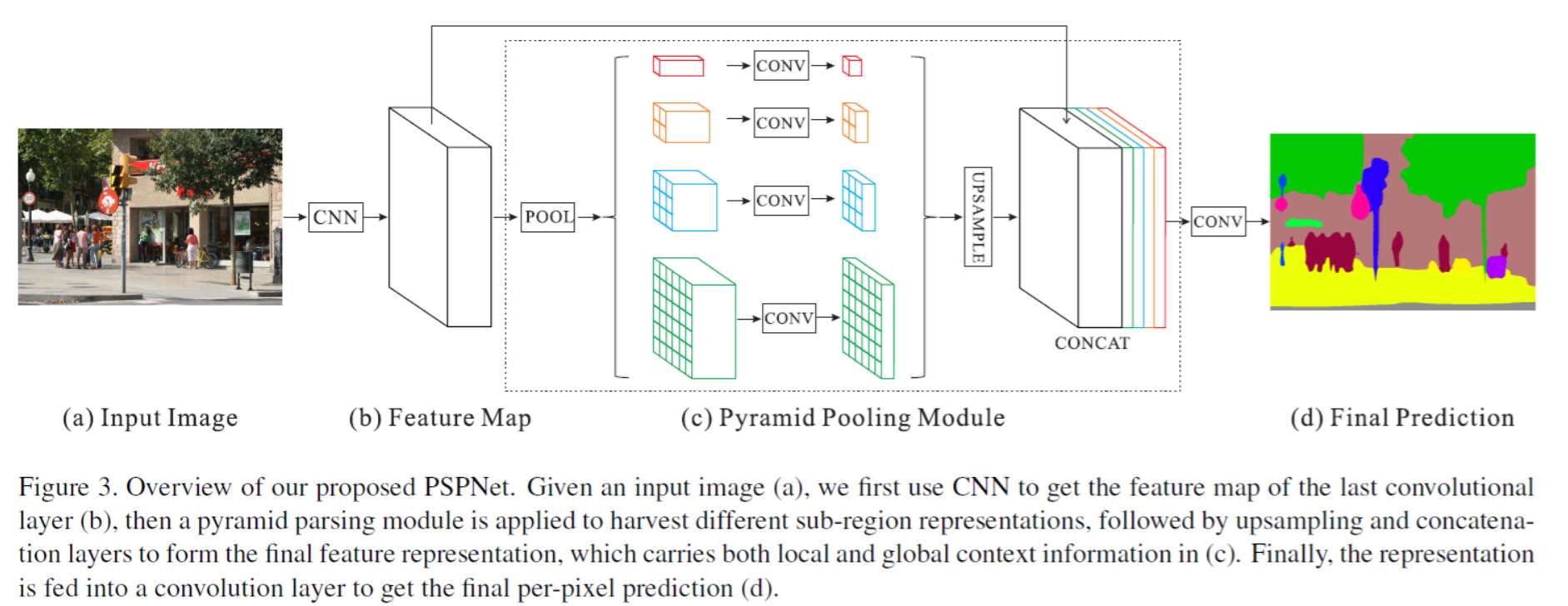
PSPNet
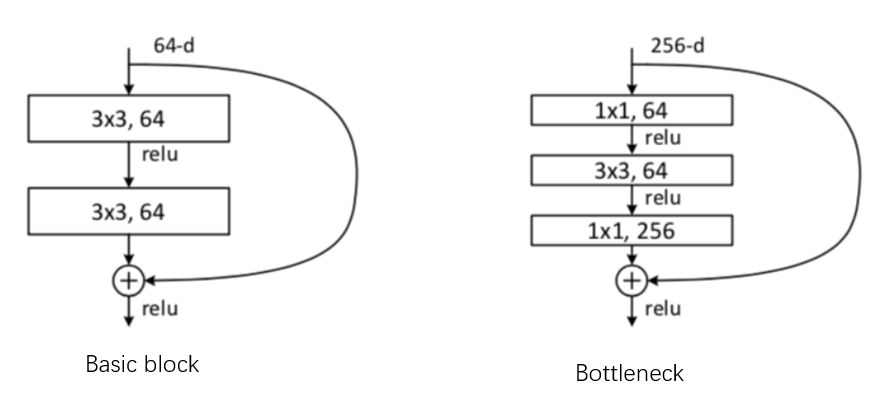
ResNet 主干特征提取
残差网络根据堆叠的层数不同,采用两个不同的单元。
ResNet(BasicBlock, [2, 2, 2, 2], **kwargs) //18
ResNet(BasicBlock, [3, 4, 6, 3], **kwargs) // 34
ResNet(Bottleneck, [3, 4, 6, 3], **kwargs) //50
ResNet(Bottleneck, [3, 4, 23, 3], **kwargs) //101
ResNet(Bottleneck, [3, 8, 36, 3], **kwargs) //152
为了保证可以相加,如果经过卷积后输出的h、w发生改变 ,在分支上会加上一个下采样的单元
if stride != 1 or self.inplanes != planes * block.expansion: # 1x1卷积,保证维度相同,可以相加 downsample = nn.Sequential( nn.Conv2d(self.inplanes, planes * block.expansion, kernel_size=1, stride=stride, bias=False), norm_layer(planes * block.expansion) )
相比于图像分类采用的残差网络,在PSPnet中后两个layer中strides=1,即不对图像进行下采样,最终得到 /8的feature_map
self.layer1 = self._make_layer(block, 64, layers[0], norm_layer=norm_layer)
self.layer2 = self._make_layer(block, 128, layers[1], stride=2, norm_layer=norm_layer)
self.layer3 = self._make_layer(block, 256, layers[2], stride=1, dilation=2, norm_layer=norm_layer)
self.layer4 = self._make_layer(block, 512, layers[3], stride=1, dilation=4, norm_layer=norm_layer)
为什么只进行了8倍的下采样呢?因为下采样越多对于图像的细节信息损失的就越多,为了避免太多细节信息的损失
所以相对于以前的分类问题,只进行了8倍的下采样。但这会带来一个新的问题,卷积操作的视野域减小
输出的feature_map上损失了全局信息。如何解决视野域的问题呢?答案就是空洞卷积。即在3*3卷积核中间填充0。
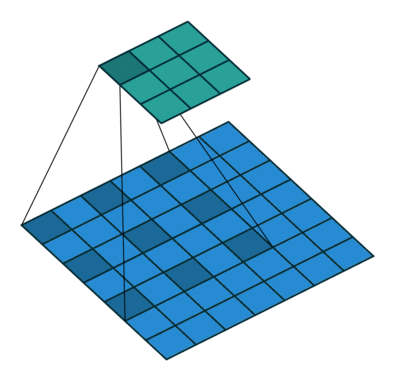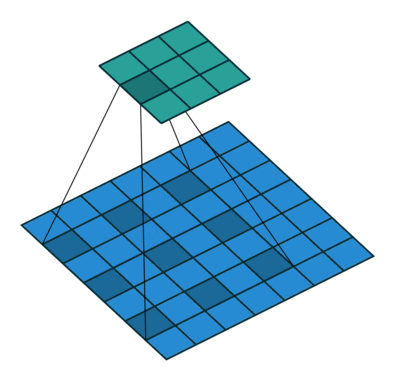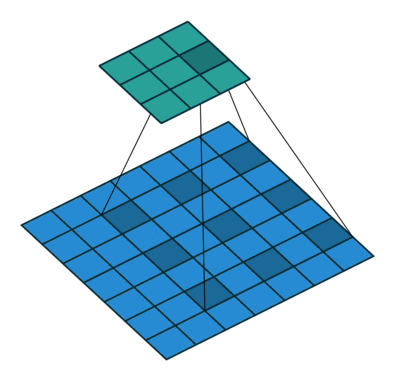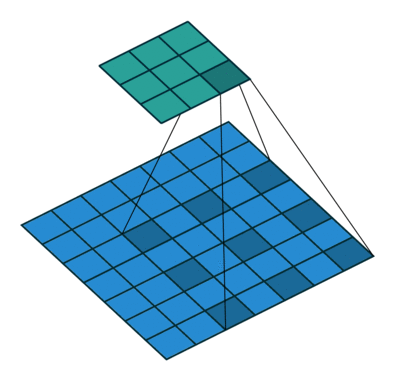
空洞卷积有一个参数可以设置dilation rate,具体含义就是在卷积核中填充dilation rate-1个0,
因此,当设置不同dilation rate时,感受野就会不一样,也即获取了多尺度信息。其计算输出的方式与普通卷积一样
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride, padding=dilation, dilation=dilation, bias=False)
当kernel_size = 3 , striides=1时,设置dilation=2, kernel_szie 被扩充为5 , 当padding=2 时,输出的分辨率和输入保持一致
而视野域相当于kernel_size = 5 的视野域。
还有一个好处,相比于分类采用的下采样32倍的残差网络,参数量并没有增加,所以可以采用迁移学习,直接用预训练网络的权重
Pyramid parsing module(PPM)
在feature map上做不同尺度的自适应平均池化(AdaptiveAvgPool2d)
prior = nn.AdaptiveAvgPool2d(output_size=bin_sz)
通过指定输出的大小,自适应调节kernel_size 和 strides 来进行平均池化
在PSPNet 中分别进行了四种不同尺度的均值池化,分别是(1, 2, 3, 6)
最后对这四个特征层进行上采样到与原feature_map同样大小,并于feature_map进行堆叠
pyramids = [features]
pyramids.extend([F.interpolate(stage(features), size=(h,w), mode='bilinear', align_corners=True)
for stage in self.stages])
torch.cat(pyramids, dim=1)
class _PSPModule(nn.Module): def __init__(self, in_channels, bin_sizes, norm_layer): super(_PSPModule, self).__init__() out_channels = in_channels // len(bin_sizes) # 不同大小均值池化,获得不同大小视野域 self.stages = nn.ModuleList([self._make_stages(in_channels, out_channels, b_s, norm_layer) for b_s in bin_sizes]) self.bottleneck = nn.Sequential(nn.Conv2d(in_channels+out_channels*len(bin_sizes), out_channels, kernel_size=3, padding=1, bias=False), norm_layer(out_channels), nn.ReLU(inplace=True), nn.Dropout2d(0.1)) def _make_stages(self, in_channels, out_channels, bin_sz, norm_layer): # 采用池化下采样 prior = nn.AdaptiveAvgPool2d(output_size=bin_sz) # 1X1 压缩维度 conv = nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False) bn = norm_layer(out_channels) relu = nn.ReLU(inplace=True) return nn.Sequential(prior, conv, bn, relu) def forward(self, features): h, w = features.size(2), features.size(3) pyramids = [features] # 组合不同视野域信息和浅层信息 # 双线性插值 上采样 pyramids.extend([F.interpolate(stage(features), size=(h,w), mode='bilinear', align_corners=True) for stage in self.stages ]) output = self.bottleneck(torch.cat(pyramids, dim=1)) return output
PSPNet总体结构
class PSPNet(nn.Module): def __init__(self, num_classes, backbone=resnet152, in_channels=3, pretrained=True, use_aux=True, freeze_bn=False, freeze_backbone=False): super(PSPNet, self).__init__() norm_layer = nn.BatchNorm2d model = backbone(pretrained, norm_layer=norm_layer) # 全连接输入单元数 : 512 * block.expansion m_out_sz = model.fc.in_features print("全连接层输入", m_out_sz) self.use_aux = use_aux # conv1, bn1, relu, maxpool self.initial = nn.Sequential(*list(model.children())[:4]) if in_channels != 3: self.initial[0] = nn.Conv2d(in_channels, 64, kernel_size=7, stride=2, padding=3, bias=False) self.initial = nn.Sequential(*self.initial) self.layer1 = model.layer1 self.layer2 = model.layer2 self.layer3 = model.layer3 self.layer4 = model.layer4 # 2048*n*n->2048*1*1->512*1*1->512*n*n # 2048*n*n->2048*2*2->512*2*2->512*n*n # 2048*n*n->2048*3*3->512*3*3->512*n*n # 2048*n*n->2048*6*6->512*6*6->512*n*n # (2048+512*4)*n*n -> 512*n*n -> num_classes*n*n self.master_branch = nn.Sequential( _PSPModule(m_out_sz, bin_sizes=[1, 2, 3, 6], norm_layer=norm_layer), nn.Conv2d(m_out_sz // 4, num_classes, kernel_size=1) ) # 1024*2n*2n -> 512*2n*2n -> num_classes*2n*2n self.auxiliary_branch = nn.Sequential( nn.Conv2d(m_out_sz // 2, m_out_sz // 4, kernel_size=3, padding=1, bias=False), norm_layer(m_out_sz // 4), nn.ReLU(inplace=True), nn.Dropout2d(0.1), nn.Conv2d(m_out_sz // 4, num_classes, kernel_size=1) ) #参数初始化 initialize_weights(self.master_branch, self.auxiliary_branch) if freeze_bn: self.freeze_bn() if freeze_backbone: set_trainable([self.initial, self.layer1, self.layer2, self.layer3, self.layer4], False) def forward(self, x): input_size = (x.size(2), x.size(3)) x = self.initial(x) #/4 x = self.layer1(x) #/4 x = self.layer2(x) #/8 x = self.layer3(x) #/8 dilated = True x_aux = x x = self.layer4(x) #/8 output = self.master_branch(x) # num_classes /8 /8 # num_classes /1 /1 output = F.interpolate(output, size=input_size, mode='bilinear') if self.training and self.use_aux: # num_classes /8 /8 aux = self.auxiliary_branch(x_aux) # num_classes /1 /1 aux = F.interpolate(aux, size=input_size, mode='bilinear') return output, aux return output

 浙公网安备 33010602011771号
浙公网安备 33010602011771号