

作 者:聂秀英 张恒升 黎家力 罗忠
http://www.cww.net.cn/tech/html/2007/9/3/2007931432436821_1.htm
一、概述
音频信号数字化之后所面临的一个问题是巨大的数据量,这为存储和传输带来了压力。例如,对于CD音质的数字音频,所用的采样频率为44.1kHz,量化精度为16bit;采用双声道立体声时,其数码率约为1.41Mbit/s;1秒的CD立体声信号需要约176.4KB的存储空间。因此,为了降低传输或存储的费用,就必须对数字音频信号进行编码压缩。到目前为止,音频信号经压缩后的数码率降低到32至256kbit/s,语音低至8kbit/s以下,个别甚至到2kbit/s。
为使编码后的音频信息可以被广泛地使用,在进行音频信息编码时需要采用标准的算法。因而,需要对音频编码进行标准化。
二、音频编码技术和应用
2.1音频信号
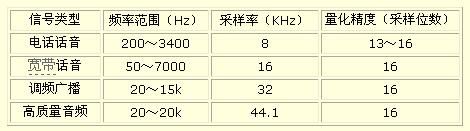
通常将人耳可以听到的频率在20Hz到20KHz的声波称为为音频信号。人的发音器官发出的声音频段在80Hz到3400Hz之间,人说话的信号频率在300到3000Hz,有的人将该频段的信号称为语音信号。在多媒体技术中,处理的主要是音频信号,它包括音乐、语音、风声、雨声、鸟叫声、机器声等。
表1 数字音频等级
2.2音频编码技术
对数字音频信息的压缩主要是依据音频信息自身的相关性以及人耳对音频信息的听觉冗余度。音频信息在编码技术中通常分成两类来处理,分别是语音和音乐,各自采用的技术有差异。现代声码器的一个重要的课题是,如何把语音和音乐的编码融合起来。
语音编码技术又分为三类:波形编码、参数编码以及混合编码。
波形编码:波形编码是在时域上进行处理,力图使重建的语音波形保持原始语音信号的形状,它将语音信号作为一般的波形信号来处理,具有适应能力强、话音质量好等优点,缺点是压缩比偏低。该类编码的技术主要有非线性量化技术、时域自适应差分编码和量化技术。非线性量化技术利用语音信号小幅度出现的概率大而大幅度出现的概率小的特点,通过为小信号分配小的量化阶,为大信号分配大的量阶来减少总量化误差。我们最常用的G.711标准用的就是这个技术。自适应差分编码是利用过去的语音来预测当前的语音,只对它们的差进行编码,从而大大减少了编码数据的动态范围,节省了码率。自适应量化技术是根据量化数据的动态范围来动态调整量阶,使得量阶与量化数据相匹配。G.726标准中应用了这两项技术,G.722标准把语音分成高低两个子带,然后在每个子带中分别应用这两项技术。
参数编码:利用语音信息产生的数学模型,提取语音信号的特征参量,并按照模型参数重构音频信号。它只能收敛到模型约束的最好质量上,力图使重建语音信号具有尽可能高的可懂性,而重建信号的波形与原始语音信号的波形相比可能会有相当大的差别。这种编码技术的优点是压缩比高,但重建音频信号的质量较差,自然度低,适用于窄带信道的语音通讯,如军事通讯、航空通讯等。美国的军方标准LPC-10,就是从语音信号中提取出来反射系数、增益、基音周期、清/浊音标志等参数进行编码的。MPEG-4标准中的HVXC声码器用的也是参数编码技术,当它在无声信号片段时,激励信号与在CELP时相似,都是通过一个码本索引和通过幅度信息描述;在发声信号片段时则应用了谐波综合,它是将基音和谐音的正弦振荡按照传输的基频进行综合。
混合编码:将上述两种编码方法结合起来,采用混合编码的方法,可以在较低的数码率上得到较高的音质。它的基本原理是合成分析法,将综合滤波器引入编码器,与分析器相结合,在编码器中将激励输入综合滤波器产生与译码器端完全一致的合成语音,然后将合成语音与原始语音相比较(波形编码思想),根据均方误差最小原则,求得最佳的激励信号,然后把激励信号以及分析出来的综合滤波器编码送给解码端。这种得到综合滤波器和最佳激励的过程称为分析(得到语音参数);用激励和综合滤波器合成语音的过程称为综合;由此我们可以看出CELP编码把参数编码和波形编码的优点结合在了一起,使得用较低码率产生较好的音质成为可能。通过设计不同的码本和码本搜索技术,产生了很多编码标准,目前我们通讯中用到的大多数语音编码器都采用了混合编码技术。例如在互联网上的G.723.1和G.729标准,在GSM上的EFR、HR标准,在3GPP2上的EVRC、QCELP标准,在3GPP上的AMR-NB/WB标准等等。
音乐的编码技术主要有自适应变换编码(频域编码)、心理声学模型和熵编码等技术。
自适应变换编码:利用正交变换,把时域音频信号变换到另一个域,由于去相关的结果,变换域系数的能量集中在一个较小的范围,所以对变换域系数最佳量化后,可以实现码率的压缩。理论上的最佳量化很难达到,通常采用自适应比特分配和自适应量化技术来对频域数据进行量化。在MPEGlayer3和AAC标准及DolbyAC-3标准中都使用了改进的余弦变换(MDCT);在ITUG.722.1标准中则用的是重叠调制变换(MLT)。本质上它们都是余弦变换的改进。
心理声学模型:其基本思想是对信息量加以压缩,同时使失真尽可能不被觉察出来,利用人耳的掩蔽效应就可以达到此目的,即较弱的声音会被同时存在的较强的声音所掩盖,使得人耳无法听到。在音频压缩编码中利用掩蔽效应,就可以通过给不同频率处的信号分量分配以不同的量化比特数的方法来控制量化噪声,使得噪声的能量低于掩蔽阈值,从而使得人耳感觉不到量化过程的存在。在MPEGlayer2、3和AAC标准及AC-3标准中都采用了心理声学模型,在目前的高质量音频标准中,心理声学模型是一个最有效的算法模型。
熵编码:根据信息论的原理,可以找到最佳数据压缩编码的方法,数据压缩的理论极限是信息熵。如果要求编码过程中不丢失信息量,即要求保存信息熵,这种信息保持编码叫熵编码,它是根据信息出现概率的分布特性而进行的,是一种无损数据压缩编码。常用的有霍夫曼编码和算术编码。在MPEGlayer1、2、3和AAC标准及ITUG.722.1标准中都使用了霍夫曼编码;在MPEG4BSAC工具中则使用了效率更高的算术编码。
2.3数字音频编码的主要应用
对数字音频信息的编码进行压缩的目的是在不影响人们使用的情况下使数字音频信息的数据量最少。通常用如下6个属性来衡量:
—比特率;
—主观/客观的语音质量;
—计算复杂度和对存储器的要求;
—延迟;
—对于通道误码的灵敏度;
—信号的带宽。
由于不同的应用,人们对数字音频信息的要求是不同的,并且在选择数字音频信息编码所采用的技术时也需要了解人们对音频信息的各种应用。目前数字音频信息处理技术主要应用于:
■消费电子类数字音响设备
CD唱机、数字磁带录音机(DAT)、MP3播放机以及MD(MiniDisc)唱机已经广泛地应用了数字音频技术。
■广播节目制作系统
在声音节目制作系统,如录音、声音处理加工、记录存储、非线性编辑等环节使用了数字调音台、数字音频工作站等数字音频设备。
■多媒体应用
在多媒体上的应用体现在VCD、DVD、多媒体计算机以及Internet。VCD采用MPEG-I编码格式记录声音和图像;DVD-Audio格式支持多种不同的编码方式和记录参数,可选的编码方式包括无损的MLP、DSD、DilbyAC-3、MPEG2-layer2Audio等,而且是可扩充的、开放的,并可以应用未来的编码技术:Internet上采用MP3的音频格式传输声音,以提高下载能力。
■广播电视数字化
在广播电视和数字音频广播系统中,声音编码采用MUSICAM编码方法,符合MPEG-1Layer1高级音频编码。如当今的数字电视采用的音频标准就是DilbyAC-3和MPEG-layer2。
■通讯系统
在通讯系统中,必须对音频进行压缩。传统的PSTN电话中采用的是G.711和G.726的标准;GSM移动通讯采用的是GSMHR/FR/EFR标准;CDMA移动通讯采用的是3GPP2EVRC、QCELP8k、QCELP16k、4GV标准;WCDMA第3代移动通讯采用的是3GPPAMR-NB、AMR-WB标准。另外在IPTV和移动流媒体中,采用的是AMR-WB+和AAC的标准。
总之,根据应用场合的不同可以将数字音频编码分为如下两种编码:
语音编码:针对语音信号进行的编码压缩,主要应用于实时语音通信中减少语音信号的数据量。典型的编码标准有ITU-TG.711、G.722、G.723.1、G.729;GSMHR、FR、EFR;3GPPAMR-NB、AMR-WB;3GPP2 QCELP8k、QCELP 13k、EVRC、4GV-NB等。
音频编码:针对频率范围较宽的音频信号进行的编码。主要应用于数字广播和数字电视广播、消费电子产品、音频信息的存储、下载等。典型的编码有MPEG1/MPEG2的layer1、2、3和MPEG 4 AAC的音频编码。还有最新的ITU-T G.722.1、3GPP AMR-WB+和3GPP 2 4GV-WB,它们在低码率上的音频表现也很不错。
三、音频编码标准发展现状
3.1语音编码标准发展现状
国际电信联盟(ITU)主要负责研究和制定与通信相关的标准,作为主要通信业务的电话通信业务中使用的语音编码标准均是由ITU负责完成的。其中用于固定网络电话业务使用的语音编码标准如ITU-TG.711等主要在ITU-TSG15完成,并广泛应用于全球的电话通信系统之中。目前,随着Internet网络及其应用的快速发展,在2005到2008研究期内,ITU-T将研究和制定变速率语音编码标准的工作转移到主要负责研究和制定多媒体通信系统、终端标准的SG 16中进行。
在欧洲、北美、中国和日本的电话网络中通用的语音编码器是8位对数量化器(相应于64Kb/s的比特率)。该量化器所采用的技术在1972年由CCITT(ITU-T的前身)标准化为G.711。
在1983年,CCIT规定了32Kb/s的语音编码标准G.721,其目标是在通用电话网络上的应用(标准修正后称为G.726)。这个编码器价格虽低但却提供了高质量的语音。
至于数字蜂窝电话的语音编码标准,在欧洲,TCH-HS是欧洲电信标准研究所(ETSI)的一部分,由他们负责制定数字蜂窝标准。在北美,这项工作是由电信工业联盟(TIA)负责执行。在日本,由无线系统开发和研究中心(称为RCR)组织这些标准化的工作。
此外,国际海事卫星协会(Inmarsat)是管理地球上同步通信卫星的组织,也已经制定了一系列的卫星电话应用标准。
3.2音频编码标准发展现状
音频编码标准主要由ISO的MPEG组来完成。MPEG1是世界上第一个高保真音频数据压缩标准。MPEG1是针对最多两声道的音频而开发的。但随着技术的不断进步和生活水准的不断提高,有的立体声形式已经不能满足听众对声音节目的欣赏要求,具有更强定位能力和空间效果的三维声音技术得到蓬勃发展。而在三维声音技术中最具代表性的就是多声道环绕声技术。目前有两种主要的多声道编码方案:MUSICAM环绕声和杜比AC-3。MPEG2音频编码标准采用的就是MUSICAM环绕声方案,它是MPEG2音频编码的核心,是基于人耳听觉感知特性的子带编码算法。而美国的HDTV伴音则采用的是杜比AC-3方案。MPEG2规定了两种音频压缩编码算法,一种称为MPEG2后向兼容多声道音频编码标准,简称MPEG2BC;另一种是称为高级音频编码标准,简称MPEG2AAC,因为它与MPEG1不兼容,也称MPEGNBC。
MPEG4的目标是提供未来的交互多媒体应用,它具有高度的灵活性和可扩展性。与以前的音频标准相比,MPEG4增加了许多新的关于合成内容及场景描述等领域的工作。MPEG4将以前发展良好但相互独立的高质量音频编码、计算机音乐及合成语音等第一次合并在一起,并在诸多领域内给予高度的灵活性。
3.3具有我国自主知识产权的音频编码标准发展现状
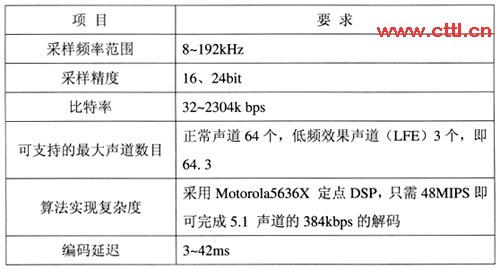
具有自主知识产权的广晟数码数字音频编解码算法(简称广晟数码音频技术,DRATM),它是可以同时支持立体声和多声道环绕声的数字音频编解码技术。其算法的特点是采用自适应时频分块(ATFT)方法实现对音频信号的最优分解,进行自适应量化和熵编码,其主要技术性能指标如表2所示。
另外,由多家研究所、大学组成的中国音视频编码技术委员会(AVS)目前正在研究制定AVS第2部分音频标准,并已经申请了部分专利。AVS音频标准的指导原则是:在基本解决知识产权问题的前提下,制定具有国际先进水平的中国音频编码/解码标准,使AVS音频编码的综合技术指标基本达到或超过MPEGAAC编码技术的指标。目前正在开展移动部分AVS-M的音频标准制定工作。
四、数字音频编码技术的发展趋势
4.1语音编码技术的发展趋势
经过多年的努力,业界在语音编码领域取得了很多重要的进展。目前在语音编码领域的研究焦点,一方面是在保证语音质量的前提下,降低比特率。在采用的技术方面从基于线性预测,使用合成一分析法向采用参数编码技术方向转变。主要的应用目标是蜂窝电话和应答机。另一方面是对传统的语音编码器进行全频带扩展,使其适应音频的应用。例如,AMR从NB发展到WB,再到最新的WB+,现正在进行全频带的扩展工作;G.729已发展到G.729.1,目前也在启动全频带的扩展工作;G.722.1也已发展到G.722.1AnnexE,已经完成了全频带的扩展工作。
除此之外,为适应在Internet上传送语音的需要,目前ITU-TSG16组正在研究和制定可变速率的语音编码标准。变速率的语音编码将是近期语音编码发展的一个趋势。
4.2音频编码技术的发展趋势
MPEG4的研究已经开始了一段时间,也取得了一些进展,但由于MPEG4本身设定的目标比较远大,一些能力仍然在研究之中。随着以IPTV业务为代表的信息检索业务的开展,适合于在IP网络上传输的音频信号编码技术,用于制作、检索和存储音频信息的技术将成为发展的方向。


