目标检测——SSD先验框生成
SSD是常用的one_stage目标检测算法。目标检测直白理解就是用框取框图片中的各个位置,如果能框到目标,且目标的边界正好与框的边界重合
则说明检测到一个目标。如果我们用各种各样的框逐像素移动,那么肯定可以很快的检测到目标,但是这样就带来一个问题,各种各种的框,逐像素移动,就意味着无数个框,
这样,在计算层面是无法实现的,所以我们需要采取几个典型的框,以有一定间距的移动来框图片中的目标。如果把这些框平铺图片中,在SSD300中,这样的框共有8732个。
我们把这些框称为先验框,单纯用这些框取框图片中的目标,难免与真实的目标框不能完全吻合,我们在先验框的基础上进行中心点和长宽的微调,即可完成预测框的回归。
这些 先验框与yolo中的anchor一样,提供了预测框回归的基准。
那么为什么框的总数是8732呢, 如何得到这些框呢?
1. 框的中心点和尺寸
要想确定一个框只要确定了这个框的中心点和尺寸,就可以完全确定这个框了。
如果确定框的中心点呢?我们把图像分成N*N个格子,每个格子的中心点即为框的中心点,框与框的中心点相距 imge_size / N,相当于每隔imge_size / N的距离移动框来检测目标。
如果确定尺寸呢?在目标检测中,存在多种目标,有的大有的小,所以需要采取不同的长宽来覆盖不同大小的目标,如果imge_size / N比较大,则框的尺寸可以设置的大一点
如果imge_size / N比较小,可以设置的小一点。为了尽可能覆盖不同形状的目标,通过设置不同的长宽比,来覆盖不同形状的物体
所以目前我们需要解决的问题
1.1. 获得框的中心
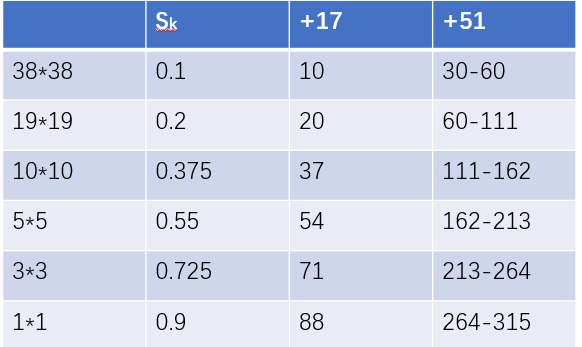
SSD中将原图分为(38*38), (19*19),(10*10),(5*5),(3*3),(1*1),以满足不同目标的大小的要求
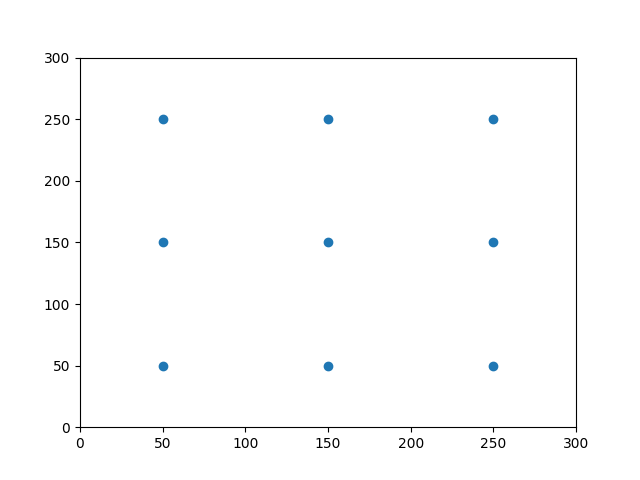
以图像大小300*300, 分成3*3个格子为例
step_x = img_width / layer_width
step_y = img_height / layer_height
linx = np.linspace(0.5 * step_x, img_width - 0.5 * step_x,
layer_width)
liny = np.linspace(0.5 * step_y, img_height - 0.5 * step_y,
layer_height)
centers_x, centers_y = np.meshgrid(linx, liny)
centers_x = centers_x.reshape(-1, 1)
centers_y = centers_y.reshape(-1, 1)
fig = plt.figure()
ax = fig.add_subplot(111)
plt.ylim(0, 300)
plt.xlim(0, 300)
plt.scatter(centers_x, centers_y)
plt.show()
1.2.获得尺寸
SSD中通过公式
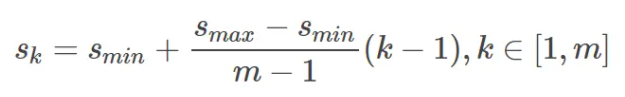
Sk相对于input_shape(300)的比例,Smin = 0.2 ,Smax = 0.9,m = 5, 因为第一层指定Sk = 0.1
最终得到各层的Sk对应的框的size,在实际处理时,做了取整,所以除第一层以外加51即可
1.3.获得不同的长宽比
SSD中在设置了三种长宽比1, 2, 1/2,3,1/3,
长宽比=1:正方形
Wk = Hk = min_size
Wk = Hk = √(min_size * max_size)
长宽比 = 2:
Wk = min_size * √2
Hk = min_size * √(1/2)
同理可以的得到其他长宽比的框的尺寸
因为当38*38, 3*3, 1*1时,没有设置1/3和3长宽比的框, 所以每个中心点对应4个框
而19*19, 10*10, 5*5,每个中心点对应6个框
所以框的总数 38*38*4 + 19*19*6 + 10*10*6 + 5*5*6 + 3*3*4 + 1*1*4= 5776 + 2166 + 600 + 300 + 36 + 4 = 8732
代码如下
import numpy as np import pickle import matplotlib.pyplot as plt class PriorBox(): def __init__(self, img_size, min_size, max_size=None, aspect_ratios=None, flip=True, variances=[0.1], clip=True, **kwargs): self.waxis = 1 self.haxis = 0 self.img_size = img_size if min_size <= 0: raise Exception('min_size must be positive.') self.min_size = min_size self.max_size = max_size self.aspect_ratios = [1.0] if max_size: if max_size < min_size: raise Exception('max_size must be greater than min_size.') self.aspect_ratios.append(1.0) if aspect_ratios: for ar in aspect_ratios: if ar in self.aspect_ratios: continue self.aspect_ratios.append(ar) if flip: self.aspect_ratios.append(1.0 / ar) self.variances = np.array(variances) self.clip = True def call(self, input_shape, mask=None): # 获取输入进来的特征层的宽与高 # 3x3 layer_width = input_shape[self.waxis] layer_height = input_shape[self.haxis] # 获取输入进来的图片的宽和高 # 300x300 img_width = self.img_size[0] img_height = self.img_size[1] # 获得先验框的宽和高 box_widths = [] box_heights = [] for ar in self.aspect_ratios: if ar == 1 and len(box_widths) == 0: box_widths.append(self.min_size) box_heights.append(self.min_size) elif ar == 1 and len(box_widths) > 0: box_widths.append(np.sqrt(self.min_size * self.max_size)) box_heights.append(np.sqrt(self.min_size * self.max_size)) elif ar != 1: box_widths.append(self.min_size * np.sqrt(ar)) box_heights.append(self.min_size / np.sqrt(ar)) box_widths = 0.5 * np.array(box_widths) box_heights = 0.5 * np.array(box_heights) step_x = img_width / layer_width step_y = img_height / layer_height linx = np.linspace(0.5 * step_x, img_width - 0.5 * step_x, layer_width) liny = np.linspace(0.5 * step_y, img_height - 0.5 * step_y, layer_height) centers_x, centers_y = np.meshgrid(linx, liny) # 计算网格中心 centers_x = centers_x.reshape(-1, 1) centers_y = centers_y.reshape(-1, 1) num_priors_ = len(self.aspect_ratios) # 每一个先验框需要两个(centers_x, centers_y),前一个用来计算左上角,后一个计算右下角 prior_boxes = np.concatenate((centers_x, centers_y), axis=1) prior_boxes = np.tile(prior_boxes, (1, 2 * num_priors_)) # 获得先验框的左上角和右下角 prior_boxes[:, ::4] -= box_widths prior_boxes[:, 1::4] -= box_heights prior_boxes[:, 2::4] += box_widths prior_boxes[:, 3::4] += box_heights # 变成小数的形式 prior_boxes[:, ::2] /= img_width prior_boxes[:, 1::2] /= img_height prior_boxes = prior_boxes.reshape(-1, 4) prior_boxes = np.minimum(np.maximum(prior_boxes, 0.0), 1.0) num_boxes = len(prior_boxes) if len(self.variances) == 1: variances = np.ones((num_boxes, 4)) * self.variances[0] elif len(self.variances) == 4: variances = np.tile(self.variances, (num_boxes, 1)) else: raise Exception('Must provide one or four variances.') prior_boxes = np.concatenate((prior_boxes, variances), axis=1) return prior_boxes def get_anchors(img_size = (300,300)): net = {} priorbox = PriorBox(img_size, 30.0,max_size = 60.0, aspect_ratios=[2], variances=[0.1, 0.1, 0.2, 0.2], name='conv4_3_norm_mbox_priorbox') net['conv4_3_norm_mbox_priorbox'] = priorbox.call([38,38]) priorbox = PriorBox(img_size, 60.0, max_size=111.0, aspect_ratios=[2, 3], variances=[0.1, 0.1, 0.2, 0.2], name='fc7_mbox_priorbox') net['fc7_mbox_priorbox'] = priorbox.call([19,19]) priorbox = PriorBox(img_size, 111.0, max_size=162.0, aspect_ratios=[2, 3], variances=[0.1, 0.1, 0.2, 0.2], name='conv6_2_mbox_priorbox') net['conv6_2_mbox_priorbox'] = priorbox.call([10,10]) priorbox = PriorBox(img_size, 152.0, max_size=213.0, aspect_ratios=[2, 3], variances=[0.1, 0.1, 0.2, 0.2], name='conv7_2_mbox_priorbox') net['conv7_2_mbox_priorbox'] = priorbox.call([5,5]) priorbox = PriorBox(img_size, 213.0, max_size=264.0, aspect_ratios=[2], variances=[0.1, 0.1, 0.2, 0.2], name='conv8_2_mbox_priorbox') net['conv8_2_mbox_priorbox'] = priorbox.call([3,3]) priorbox = PriorBox(img_size, 264.0, max_size=315.0, aspect_ratios=[2], variances=[0.1, 0.1, 0.2, 0.2], name='pool6_mbox_priorbox') net['pool6_mbox_priorbox'] = priorbox.call([1,1]) net['mbox_priorbox'] = np.concatenate([net['conv4_3_norm_mbox_priorbox'], net['fc7_mbox_priorbox'], net['conv6_2_mbox_priorbox'], net['conv7_2_mbox_priorbox'], net['conv8_2_mbox_priorbox'], net['pool6_mbox_priorbox']], axis=0) return net['mbox_priorbox']

 浙公网安备 33010602011771号
浙公网安备 33010602011771号