Deep Learning3: Softmax Regression
Softmax就是依概率预测分类标签
训练集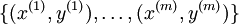 标签
标签 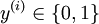
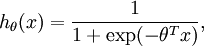
此时,cost function为
![\begin{align}
J(\theta) = -\frac{1}{m} \left[ \sum_{i=1}^m y^{(i)} \log h_\theta(x^{(i)}) + (1-y^{(i)}) \log (1-h_\theta(x^{(i)})) \right]
\end{align}](http://ufldl.stanford.edu/wiki/images/math/f/a/6/fa6565f1e7b91831e306ec404ccc1156.png)
若标签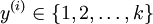 设定
设定
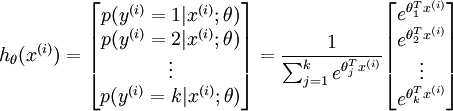
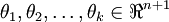
令
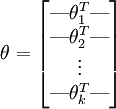
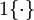 is the indicator function, so that 1{a true statement} = 1, and 1{a false statement} = 0
is the indicator function, so that 1{a true statement} = 1, and 1{a false statement} = 0
此时,cost function为
![\begin{align}
J(\theta) = - \frac{1}{m} \left[ \sum_{i=1}^{m} \sum_{j=1}^{k} 1\left\{y^{(i)} = j\right\} \log \frac{e^{\theta_j^T x^{(i)}}}{\sum_{l=1}^k e^{ \theta_l^T x^{(i)} }}\right]
\end{align}](http://ufldl.stanford.edu/wiki/images/math/7/6/3/7634eb3b08dc003aa4591a95824d4fbd.png)
![\begin{align}
J(\theta) &= -\frac{1}{m} \left[ \sum_{i=1}^m (1-y^{(i)}) \log (1-h_\theta(x^{(i)})) + y^{(i)} \log h_\theta(x^{(i)}) \right] \\
&= - \frac{1}{m} \left[ \sum_{i=1}^{m} \sum_{j=0}^{1} 1\left\{y^{(i)} = j\right\} \log p(y^{(i)} = j | x^{(i)} ; \theta) \right]
\end{align}](http://ufldl.stanford.edu/wiki/images/math/5/4/9/5491271f19161f8ea6a6b2a82c83fc3a.png)
对于softmax来说,设定indicator function为
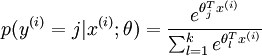
梯度如下
![\begin{align}
\nabla_{\theta_j} J(\theta) = - \frac{1}{m} \sum_{i=1}^{m}{ \left[ x^{(i)} \left( 1\{ y^{(i)} = j\} - p(y^{(i)} = j | x^{(i)}; \theta) \right) \right] }
\end{align}](http://ufldl.stanford.edu/wiki/images/math/5/9/e/59ef406cef112eb75e54808b560587c9.png)
迭代如下
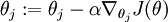
cost function上加入weight decay term得
![\begin{align}
J(\theta) = - \frac{1}{m} \left[ \sum_{i=1}^{m} \sum_{j=1}^{k} 1\left\{y^{(i)} = j\right\} \log \frac{e^{\theta_j^T x^{(i)}}}{\sum_{l=1}^k e^{ \theta_l^T x^{(i)} }} \right]
+ \frac{\lambda}{2} \sum_{i=1}^k \sum_{j=0}^n \theta_{ij}^2
\end{align}](http://ufldl.stanford.edu/wiki/images/math/4/7/1/471592d82c7f51526bb3876c6b0f868d.png)
此时梯度为
![\begin{align}
\nabla_{\theta_j} J(\theta) = - \frac{1}{m} \sum_{i=1}^{m}{ \left[ x^{(i)} ( 1\{ y^{(i)} = j\} - p(y^{(i)} = j | x^{(i)}; \theta) ) \right] } + \lambda \theta_j
\end{align}](http://ufldl.stanford.edu/wiki/images/math/3/a/f/3afb4b9181a3063ddc639099bc919197.png)
posted on 2016-10-13 17:11 Beginnerpatienceless 阅读(160) 评论(0) 收藏 举报

 浙公网安备 33010602011771号
浙公网安备 33010602011771号