

apache 大数据平台搭建(hadoop)
一.机器准备
准备三台虚拟机,配置如下
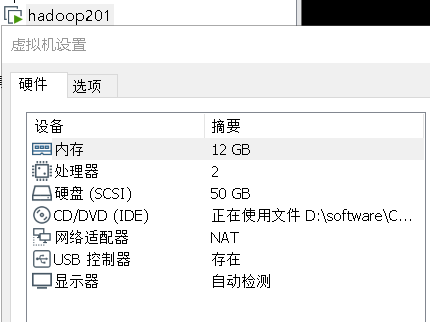
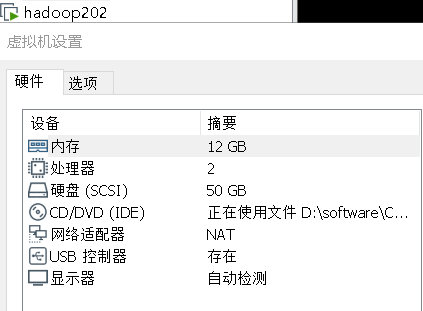
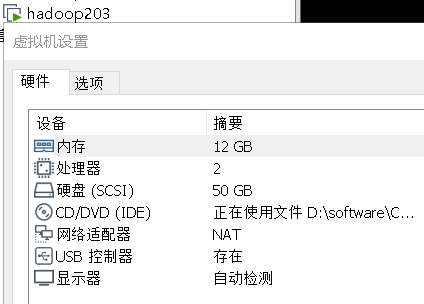
二.安装hadoop生态各软件
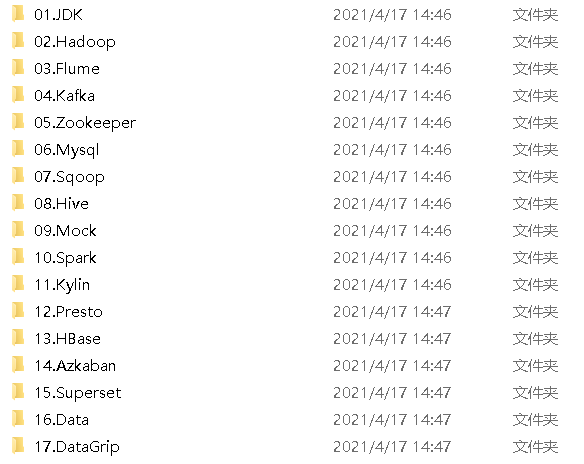
1.准备安装包
1.1 linux预配置及优化
1.1.1 添加普通用户及添加sudo权限
#添加用户
useradd lemo
#设置密码
passwd lemo
#切换root用户,添加sudo权限
vim /etc/sudoers
%wheel ALL=(ALL) ALL
lemo ALL=(ALL) NOPASSWD: ALL(添加这一行内容)
1.1.2 配置文件句柄和最大进程
sudo vim /etc/security/limits.conf
sudo vim /etc/security/limits.d/20-nproc.conf
* hard nproc 65536
* soft nproc 120000
* hard nofile 65536
* soft nofile 120000
1.2 初始环境准备
1.2.1 修改主机名和hosts文件
修改主机名:
hostnamectl set-hostname hadoop101
hostnamectl set-hostname hadoop102
hostnamectl set-hostname hadoop103
vim /etc/hosts
192.168.127.101 hadoop101
192.168.127.102 hadoop102
192.168.127.103 hadoop103
1.2.2 配置免密(root和lemo用户我都配了)
hadoop01上执行:
ssh-keygen -t rsa
4下回车后执行:
ssh-copy-id hadoop101
ssh-copy-id hadoop102
ssh-copy-id hadoop103
按提示输入lemo@hadoop102的密码
执行ssh hadoop102测试
root用户配置过程一样.
1.2.3 编写批量执行脚本及分发脚本
- 批量执行脚本
vim /home/lemo/bin/xcall.sh
#! /bin/bash
# 添加以下内容:
for i in hadoop101 hadoop102 hadoop103
do
echo --------- $i ----------
ssh $i "$*"
done
- 分发脚本
先安装rsync
sudo yum install rsync -y
vim /home/lemo/bin/xsync.sh
#添加以下内容
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop101 hadoop102 hadoop103
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
1.2.4 关闭防火墙
systemctl stop(disable) firewalld
1.2.5 配置时间同步
ntp时间同步这里就不作详细配置
2.开始安装
2.1 安装jdk
将准备好的安装包放到/opt/software文件夹中并创建/opt/module文件夹
解压:
sudo tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/
配置环境变量
sudo vim /etc/profile.d/my_env.sh
添加以下内容:
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
生效配置文件:
source /etc/profile.d/my_env.sh
另外两个节点创建文件夹(lemo用户)
mkdir /opt/module
root执行分发脚本:分发jdk和my_env.sh
进入/home/lemo/bin执行:
./xsync.sh /opt/module/jdk1.8.0_212
./xsync.sh /etc/profile.d/my_env.sh
./xcall.sh "source /etc/profile.d/my_env.sh"
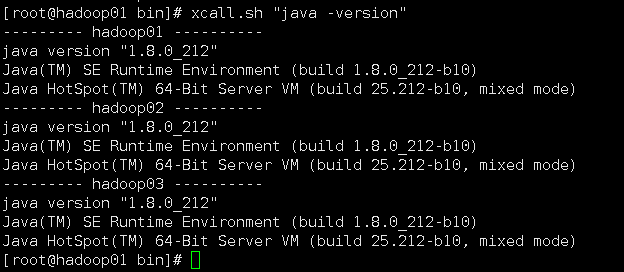
2.2 安装mysql
1.卸载已有mysql

这里报错了,我这里强制卸载,rpm -e --nodeps
然后执行了安装命令

查看是否安装成功
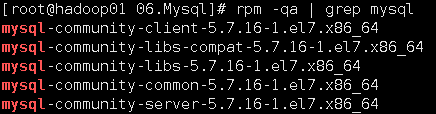
更改密码,查看mysql日志,可以看到初始密码

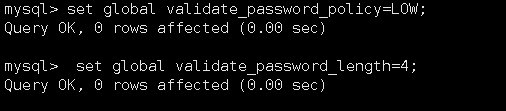
修改密码安全等级
set global validate_password_policy=LOW;
set global validate_password_length=4;
重置root密码:
set password for root@localhost=password('root');
开启远程连接:
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'root' WITH GRANT OPTION;
#如果你想允许用户myuser从ip为192.168.1.64的主机连接到mysql服务器,并使用root作为密码
GRANT ALL PRIVILEGES ON *.* TO 'myuser'@'192.168.1.64' IDENTIFIED BY 'root' WITH GRANT OPTION;
FLUSH PRIVILEGES;
2.3 安装hadoop3.1.3
2.3.1 解压安装包
# 切换lemo用户
cd /opt/software/02.Hadoop
tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module
2.3.2 配置环境变量并分发配置文件
sudo vim /etc/profile.d/my_env.sh
添加以下内容:
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
保存退出,并分发配置文件
sudo /home/lemo/bin/xsync.sh /etc/profile.d/my_env.sh
生效配置文件:
source /etc/profile.d/my_env.sh
2.3.3 修改配置文件
- 修改core-site.xml
#configuration位置添加以下配置:
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-3.1.3/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为atguigu -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>lemo</value>
</property>
<!-- 配置该atguigu(superUser)允许通过代理访问的主机节点 -->
<property>
<name>hadoop.proxyuser.lemo.hosts</name>
<value>*</value>
</property>
<!-- 配置该atguigu(superUser)允许通过代理用户所属组 -->
<property>
<name>hadoop.proxyuser.lemo.groups</name>
<value>*</value>
</property>
<!-- 配置该atguigu(superUser)允许通过代理的用户-->
<property>
<name>hadoop.proxyuser.lemo.groups</name>
<value>*</value>
</property>
- 配置hdfs-site.xml
#configuration位置添加以下配置:
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>hadoop101:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop03:9868</value>
</property>
<!-- 测试环境指定HDFS副本的数量1,生产环境配置默认为3-->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
- 修改yarn-site.xml
#configuration位置添加以下配置:
<!-- Site specific YARN configuration properties -->
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定ResourceManager的地址-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop02</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<!-- yarn容器允许分配的最大最小内存 -->
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>512</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>4096</value>
</property>
<!-- yarn容器允许管理的物理内存大小 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!-- 关闭yarn对物理内存和虚拟内存的限制检查 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
- 修改mapred-site.xml
#configuration位置添加以下配置:
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
- 配置works
vim /opt/module/hadoop-3.1.3/etc/hadoop/workers
#删除localhost并添加以下内容:
hadoop01
hadoop02
hadoop03
2.3.4 配置历史服务器
修改mapred-site.xml文件
#添加以下内容:
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop101:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop101:19888</value>
</property>
2.3.5 配置日志聚集功能
修改yarn-site.xml文件
#添加以下内容:
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop101:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
2.3.6 分发hadoop
进入安装目录(/opt/module/),执行分发命令:
xsync.sh hadoop-3.1.3
2.3.7 初始化集群,格式化namenode
hdfs namenode -format

2.3.8 编辑一键启动脚本
vim ~/bin/hdp.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop101 "/opt/module/hadoop-3.1.3/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop101 "/opt/module/hadoop-3.1.3/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop101 "/opt/module/hadoop-3.1.3/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop102 "/opt/module/hadoop-3.1.3/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop101 "/opt/module/hadoop-3.1.3/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
添加脚本执行权限
chmod u+x ~/bin/hdp.sh
启动集群:
hdp.sh start
在搭建的时候遇到问题,要多查看日志,根据报错信息进行解决
坚持学习,不负韶华...
