
apache 大数据平台搭建(hive)
一.官网下载安装包
https://hive.apache.org/
由于hive-3.1.2默认支持的时spark2.4.3的版本,我们后面需要安装spark3.0.0
所以需要重新编译,可留言获取安装包
编译步骤:官网下载 Hive3.1.2 源码,修改 pom 文件中引用的 Spark 版本为 3.0.0,如果
编译通过,直接打包获取 jar 包。如果报错,就根据提示,修改相关方法,直到不报错,打
包获取 jar 包。
二.安装
- 将编译后的hive安装包上传服务器
#在安装包所在路径执行解压命令:
tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /opt/module
- 修改配置文件
cd /opt/module/hive-3.1.2/conf
vim hive-site.xml
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop101:3306/metastore?useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>yourpassword</value>
</property>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop101</value>
</property>
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
<!--Spark依赖位置(注意:端口号8020必须和namenode的端口号一致)-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://hadoop101:8020/spark-jars/*</value>
</property>
<!--Hive执行引擎-->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
<!--Hive和Spark连接超时时间-->
<property>
<name>hive.spark.client.connect.timeout</name>
<value>10000ms</value>
</property>
</configuration>
三.启动hive
- 初始化元数据库
登录mysql,创建元数据库
create database metastore;
-
进入hive bin目录,执行初始化
schematool -initSchema -dbType mysql -verbose -
启动hadoop之后,执行hive命令,进入hive客户端命令行
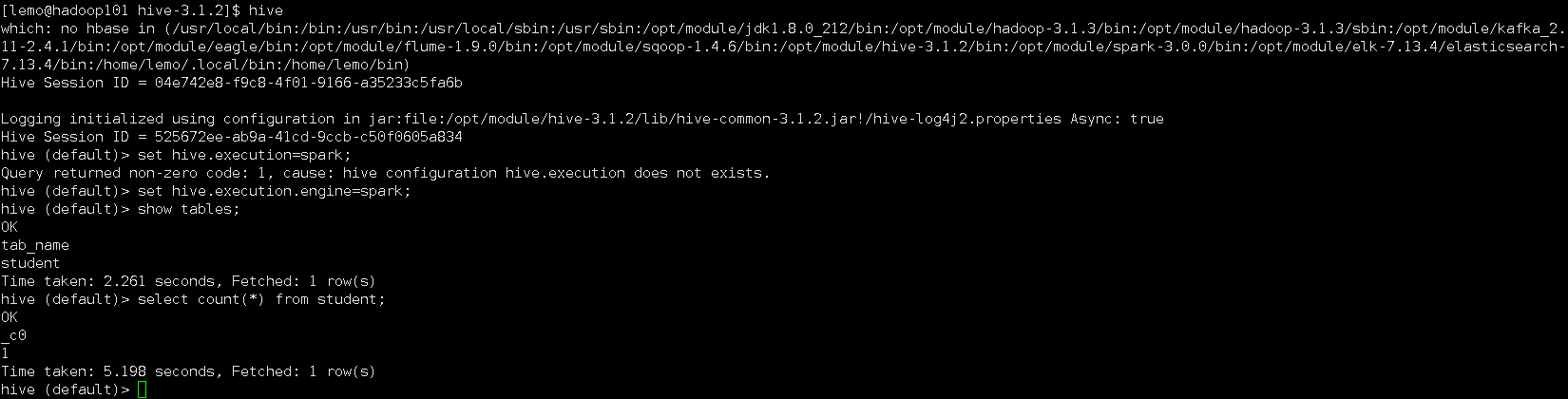
-
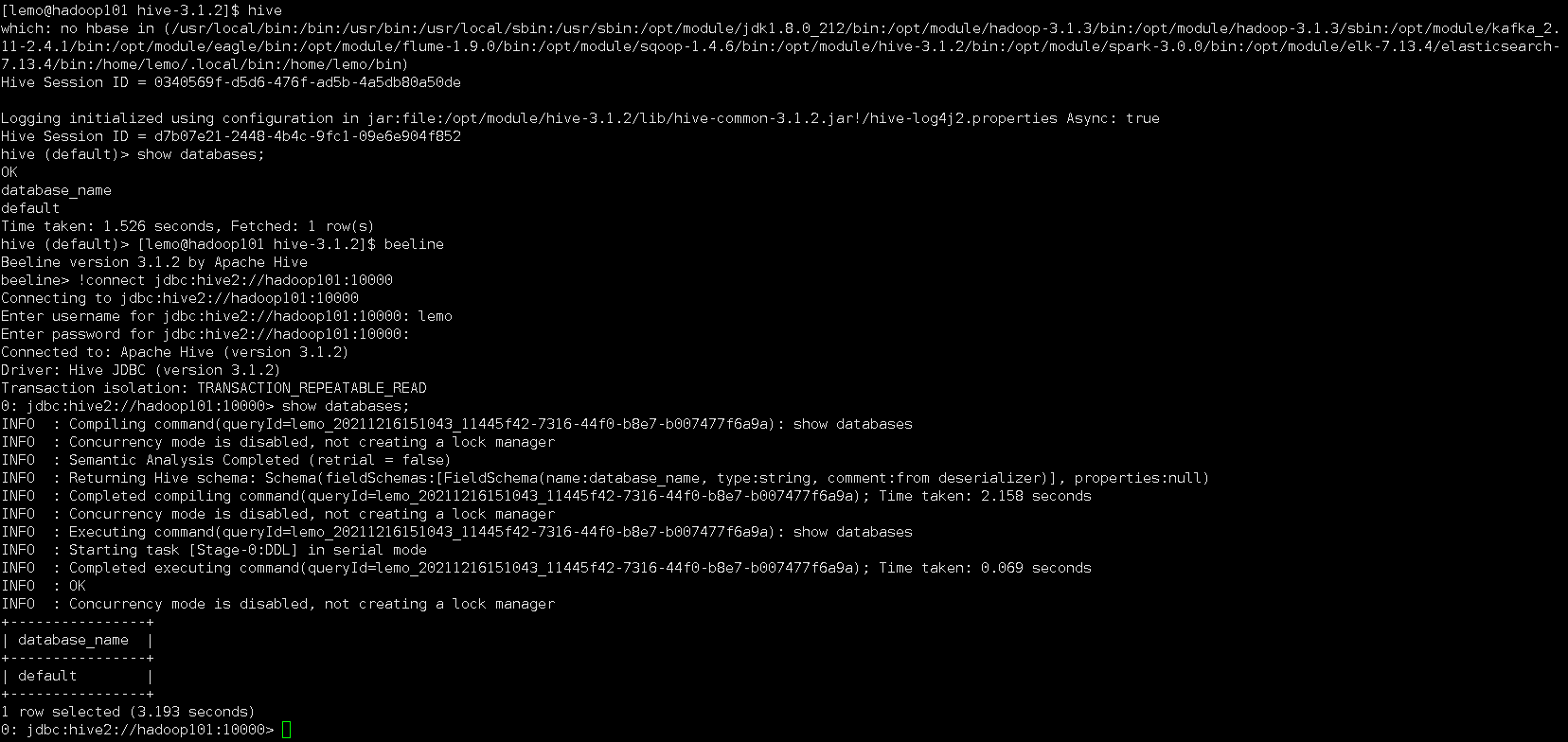
元数据方式访问hive和jdbc方式访问hive
在 hive-site.xml 文件中添加如下配置信息:
<!-- 指定存储元数据要连接的地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop101:9083</value>
</property>
<!-- 指定 hiveserver2 连接的 host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop101</value>
</property>
<!-- 指定 hiveserver2 连接的端口号 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property>
配置好后启动metastore和hiveserver2服务:
hive --service metastore
hive --service hiveserver2
hive bin目录下hive命令就是通过元数据方式访问,beeline命令是通过jdbc方式访问
- 配置hive脚本
#!/bin/bash
HIVE_LOG_DIR=$HIVE_HOME/logs
case $1 in
"start")
echo ' ---------- start metastore ---------- '
nohup /opt/module/hive-3.1.2/bin/hive --service metastore >> $HIVE_LOG_DIR/metastore.log 2>&1 &
sleep 2
echo ' ---------- start hiveserver2 ---------- '
nohup /opt/module/hive-3.1.2/bin/hive --service hiveserver2 >> $HIVE_LOG_DIR/hiveserver2.log 2>&1 &
;;
"stop")
echo ' ---------- stop hiveserver2 ---------- '
kill -9 $(jps -m | grep 'HiveServer2' | awk 'NR==1{print $1}')
echo ' ---------- stop metastore ---------- '
kill -9 $(jps -m | grep 'HiveMetaStore' | awk 'NR==1{print $1}')
;;
*)
echo Invalid Args!
echo 'Usage: '$(basename $0)' start|stop'
;;
esac
启停hive:
hive.sh start
hive.sh stop
四.配置hive on spark
# 1. 在 hive 中创建 spark 配置文件
vim /opt/module/hive/conf/spark-defaults.conf
#添加以下内容
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop101:8020/spark-history
spark.executor.memory 1g
spark.driver.memory 1g
# 2. 在 HDFS 创建如下路径,用于存储历史日志
hadoop fs -mkdir /spark-history
# 3. 向 HDFS 上传 Spark 纯净版 jar 包
tar -zxvf /opt/software/spark-3.0.0-bin-without-hadoop.tgz
hadoop fs -mkdir /spark-jars
hadoop fs -put spark-3.0.0-bin-without-hadoop/jars/* /spark-jars
# 4. 修改hive-site.xml文件
#添加如下内容
<!--Spark 依赖位置(注意:端口号 8020 必须和 namenode 的端口号一致)-->
<property>
<name>spark.yarn.jars</name>
<value>hdfs://hadoop101:8020/spark-jars/*</value>
</property>
<!--Hive 执行引擎-->
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
<!--Hive 和 Spark 连接超时时间-->
<property>
<name>hive.spark.client.connect.timeout</name>
<value>10000ms</value>
</property>
至此,hive on spark配置完成.后面再补充hive on tez.
每个人都在奋不顾身,都在加倍努力,得过且过只会让你和别人的差距越来越大...
