

elk集群搭建-7.13.4版本
1.准备安装包
官网下载即可:

2.配置环境
2.1. 修改用户最大进程数和文件句柄数
vim /etc/security/limits.conf
#添加以下内容
* hard nproc 65536
* soft nproc 120000
* hard nofile 65536
* soft nofile 120000
#保存退出
2.2. 修改虚拟内存
sudo vim /etc/sysctl.conf
#添加以下内容
vm.max_map_count=655360
保存退出后执行以下命令:
sudo sysctl -p
3.开始安装
3.1 安装es
在hadoop103上解压es安装包
-
创建elk文件夹
mkdir -p /ope/module/elk-7.13.4 -
解压
tar -zxvf /opt/software/elk/elasticsearch-7.13.4-linux-x86_64.tar.gz -C /ope/module/elk-7.13.4
- 修改配置
cd /opt/module/elk-7.13.4/elasticsearch-7.13.4
vim config/elasticsearch.yml
#修改一下内容
# ---------------------------------- Cluster -----------------------------------
cluster.name: elk
# ------------------------------------ Node ------------------------------------
node.name: hadoop103
node.master: true
node.data: true
# ----------------------------------- Paths ------------------------------------
path.data: /opt/module/elk-7.13.4/elasticsearch-7.13.4/data
path.logs: /opt/module/elk-7.13.4/elasticsearch-7.13.4/logs
# ---------------------------------- Network -----------------------------------
network.host: hadoop103
http.port: 9200
transport.tcp.port: 9300
# --------------------------------- Discovery ----------------------------------
discovery.seed_hosts: ["hadoop101", "hadoop102","hadoop103"]
cluster.initial_master_nodes: [ "hadoop102","hadoop103"]
- 分发到其他节点
scp -r /opt/module/elk-7.13.4 lemo@hadoop101:/opt/module/
scp -r /opt/module/elk-7.13.4 lemo@hadoop102:/opt/module/
#修改另外两台的配置文件
hadoop101上修改:
node.name: hadoop101
node.master: false
network.host: hadoop101
hadoop102上修改:
node.name: hadoop102
network.host: hadoop102
- 启动es集群
配置一键启停脚本
vim es.sh
chmod u+x es.sh
#!/bin/bash
case $1 in
"start"){
for es in hadoop101 hadoop102 hadoop103
do
ssh -T $es <<EOF
/opt/module/elk-7.13.4/elasticsearch-7.13.4/bin/elasticsearch -d >> /dev/null
EOF
yes | command
echo 从节点 $es 启动elasticsearch...[ done ]
sleep 1
done
};;
"stop"){
for es in hadoop101 hadoop102 hadoop103
do
ssh -T $es <<EOF
source /etc/profile.d/my_env.sh
ps aux |grep elasticsearch |grep -v grep |awk '{print \$2}' |xargs kill -9
EOF
echo 从节点 $es 停止elasticsearch...[ done ]
sleep 1
done
};;
"status"){
echo ---------- es 状态 ------------
curl http://hadoop103:9200/_cat/health?v
};;
esac
3.2 安装logstash
- 解压logstash
进入logstash安装包所在目录,执行解压命令:
tar -zxvf logstash-7.13.4-linux-x86_64.tar.gz -C /opt/module/elk-7.13.4/
- 修改logstash配置
vim /opt/module/logstash-7.13.4/config/logstash.yml

- 分发并修改配置文件http.host
3.3 安装kibana
- 解压kibana
tar -zxvf kibana-7.13.4-linux-x86_64.tar.gz -C /opt/module/elk-7.13.4/
- 修改配置文件
cd /opt/module/elk-7.13.4/kibana-7.13.4-linux-x86_64/config
vim kibana.yml
#添加以下内容:
server.port: 5601
server.host: "hadoop103"
server.name: "lemo-elk"
elasticsearch.hosts: ["http://hadoop101:9200","http://hadoop102:9200","http://hadoop103:9200"]
i18n.locale: "zh-CN"
- 启动kibana
cd /opt/module/elk-7.13.4/kibana-7.13.4-linux-x86_64/bin
nohup ./kibana >> /dev/null &
查看kibana界面:
4.测试elk
简单通过kafka控制台生产消费的方式将数据接入es,并通过kibana查看日志
启动zookeeper,kafka
创建一个topic用于测试
kafka-topics.sh --bootstrap-server hadoop101:9092 --create --topic first
#启动一个控制台生产者用于生产数据
kafka-console-producer.sh --bootstrap-server hadoop101:9092 --topic first
配置logstash
cd /opt/module/elk-7.13.4/logstash-7.13.4/
mkdir conf
vim conf/kafka_to_es.conf
#添加以下内容
input{
kafka {
bootstrap_servers => "hadoop101:9092,hadoop102:9092,hadoop103:9092"
client_id => "test"
group_id => "test"
topics => ["first"]
auto_offset_reset => "earliest"
auto_commit_interval_ms => "1000"
decorate_events => true
}
}
filter{
grok {
match => {
"message" => "(?<field1>datatype.*)"
}
}
kv {
source => "field1"
field_split => " "
value_split => "="
}
}
output{
elasticsearch {
hosts => ["hadoop101:9200","hadoop102:9200","hadoop103:9200"]
index => "test-%{+YYYY.MM.dd}"
}
}
#保存退出后启动logstash
./bin/logstash -f conf/kafka_to_es.conf
然后在kafka生产者控制台输入数据
qtAlert[72] datatype="system_audit" datatime="1639366113" action="add" type="monitor" comid="425356584254583" id="de1de7e3e2445cf5874" event_type="check" event_name="Linux-风险发现-风险总览-查看概览信息" event_src="console" os="linux" func="风险发现" subfunc="风险总览" src_ip="xxx.xx.xxx.xx" region="局域网" req_id="1f3bcaf270a743f6bc9b038e8c9c71f5" user_name="admin@lemo.com/xxx" user_type="子帐号" return_code="200" error_info=""
进入kibana界面
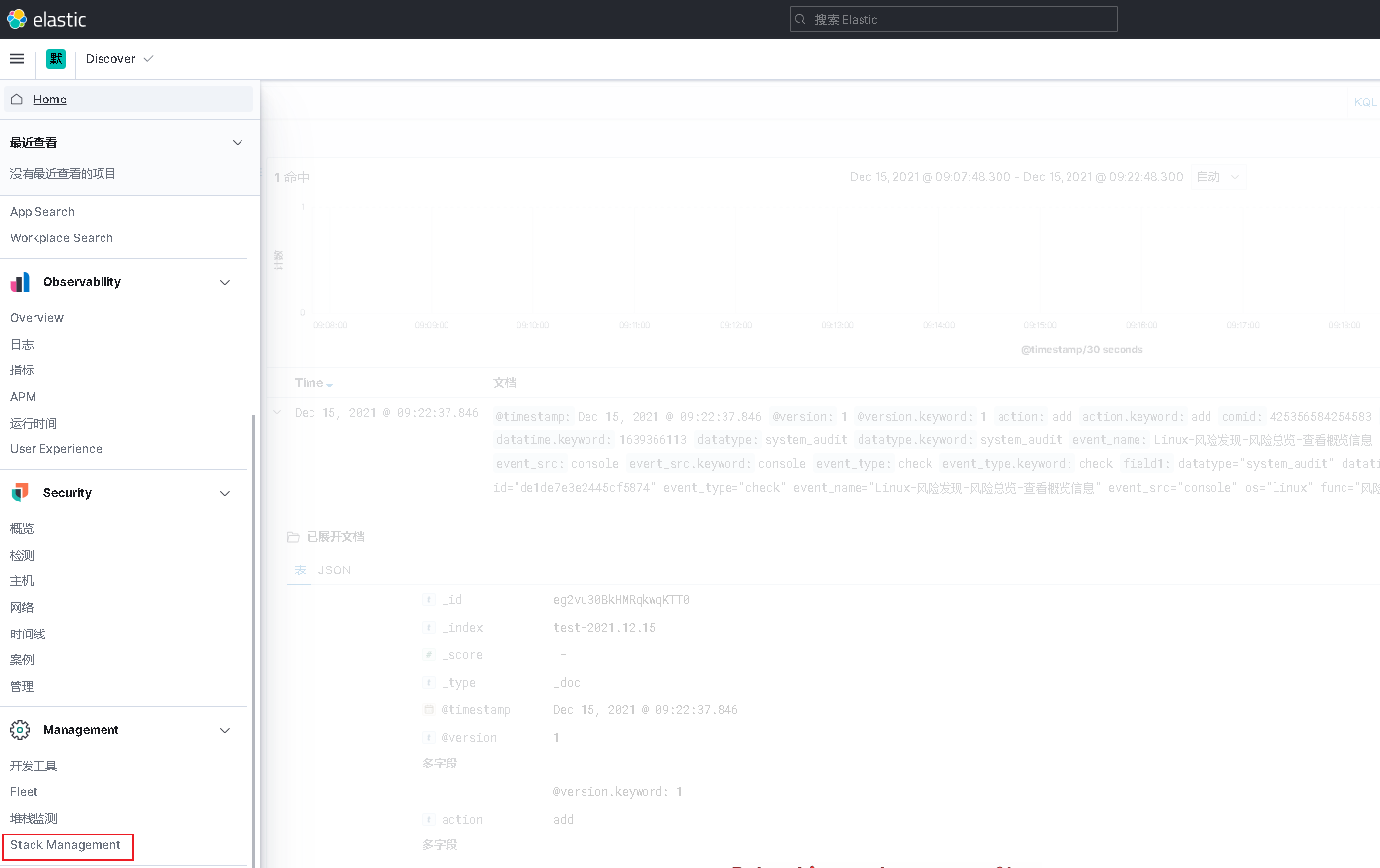
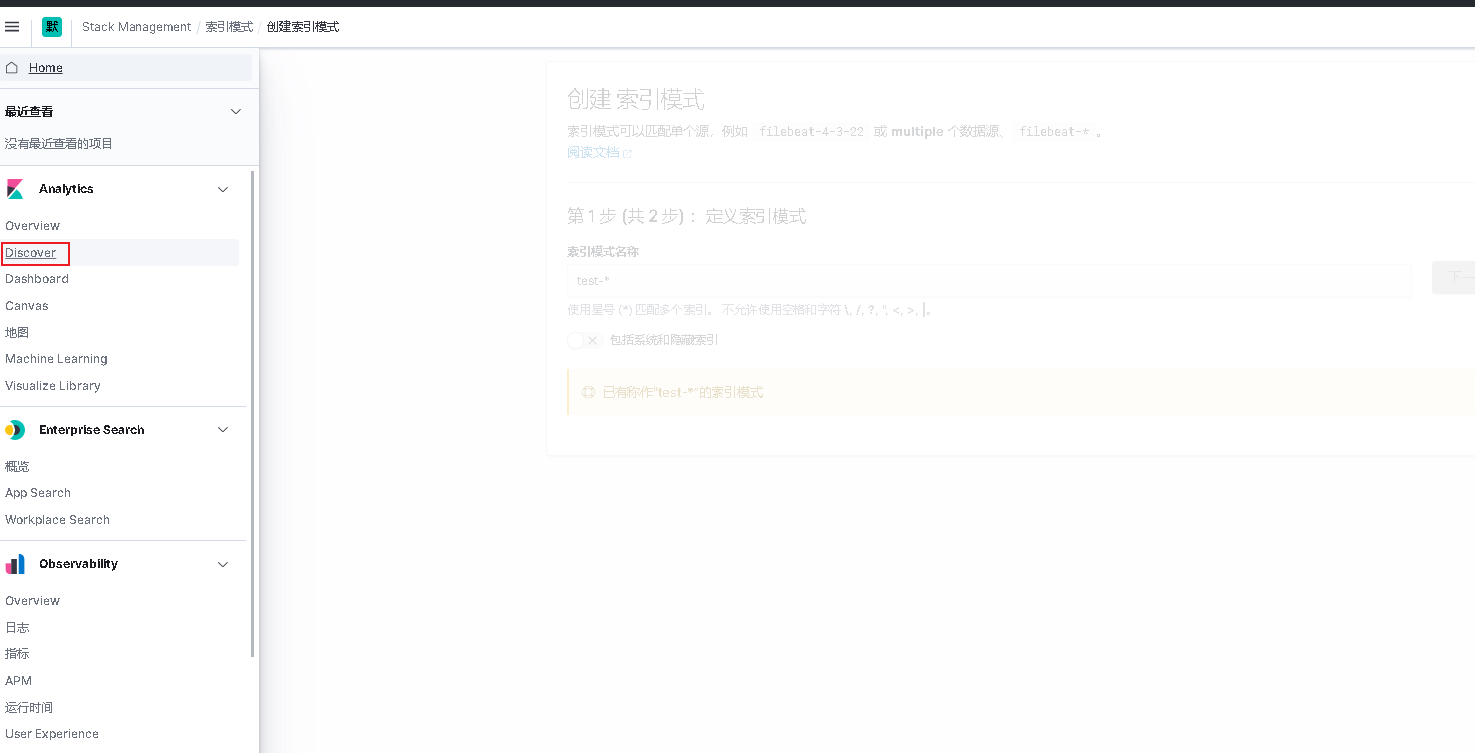
点击索引模式,创建索引模式并保存

点击discover
选择刚刚创建的索引模式,就可以查看到刚刚生成的数据了
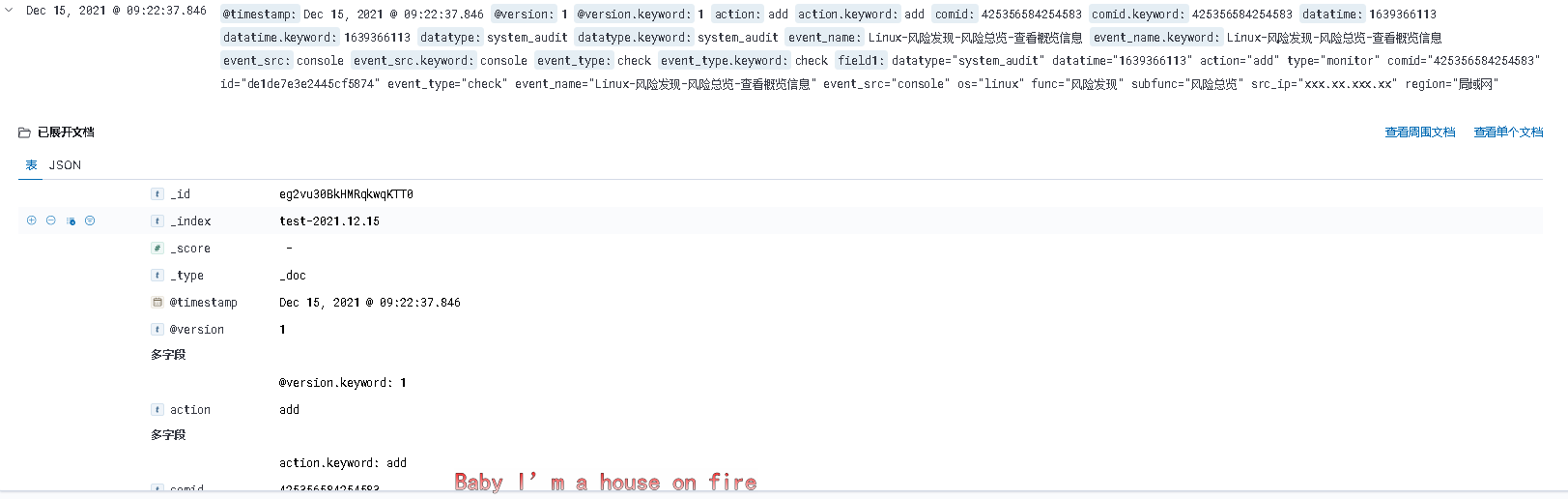

可以看到日志已经按照logstash中配置的规则进行了字段切分.
总结:
- 重点需要掌握logstash对不同格式的日志进行切分,常用filter插件的使用
- es优化
- kibana可视化分析,图表制作
每个人都在奋不顾身,都在加倍努力,得过且过只会让你和别人的差距越来越大...
