Spark RDD和DataSet与DataFrame转换成RDD
Spark RDD和DataSet与DataFrame转换成RDD
一、什么是RDD
RDD是弹性分布式数据集(resilient distributed dataset) 的简称,是一个可以参与并行操作并且可容错的元素集合。什么是并行操作呢?例如,对于一个含4个元素的数组Array,元素分别为1,2,3,4。如果现在想将数组的每个元素放大两倍,Java实现通常是遍历数组的每个元素,然后每个元素乘以2,数组中的每个元素操作是有先后顺序的。但是在Spark中,可以将数组转换成一个RDD分布式数据集,然后同时操作每个元素。
二、创建RDD
Spark中提供了两种方式创建RDD
首先执行
![]()
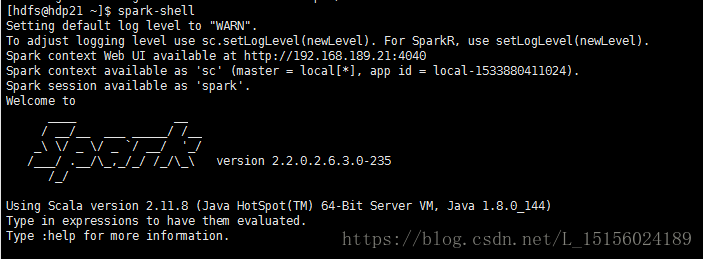
我们使用的HDP集成好的Spark,可以自己安装Apache Spark。
1、并行化一个存在的数据集
例如:将一个数组Array转换成一个RDD,如图:
val data = Array(1, 2, 3, 4, 5)
val distData = sc.parallelize(data)
在命令窗口执行上述命令后,如图:
![]()
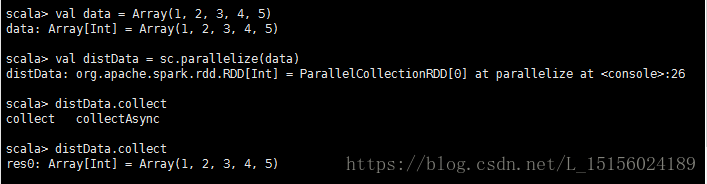
parallesize函数提供了两个参数,第二个参数表示RDD的分区数(partiton number),例如:
scala> val distDataP = sc.parallelize(data,3) distDataP: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at parallelize at <console>:26 scala>
将数组转换成一个分区数为3的RDD,例如第一个分区中元素为{1,2},第二分区中元素为{3,4},第三个分区中元素为{5}。
2、从外部存储系统引用一个数据集
外部存储如共享文件系统,HDFS文件系统,HBase,或者其他提供Hadoop文件格式的数据源等。例如,我们从HDFS文件系统/input/mahout-demo/目录下读取一个文件itemdata.data,将内容变成一个RDD,如图:![]()
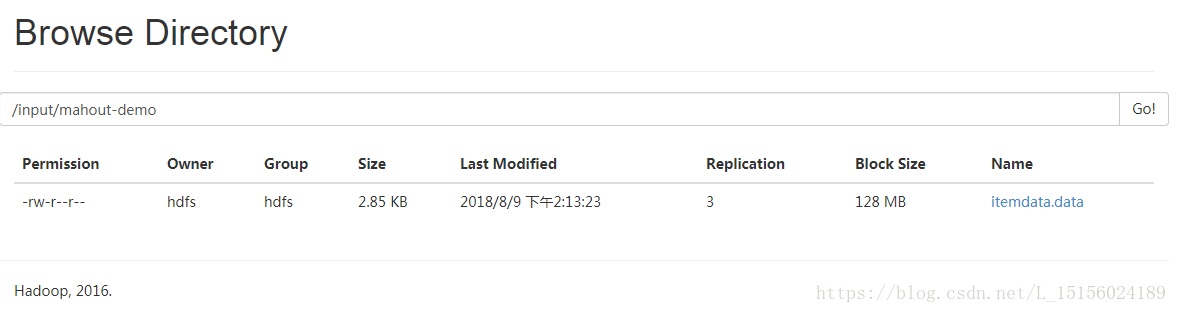
在命令行中执行命令,如图:
1 scala> val fileRDD = sc.textFile("hdfs://192.168.189.21:8020/input/mahout-demo/itemdata.data")
3、Idea开发工具创建RDD
当然上面提供的是使用Spark自带的Scala终端命令行来创建RDD的,我们也可以通过开发工具(比如Idea)来完成上面两个创建方式。
(1)pom.xml导入spark包
我们使用的Scala版本号是2.11,spark版本号是2.3.0,hadoop版本号2.7.3,这都是比较稳定和常用的版本,如下:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.leboop</groupId> <artifactId>mahout</artifactId> <version>1.0-SNAPSHOT</version> <properties> <!-- scala版本号 --> <scala.version>2.11</scala.version> <!-- spark版本号 --> <spark.version>2.3.0</spark.version> <!-- hadoop版本 --> <hadoop.version>2.7.3</hadoop.version> </properties> <dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.version}</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> </dependency> </dependencies> </project>
(2)程序
1 package com.leboop.rdd 2 3 import org.apache.spark.{SparkConf, SparkContext} 4 5 /** 6 * RDD创建Demo 7 */ 8 object RDDDemo { 9 def main(args: Array[String]): Unit = { 10 //spark配置 11 val sparkConf = new SparkConf().setAppName("rdd-demo").setMaster("local") 12 //创建sc对象 13 val sc = new SparkContext(sparkConf) 14 //数组 15 val data = Array(1, 2, 3, 4, 5) 16 //将数组变成RDD数据集,分区数为4 17 val rdd = sc.parallelize(data, 4) 18 //从HDFS文件系统读取文件,转换成一个RDD分布式数据集 19 val fileRDD = sc.textFile("hdfs://192.168.189.21:8020/input/mahout-demo/itemdata.data") 20 //打印前3个元素 21 rdd.take(3).foreach(println) 22 fileRDD.take(3).foreach(println) 23 } 24 }
执行程序,删除一些日志输出,部分结果如下:
1 1 2 2 3 3 4 0162381440670851711,4,7.0 5 0162381440670851711,11,4.0 6 0162381440670851711,32,1.0 7 8 Process finished with exit code 0
4、DataFrame转换成RDD
5、DataSet转换成RDD
1 package com.leboop.rdd
三、RDD算子
RDD支持两种类型的算子,一个称为变换(transformations),另一个称为动作(actions)。
1、变换
最典型的变换就是map函数,他将RDD的每一个元素通过一些函数计算变成的一个新的元素组成的RDD,如图:
![]()
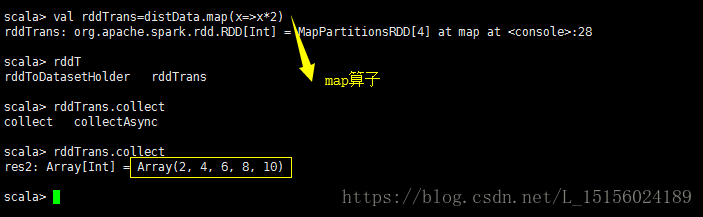
map函数将上面创建的distData的每一个元素变成了原来的2倍。
变换算子是懒惰的(lazy),它们不会立即计算,只是记忆下这个变换,当一个动作(action)作用于它时,才会触发计算,例如这里的collect函数。
2、动作
最典型的动作就是reduce,我们知道上面创建好的fileRDD,从HDFS文件系统中读取了一个文件,fileRDD的每一个元素存储了文件的每一行内容,我们使用reduce计算文件的内容总长度。分两个步骤:
(1)计算每一行的内容长度
使用转换算子map,将fileRDD的每一行内容映射成一个新的RDD,叫做lineLengths,这个RDD的每个元素存储的是文件每一行的内容长度。map属于转换算子,不会立即触发计算。
(2)累加每一行内容长度,计算出文件的内容总长度
使用action算子reduce,累加lineLengths算子的每个元素,得到最终结果。如图:
![]()

计算结果为2722。
四、RDD缓存
事实上,上面我们在计算文件内容总长度时,存在一个效率问题。因为map转换是懒惰的(lazy),每次执行reduce,都会重新计算一次map,如果数据量数以亿计,效率是十分低的。所以,我们想是否可以执行map转换后,将结果保存下来,然后执行reduce动作时,不会再重新计算map。答案是肯定的。我们使用persist或cache方法,将计算结果保存在内存中。如:
1 lineLengths.persist()
![]()
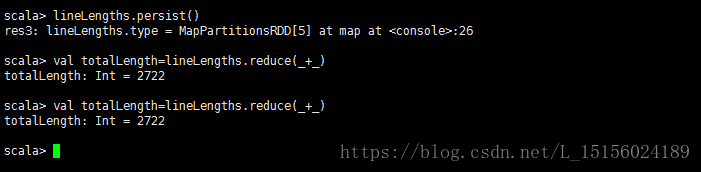
我们在reduce之前加入了缓存,第一个reduce触发map计算,并计算得到结果,map计算结果会保存在内存中,第二个reduce计算时,不会再触发map重新计算,而是直接使用内存中保存的结果参与reduce计算。
五、RDD算子列表
1、Transformations
The following table lists some of the common transformations supported by Spark. Refer to the RDD API doc (Scala, Java, Python, R) and pair RDD functions doc (Scala, Java) for details.
2、Actions
The following table lists some of the common actions supported by Spark. Refer to the RDD API doc (Scala, Java, Python, R)
and pair RDD functions doc (Scala, Java) for details.
| Action | Meaning |
|---|---|
| reduce(func) | Aggregate the elements of the dataset using a function func (which takes two arguments and returns one). The function should be commutative and associative so that it can be computed correctly in parallel. |
| collect() | Return all the elements of the dataset as an array at the driver program. This is usually useful after a filter or other operation that returns a sufficiently small subset of the data. |
| count() | Return the number of elements in the dataset. |
| first() | Return the first element of the dataset (similar to take(1)). |
| take(n) | Return an array with the first n elements of the dataset. |
| takeSample(withReplacement, num, [seed]) | Return an array with a random sample of num elements of the dataset, with or without replacement, optionally pre-specifying a random number generator seed. |
| takeOrdered(n, [ordering]) | Return the first n elements of the RDD using either their natural order or a custom comparator. |
| saveAsTextFile(path) | Write the elements of the dataset as a text file (or set of text files) in a given directory in the local filesystem, HDFS or any other Hadoop-supported file system. Spark will call toString on each element to convert it to a line of text in the file. |
| saveAsSequenceFile(path) (Java and Scala) |
Write the elements of the dataset as a Hadoop SequenceFile in a given path in the local filesystem, HDFS or any other Hadoop-supported file system. This is available on RDDs of key-value pairs that implement Hadoop's Writable interface. In Scala, it is also available on types that are implicitly convertible to Writable (Spark includes conversions for basic types like Int, Double, String, etc). |
| saveAsObjectFile(path) (Java and Scala) |
Write the elements of the dataset in a simple format using Java serialization, which can then be loaded usingSparkContext.objectFile(). |
| countByKey() | Only available on RDDs of type (K, V). Returns a hashmap of (K, Int) pairs with the count of each key. |
| foreach(func) | Run a function func on each element of the dataset. This is usually done for side effects such as updating an Accumulator or interacting with external storage systems. Note: modifying variables other than Accumulators outside of the foreach() may result in undefined behavior. See Understanding closures for more details. |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号