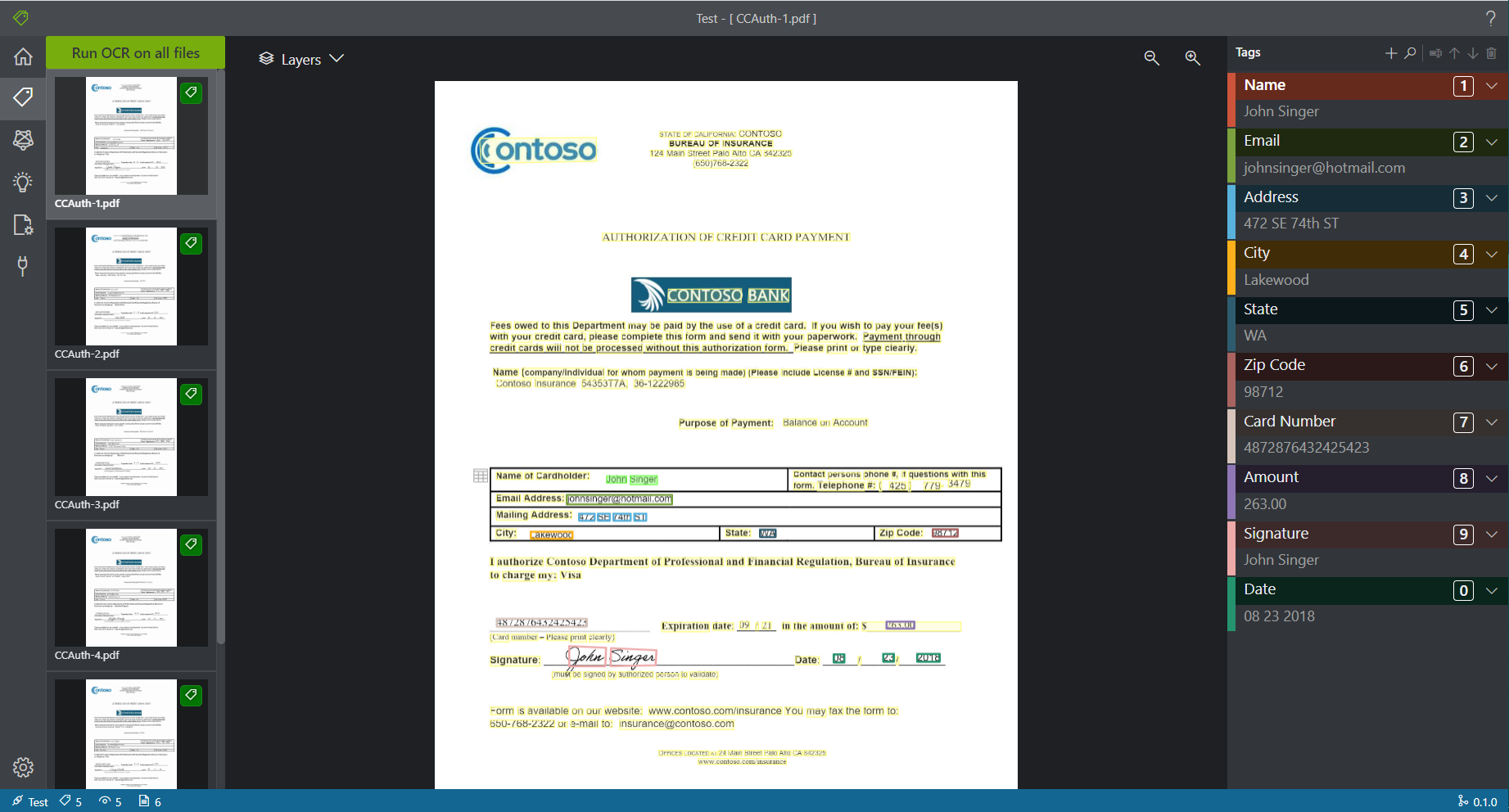
数据标注这里可以使用blob container中的PDF打上tag。对于结构化的PDF,已经提前做好了分块和文字分词。
个人认为比较好的地方在于每个tag可以设置不同的格式,后续在导出JSON的时候也能看到每个tag带着相应的类型。
💡和之后对比的阿里云、腾讯云的OCR产品来说,我认为这是一个很好的特性。对于这类定制型的OCR识别产品而言,用户一般可以估计每个项目中内容的类型,而让用户明确了这些类型,也能使提供商能提供更定制化的、更准确的模型。
4. 模型训练
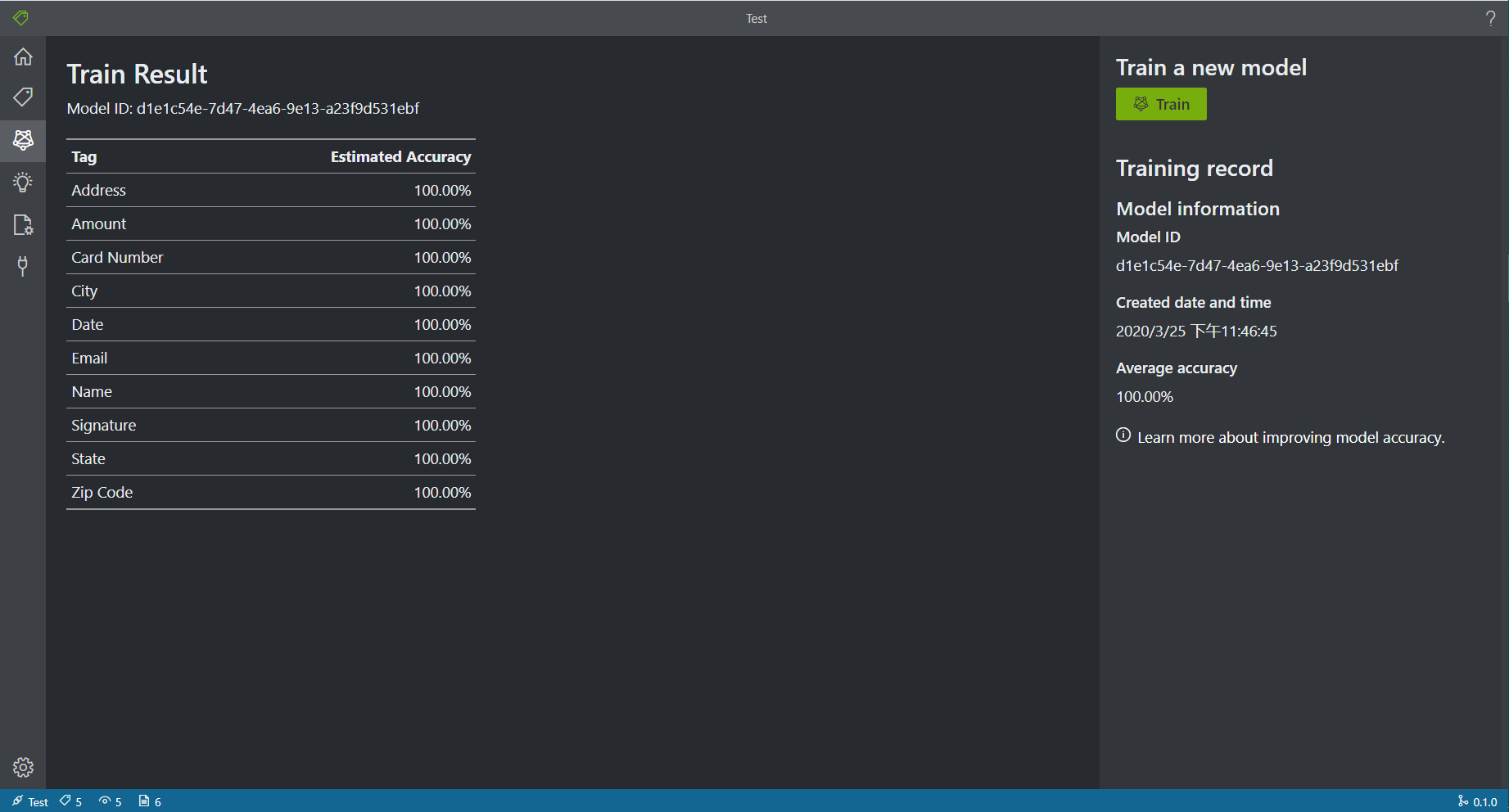
在本款OCR产品中,模型训练非常简单,在Train栏目中点击训练即可。训练结束后会返回训练集上的准确度。这里对用户比较友好,用户无需关注模型的超参数设置等细节,一键训练即可。
5. 模型预测
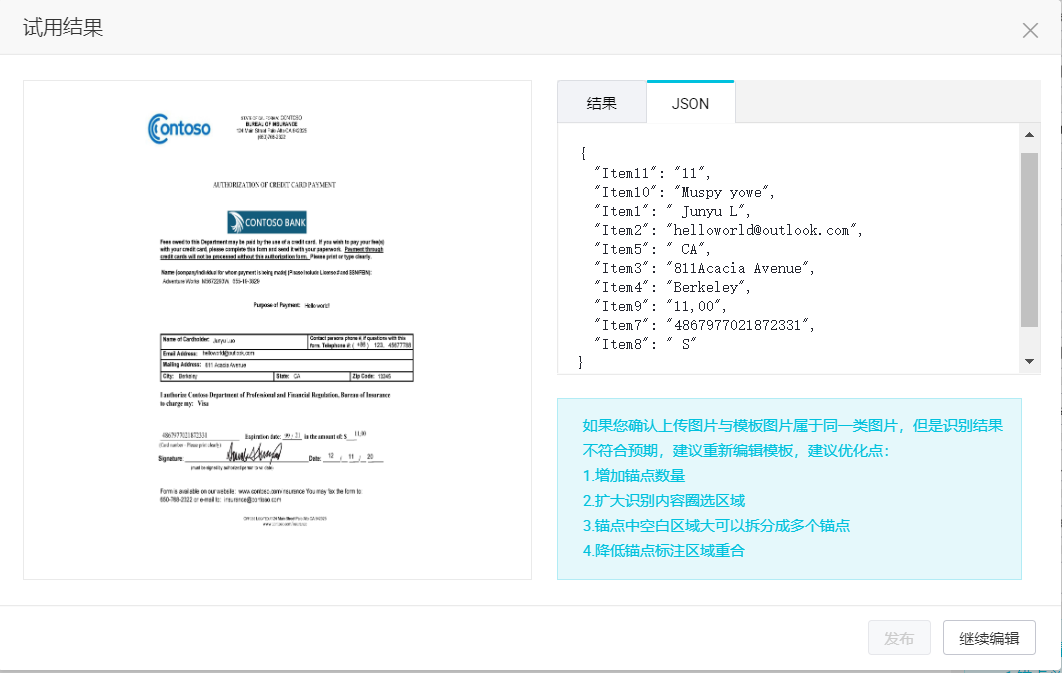
在Predict界面上传需要需要做预测的问题即可,这里测试PDF文件和JPEG文件均可以执行预测。能够返回每个tag的结果和置信度,同时支持以JSON格式进行批量导出。
在进行功能性测试时,我对提供的测试文件进行了一些修改替换,例如将签名换成了Donald Trump的 😂,看到没有成功识别出来。不过,将Amount换成了带有,分隔的数字可以识别到(但是注意到置信度有下降(\(\approx 100\% \rightarrow 80\%\)))。
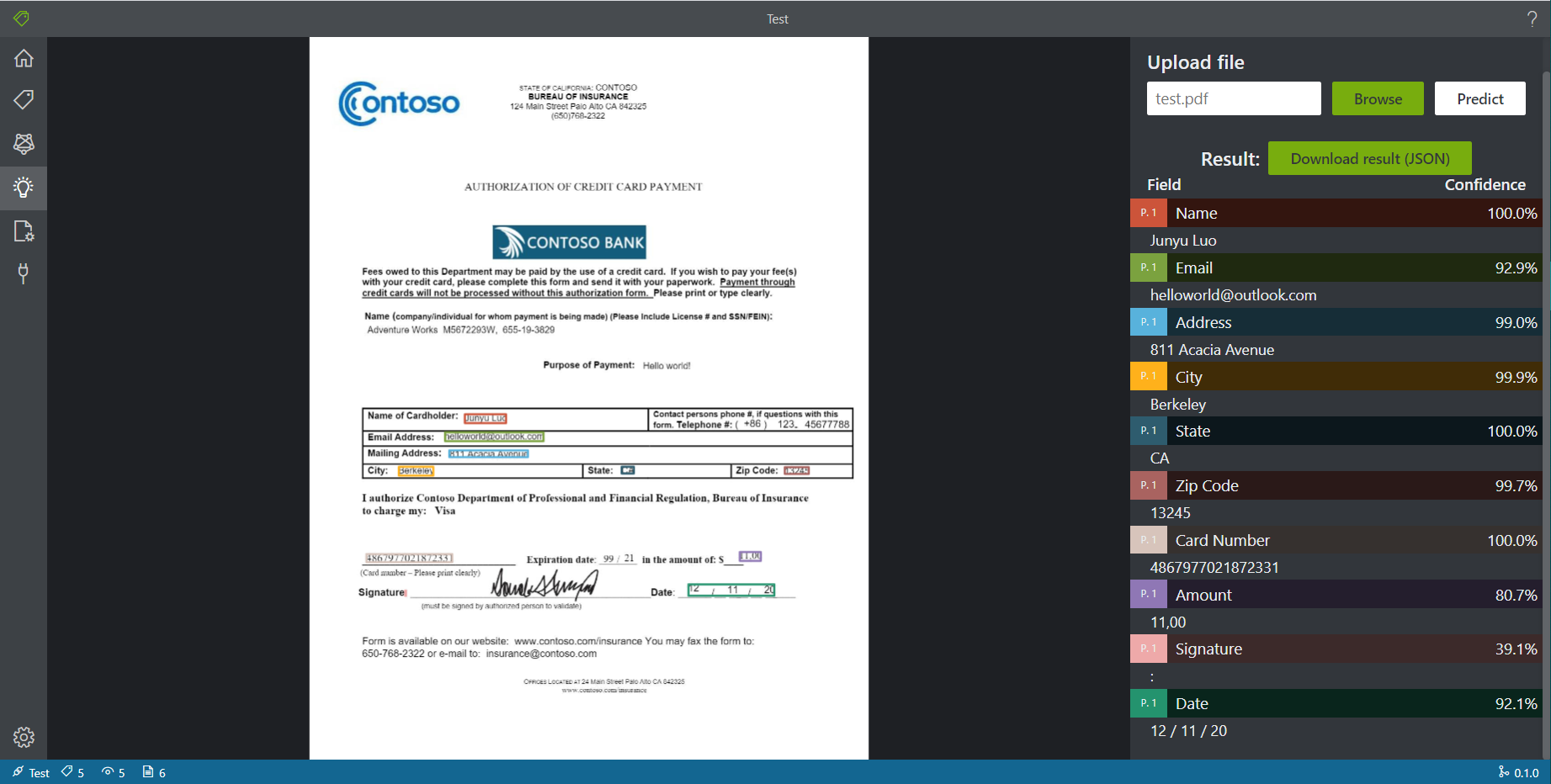
不过Trump的签名确实有些困难(毕竟人眼也不好认清),将它换成我自己写的规整很多的签名后能够识别出来。
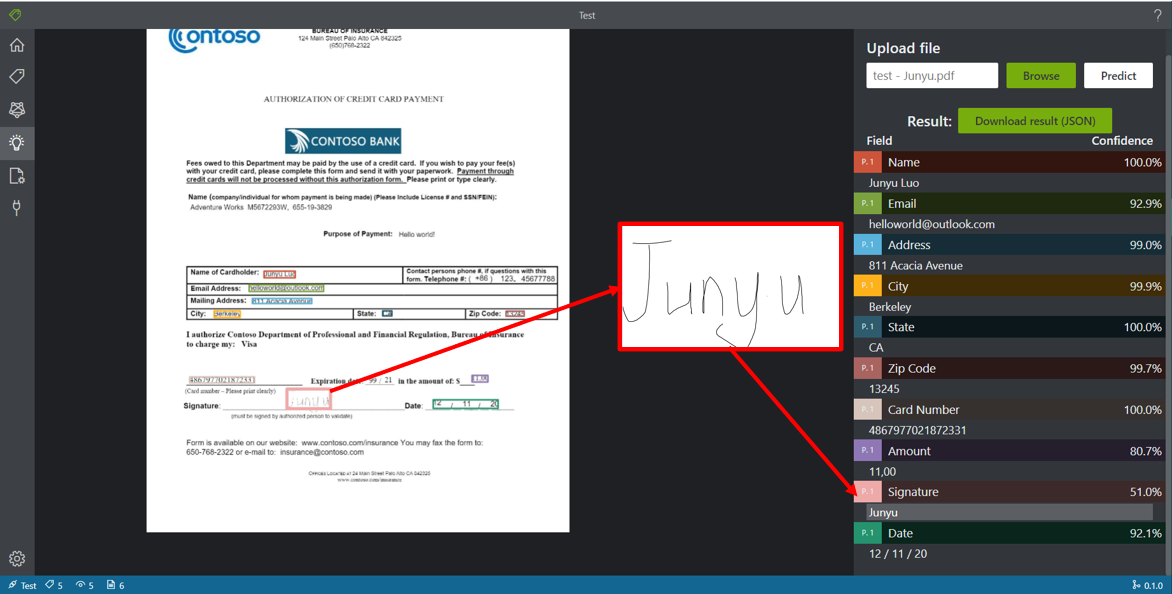
不过看到置信度还不是很高,模型对于手写文字的识别可能还需要提升。但是签名时字体有可能会比较潦草,识别起来本身就具有难度(或许这里可以将签名区域的图片抓出来反馈即可?)。
前面两个测试都是PDF文档,由于之前标注也是在PDF格式上进行的,我希望测试该模型是否支持图像格式。因为在实际使用中,我们会遇到很多没有标准的PDF的情形,而图片是更加常见的格式。因此,我将PDF文档转存为JPEG格式后上传预测。
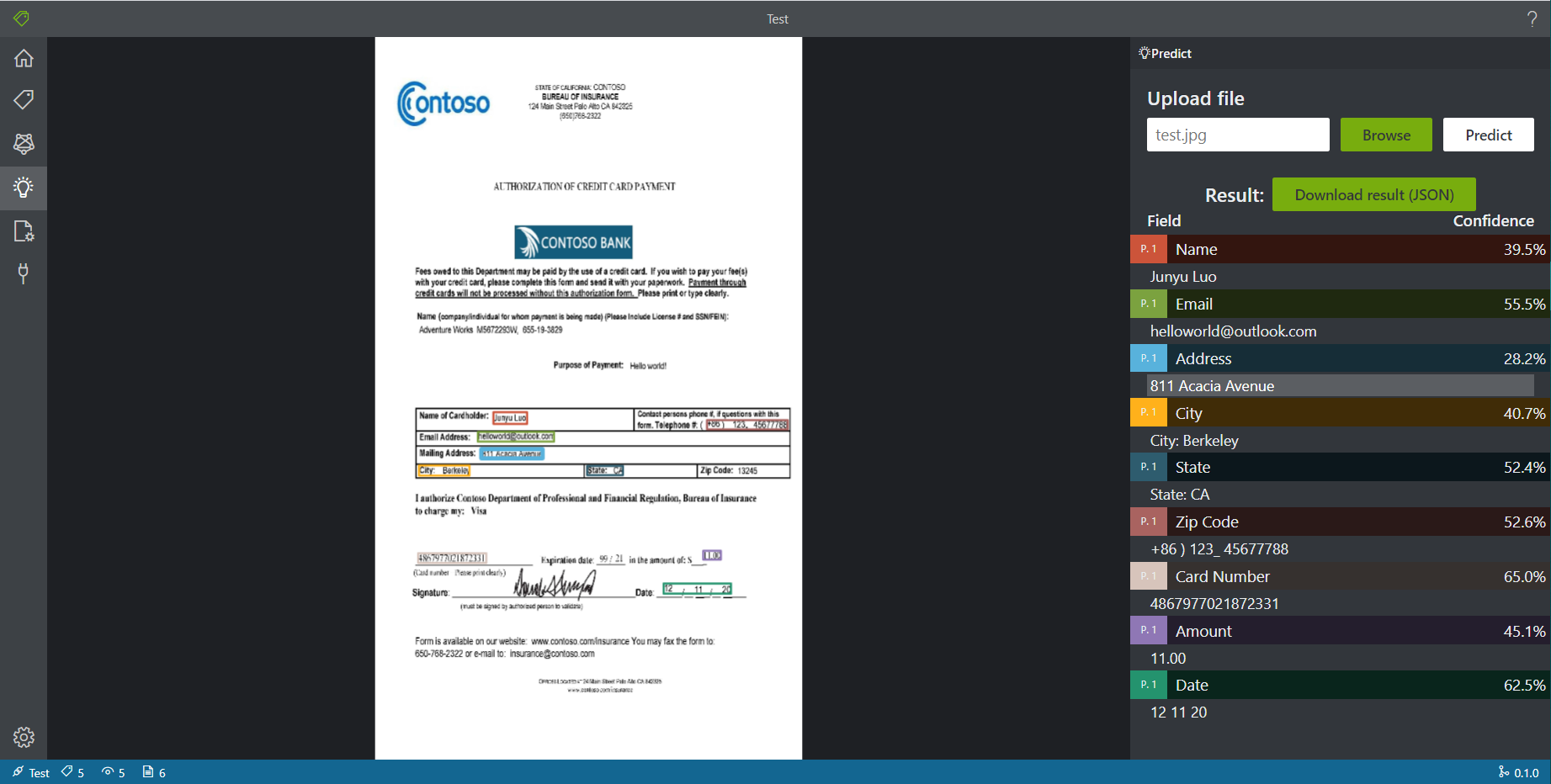
预测成功了,在PDF上打的标注能考虑到支持对于图像的预测是很好的。
和之前的结果对比,tag基本都能找到,内容的准确度也能保证。
但是:
- 置信度较低(相比于PDF版本);
- 一些tag抓出来的文字有和tag重复的现象,如
City一栏的结果为City: Berkeley,从图中来看,可能是因为候选框打的大了些。
6. 体验评价与改进建议
在体验完本产品后,笔者又体验了两个竞品(腾讯云提供的OCR服务,阿里云提供的OCR服务),对使用本产品的体验做了总结。
好的方面:
- 总体体验比较友好。门槛不高、界面简洁,数据标注过程中的效率也很高。
- 一键训练、一键预测。无需了解内部实现机制,直接当黑盒使用即可。
- Tag处可以让用户设置Tag的属性。这点我认为考虑的很周到。
- 多种格式文件预测支持。笔者在腾讯云和阿里云的竞品中看到,他们只能支持对JPEG格式进行推断。
- 能够提供Tag预测的置信度,对于置信度不高的可以人工查验。而阿里云等竞品没有反馈置信度。
💡可能需要改进的方面:
- 对于结构化的PDF表现比较优秀,而对图像等表现不是那么理想。对于测试集而言,图像可能会更加常见(扫描纸质单据)。笔者认为增加图像的标注或许有助于提升模型对图像预测的准确性。
- 是否支持图像标注?由于目前的训练集中只有PDF文档,因此笔者无法验证是否支持JPEG的标注。阿里云提供的服务中是对图像进行标注的(但是他不支持PDF的)。
- 模型是否可以替换?目前只能使用系统自带的预训练模型,能够提供接口让用户自定义模型(甚至可视化网络接口,用户在界面上拖动调整😂)?或者是提供多种不同预训练模型让用户选择。
- 训练集上传比较复杂。需要在Azure Blob Container中上传(当然可能是由于没有账户所以觉得困难)。对比阿里云的OCR服务,是可以实时上传训练数据的。
- 是否可以批量预测?对于实际部署来说,相信会有接口使用户可以批量上传、批量预测、批量导出。
- 手写字体识别可能需要加强。(需求应当是验证签名和用户名的一致性)。不过很多签名人眼都难以分辨,识别确实比较困难。
7. BUG反馈
- 开始时,本地使用Docker搭建,会出现一些不明原因的报错,且反馈较为缓慢(有可能是网的原因)。这里的报错对于用户寻找错误原因不太友好。

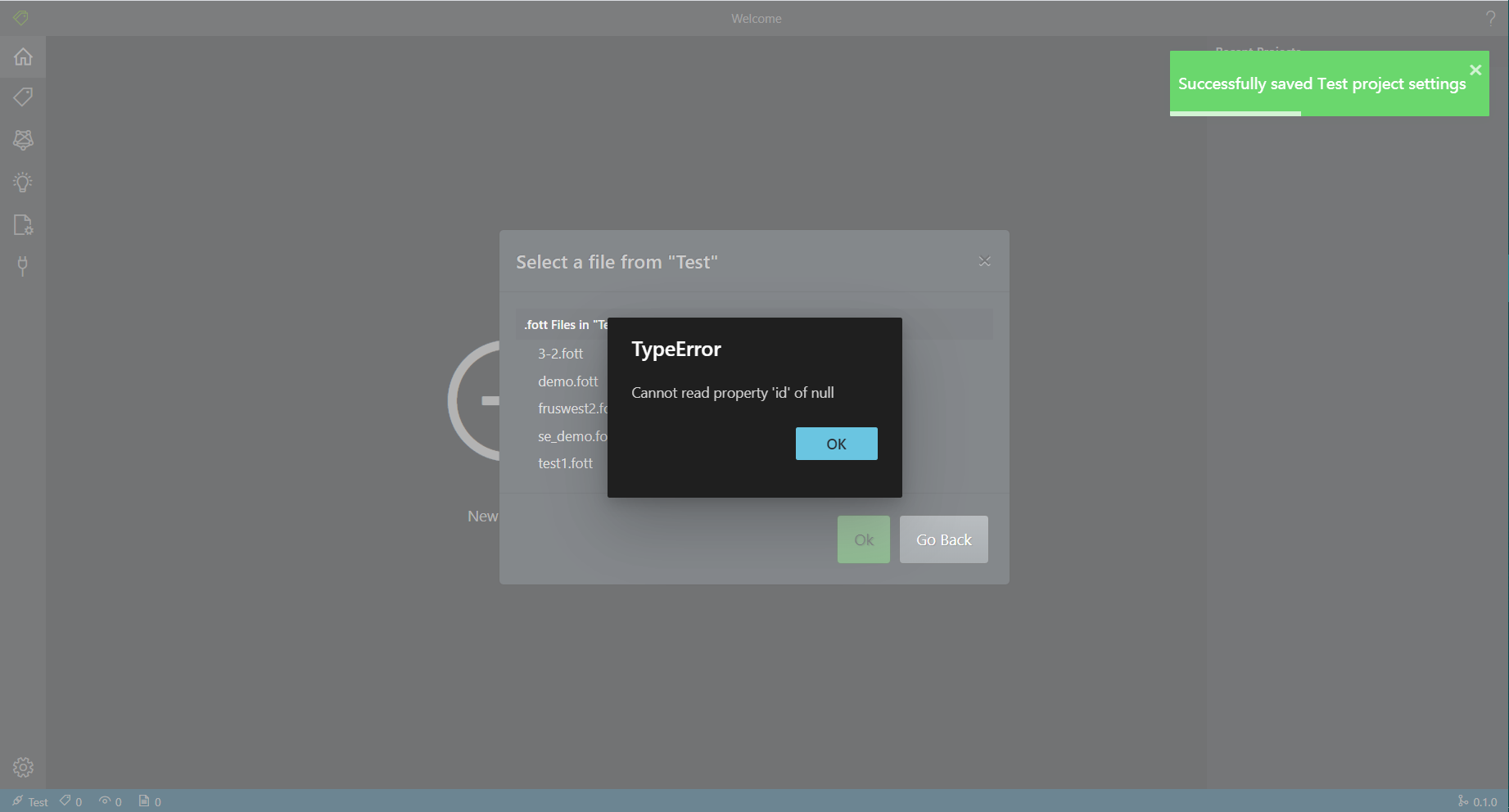
- 图像识别预测时,会有多余的字符出现,猜测由于检测框过大。
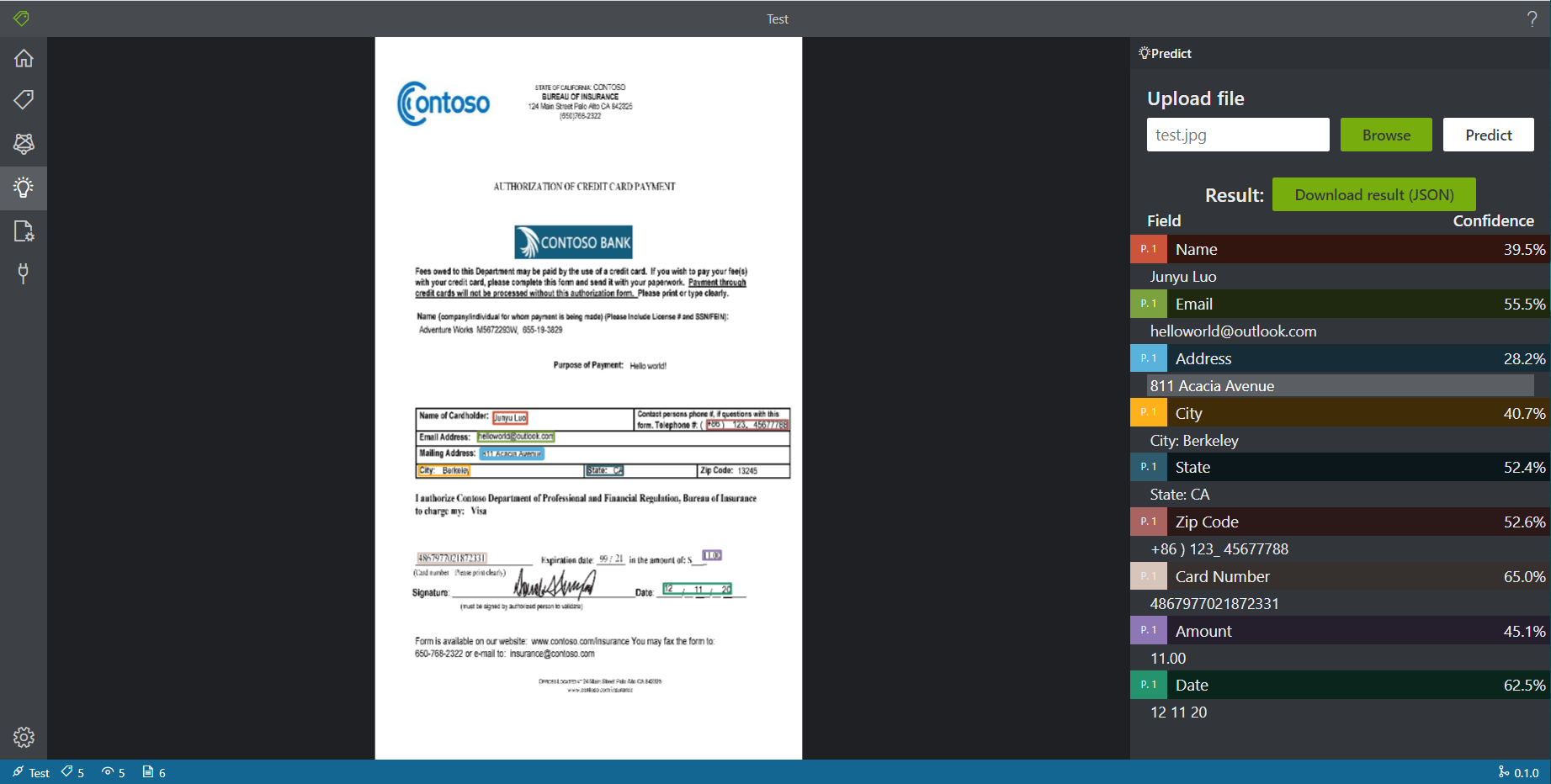
- 出现重复预测的情况。(是否和PDF的结构有关系?这里的错误在我将PDF转为JPEG后便没有了)

8. 对比评价
结论:好,不错。
以下是将OCR-Form-Tools 和腾讯云提供的OCR服务,阿里云提供的OCR服务的对比。评分1-5。
| 描述 | OCR-Form-Tools | 腾讯云 | 阿里云 | |
|---|---|---|---|---|
| 功能 | 预测准确性 | 4 | 3 | 4 |
| 多格式支持 | 4 | 3 | 3 | |
| 用户定制模板预测 | 5 | 0 | 5 | |
| 批量预测 | 3 | 3 | 5 | |
| 体验 | 界面友好 | 5 | 3 | 4 |
| 流程简单 | 4 | 3 | 3 |
9. 竞品评测
阿里云OCR服务评测
阿里云也能提供自定义表单模板的OCR服务。这里使用上文中的测试文档做训练模板(转为JPEG格式),使用我自己修改的文档作为测试集。
模板上传
在网页端直接上传即可。

数据标注
阿里云提供的数据标注必须是对图像的。红框是需要在图像上选择的锚点。蓝框是对应的识别内容。逻辑和上文中的OCR-Form-Tools基本类似,不同之处在于对于图像框选内容没有结构化PDF点选那么顺滑。
我认为阿里云可以添加PDF作为模板,因为在实际使用中创建该服务的人一般会有PDF模板,用PDF标注更快、更准确。(场景:保险公司收集理赔申请,保险公司有该理赔申请文档的PDF模板)。

数据预测
可以看到预测结果是不如上文中的OCR-Form-Tools的,很多Item出现了错误。
我认为可能会有一下原因:
- 数据量太少,上文中有5篇文档做训练集,这里只有1篇。
- 使用图片做训练集,难度提升。
- 数据标注时我做的数据框太小。
- 锚点没有选够,可以选一些图像中的特征作为锚点(例如Logo)。
腾讯云OCR服务
由于在腾讯云这里我没有找到用户自定义OCR识别,于是使用了自带表格识别工具。可以看到对于表格内容的抓取识别还是不错的。
不过我认为用户自定义OCR还是有这样的需求的(可能是我没有找到),腾讯云可以考虑添加这样的项目。

第二部分 分析
估计用时
使用此服务的所有功能,估计这个软件/网站/服务做到这个程度大约需要多少时间(团队人数6人左右,计算机大学毕业生,并有专业UI支持)。
不知模型是否需要自研?😂
如果使用超轻量级中文OCR的模型的话,从部署上来说个人认为需要2个月左右的时间(需求分析+模型部署+前端开发+测试调试)。不过对于模型的调试和打磨可能需要较多的时间和精力。
竞品分析
分析这个软件目前的优劣(和类似软件相比),这个产品的质量在同类产品中估计名列第几?
具体优劣已经在第一部分进行了分析。
个人认为在本次比较的三款OCR产品中,OCR-Form-Tools的准确率是最好的。
当然这样的比较是不公平的,因为标注数据集的格式不同。我认为三者都有提升的空间。
第三部分 建议和规划
市场和用户
首先,市场有多大?潜在的用户有多少?
潜在用户:需要收集表单并进行统计者(如:银行、保险公司、证券公司等)。包括电子填报表单和纸质填报表单。
市场:如果目前主要使用人力收集录入,使用该表单管理能够大幅度节约人力成本。以人均1年使用2次计算,仅在中国一年可使用数十亿次。
竞品比较
目前市场上有什么样的产品了,它们的优势劣势在哪里?和它直接竞争的产品在那里?
本文中分析的竞品有腾讯云的OCR产品和阿里云的OCR产品。其中的优劣也已经在第一部分分析了。
我认为同时支持多格式识别和训练是必要的。目前阿里云、腾讯云的产品不支持PDF的训练和预测,只能使用图像格式。这里是两个产品需要改善的地方。
用户画像
作为新的项目经理,这个产品的核心用户群是什么样的人,典型用户长什么样?学历,年龄,专业,爱好,收入,表面需求,潜在需求都是什么?
核心用户群体:商业客户,如企业、政府机构等,以银行和保险公司为例。
- 银行:存单等。对速度要求高(银行客户不希望等待业务员录入)。
- 保险公司:保单、理赔申请等表单。数量大,人工录入成本高,OCR识别后直接录入数据库即可。
需求:快速识别大量格式化表单文本。
潜在需求:对于表单文本的统计、录入、审批等。增强项目功能,接入企业OA系统,从识别到审批流程化。
新增功能
新增功能:增加对于图像的标注功能;
综合来看本产品对于不同格式文件的适用性是较好的,但是如果一类文档没有pdf格式,只有图像格式(如:火车票、身份证),则无法进行标注。而解决对于这类产品的OCR识别问题也是用户的刚需,因此我建议添加该功能。
使用NABCD模型分析:
Need:用户有对于图像标注的需求。(可能没有PDF模板)
Approach:类似于阿里云的标注模式,采用锚点+选框的模式进行选择。
Benefit:解决了用户对于图像标注的需求。同时,可能能够提升模型对图像预测的准确度。
Competitors:阿里云已经有类似的标注模式。但是假如图像标注后,本平台支持的数据格式将更加丰富,有利于提升竞争力。
Delivery:首先发展toB业务,吸引大型企业、机构入驻。可以考虑提供融入office套件等广泛应用的软件。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号