语义分割损失函数
1. 交叉熵损失
语义分割时相当于对每个像素进行分类,所以实际是一个分类任务
对每一个像素的预测值与实际值比较,将损失求平均,是所以最常用的还是交叉熵损失
self.CE = nn.CrossEntropyLoss(weight=weight, ignore_index=ignore_index, reduction=reduction)
loss = self.CE(outputs, target)
2. 带权重的交叉熵损失
交叉熵Loss 可以用在大多数语义分割场景中,但它有一个明显的缺点,那就是对于只分割前景和背景
的时候,当前景像素的数量远远小于背景像素的数量时,即出现样本不平衡的的时候,损失函数中y=背景
的成分就会占据主导,使的模型严重偏向背景,导致效果不好。
为解决样本不平衡问题,
在多样本损失加一个小的权重,在少样本损失加一个大的权重
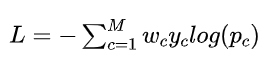
![]()
self.CE_loss = nn.CrossEntropyLoss(reduce=False, ignore_index=ignore_index, weight=alpha)
3. FoaclLoss
Focal Loss 用于解决难以样本数量不平衡问题,即更关注难分对样本的损失。一个简单的想法就是将高置信度的
样本的损失降低,低置信度的样本损失提高
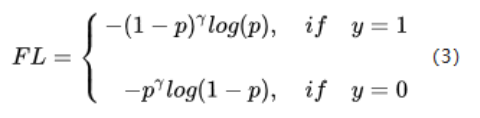
当p = 0.9 的时候,取 gamma=2, 损失降低了1000倍。
self.CE_loss = nn.CrossEntropyLoss(reduce=False, ignore_index=ignore_index)
logpt = self.CE_loss(output, target)
pt = torch.exp(-logpt)
loss = (1-pt)**self.gamma * logpt
loss.mean()
4. Dice Loss
用来度量集合相似度的度量函数,通常用于计算两个样本之间的像素。
![]()
class DiceLoss(nn.Module): def __init__(self, smooth=1, ignore_index=255): super(DiceLoss, self).__init__() self.ignore_index = ignore_index self.smooth = smooth def forward(self, output, target): if self.ignore_index not in range(target.min(), target.max()): if (target == self.ignore_index).sum() > 0: target[target==self.ignore_index] = target.min()
# 转化成one-hot形式 target = make_one_hot(target.unsqueeze(dim=1), classes=output.size()[1])
# 转化为概率 output = F.softmax(output, dim=1) output_flat = output.contiguous().view(-1) target_flat = target.contiguous().view(-1)
# 重合部分 intersection = (output_flat * target_flat).sum() loss = 1 - (2 * intersection + self.smooth) / (output_flat.sum() + target_flat.sum() + self.smooth)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号