
hadoop3.x新特性
hadoop3.x对比hadoop2.x新特性
以下只是我个人觉得关注度较高的几个新特性相关的介绍.
1. jdk
在Hadoop2时,可以使用JDK7,但是在Hadoop3中,最低版本要求是JDK8,所以低于JDK8的版本需要对JDK进行升级,方可安装使用Hadoop3
2. 引入纠删码(Erasure Encoding)
注:配置纠删码和异构存储需要一共 5 台或以上数据节点
HDFS 默认情况下,一个文件有 3 个副本,这样提高了数据的可靠性,但也带来了 2 倍的冗余开销。Hadoop3.x 引入了纠删码,采用计算的方式,可以节省约 50%左右的存储空间。
纠删码原理:
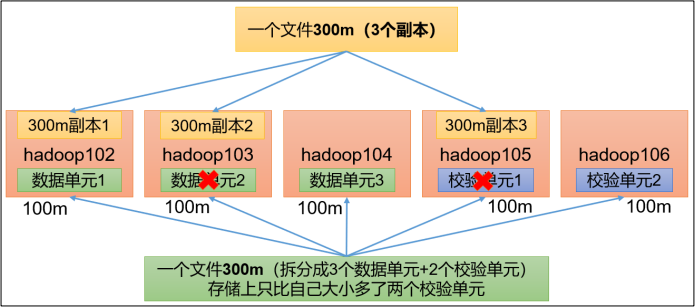
大概意思就是之前存300M文件,需要900M空间存储,采用Name=RS-3-2-1024k这个策略后将300M文件分为三个数据单元和两个校验单元存储,只需要获取五个单元中的任意三个单元就可以获得原始数据,存储空间占用500M,相比于之前的900M节约大约50%.
纠删码命令:hdfs ec
Usage: bin/hdfs ec [COMMAND]
[-listPolicies]
[-addPolicies -policyFile <file>]
[-getPolicy -path <path>]
[-removePolicy -policy <policy>]
[-setPolicy -path <path> [-policy <policy>] [-replicate]]
[-unsetPolicy -path <path>]
[-listCodecs]
[-enablePolicy -policy <policy>]
[-disablePolicy -policy <policy>]
[-help <command-name>].
查看策略:hdfs ec -listPolicies
Erasure Coding Policies:
ErasureCodingPolicy=[Name=RS-10-4-1024k, Schema=[ECSchema=[Codec=rs,
numDataUnits=10, numParityUnits=4]], CellSize=1048576, Id=5],
State=DISABLED
ErasureCodingPolicy=[Name=RS-3-2-1024k, Schema=[ECSchema=[Codec=rs,
numDataUnits=3, numParityUnits=2]], CellSize=1048576, Id=2],
State=DISABLED
ErasureCodingPolicy=[Name=RS-6-3-1024k, Schema=[ECSchema=[Codec=rs,
numDataUnits=6, numParityUnits=3]], CellSize=1048576, Id=1],
State=ENABLED
ErasureCodingPolicy=[Name=RS-LEGACY-6-3-1024k,
Schema=[ECSchema=[Codec=rs-legacy, numDataUnits=6, numParityUnits=3]],
CellSize=1048576, Id=3], State=DISABLED
ErasureCodingPolicy=[Name=XOR-2-1-1024k, Schema=[ECSchema=[Codec=xor,
numDataUnits=2, numParityUnits=1]], CellSize=1048576, Id=4],
State=DISABLED
RS-3-2-1024k:使用 RS 编码,每 3 个数据单元,生成 2 个校验单元,共 5 个单元,也就是说:这 5 个单元中,只要有任意的 3 个单元存在(不管是数据单元还是校验单元,只要总数=3),就可以得到原始数据。每个单元的大小是 1024k=1024*1024=1048576。
3. 集群数据均衡之磁盘间数据均衡
生产环境,由于硬盘空间不足,往往需要增加一块硬盘。刚加载的硬盘没有数据时,可
以执行磁盘数据均衡命令
(1)生成均衡计划(我们只有一块磁盘,不会生成计划)
hdfs diskbalancer -plan hadoop103
(2)执行均衡计划
hdfs diskbalancer -execute hadoop103.plan.json
(3)查看当前均衡任务的执行情况
hdfs diskbalancer -query hadoop103
(4)取消均衡任务
hdfs diskbalancer -cancel hadoop103.plan.json
4. 多namenode
相比于2.x hdfs高可用,在hadoop3.X中可以支持多个standby namenode在同一个集群中
5. yarn的时间线V.2服务
参考大佬博客:https://www.cnblogs.com/smartloli/p/8827623.html
引入YARN Timeline Service v.2是为了解决两个主要问题:
- 提高时间线服务的可伸缩性和可靠性;
- 通过引入流和聚合来增强可用性
5.1 伸缩性
YARN V1仅限于读写单个实例,不能很好的扩展到小集群之外。YARN V2使用了更具有伸缩性的分布式体系架构和可扩展的后端存储,它将数据的写入与数据的读取进行了分离。并使用分布式收集器,本质上是每个YARN应用的收集器。读则是独立的实例,专门通过REST API服务来查询
5.2 可用性
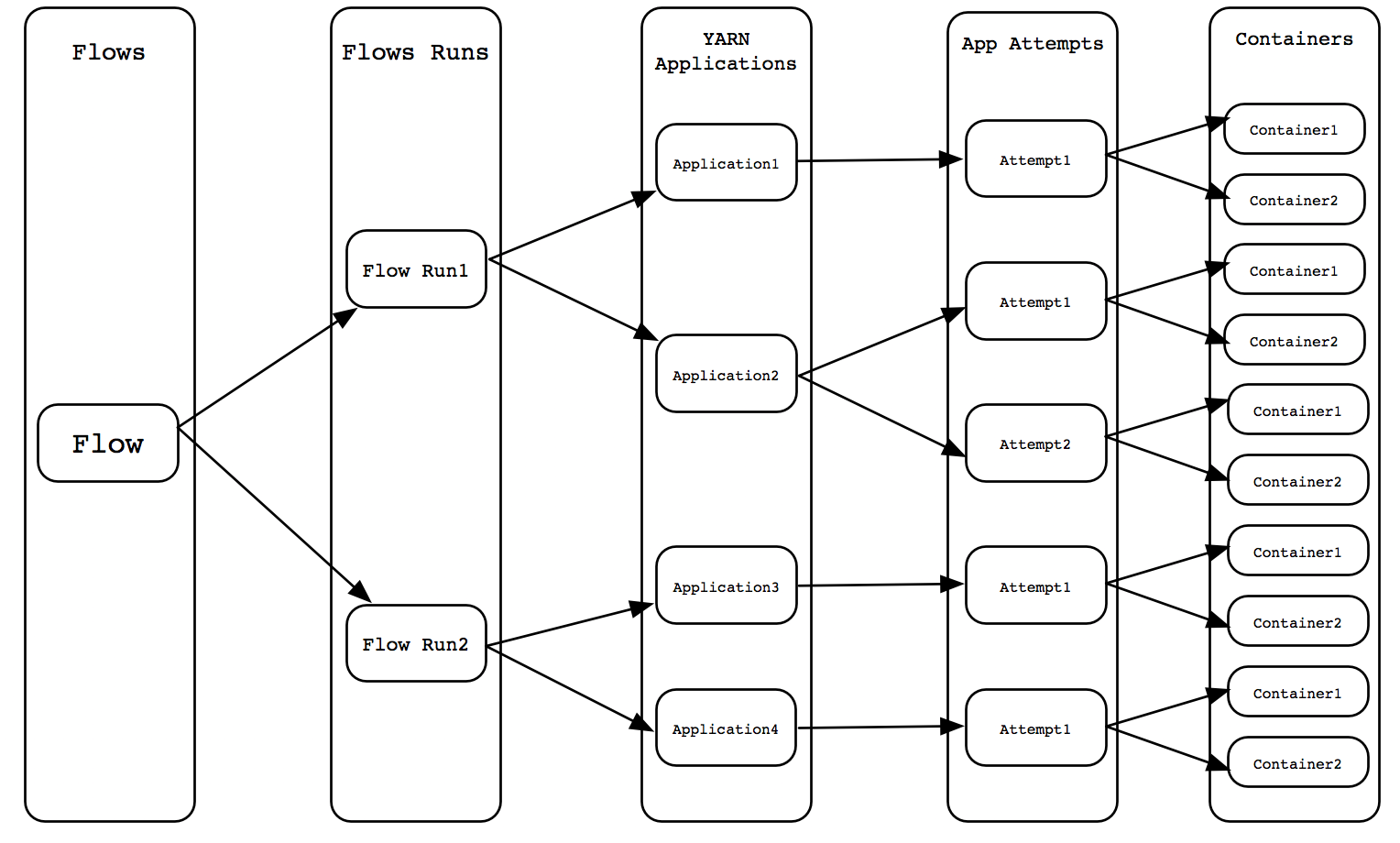
对于可用性的改进,在很多情况下,用户对流或者YARN应用的逻辑组的信息比较感兴趣。启动一组或者一系列的YARN应用程序来完成逻辑应用是很常见的。如下图所示:
架构体系
YARN时间线服务V2采用了一组收集器写数据到后端进行存储。收集器被分配并与它们专用的应用程序主机进行协作,如下图所示,属于该应用程序的所有数据都被发送到应用程序时间轴的收集器中,但是资源管理器时间轴收集器除外。
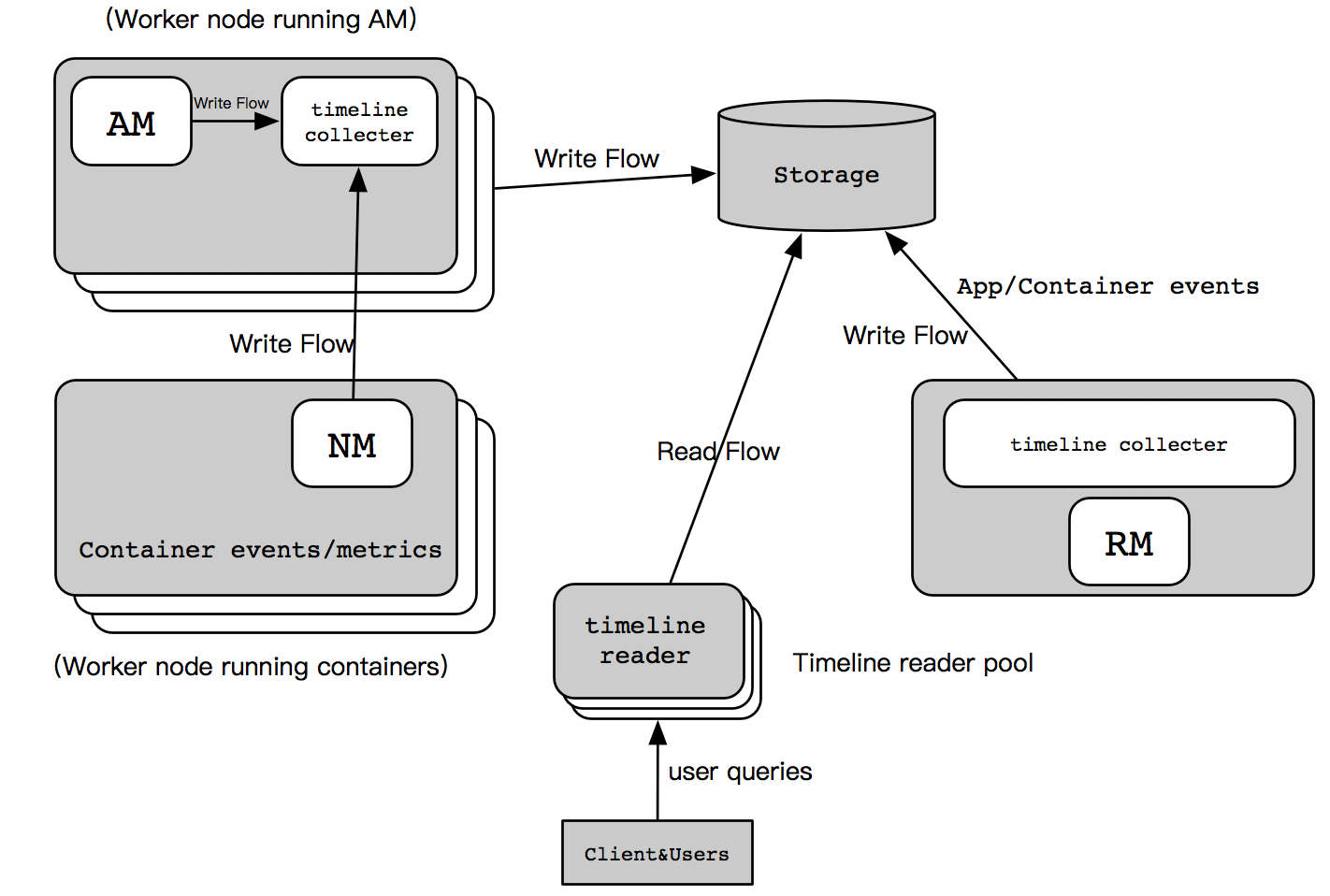
对于给定的应用程序,应用程序可以将数据写入同一时间轴收集器中。此外,为应用程序运行容器的其他节点的节点管理器,还会向运行应用程序主节点的时间轴收集器写入数据。资源管理器还维护自己的时间手机线收集器,它只发布YARN的通用生命周期事件,以保持其写入量合理。时间的读取器是单独的守护进程从收集器中分离出来的,它旨在服务于REST API查询操作。
