目标检测——yolov4损失函数
损失函数
yolo损失分为3个部分类别损失、置信度损失、位置损失
1. 类别损失
只有有目标的地方才会有类别判断,从而才会有类别损失,所以需要解决两个问题:1.有目标的地方;2.类别损失
1.1有目标的地方:object_mask
object_mask根据 y_true(真实值)确定,如何通过前处理编码y_true,通过计算实际框(ground_truth)与anchor框的iou来确定
achor的9个框分为3组,分别负责下小目标(8倍下采样)、中目标(16倍下采样)、大目标(32倍下采样) ,计算每个框与anchor框的iou,iou最大的anchor负责回归这个真实框,
以13*13 (32倍下采样)为例,整幅图被分为13*13个gird,真实框的信息应该放在哪个grid里面呢?答案是真实框的中心落在哪个grid里面,这个grid就负责存储这个框的所有信息,
包括(x, y, h, w),(confidence=1),(class)。object_mask,顾名思义,目标掩码,即有目标的地方为true,所以 object_mask = y_true[l][..., 4:5]
2.1类别损失
类型损失,一般采用交叉熵损失,在目标检测中,采用二元交叉熵损失,对每一个类别计算交叉熵损失,进行求和;
class_loss = object_mask * K.binary_crossentropy(true_class_prob, raw_pred[..., 5:], from_logits=True)
class_loss = K.sum(class_loss) / mf
此处为什么不采用softmax交叉熵损失呢?此处笔者也不清楚,欢迎有答案的同学留言交流。我猜测是因为各个类别之间相互独立,不是非A即B的关系
所以没有采用softmax,将所有类别的概率之和调整为1。
2.位置损失
目标检测的一项重要任务就是确定目标的位置,即(x, y, h, w),所以损失值的计算中包含位置损失
通常计算位置损失有
1. L1 Loss 平均绝对误差(Mean Absolute Error, MAE
梯度值为1或-1,在接近准确值时,会以learning_rate在准确值附近波动,比较难获得准确效果
2. L2 Loss 均方误差损失(Mean Square Error, MSE
在距离准确值较远的地方梯度值较大,训练初期收敛难度大,容易受到噪声的干扰
克服了以上两种损失函数的缺点,但将x,y,h,w作为独立的变量的看待,割裂了他们之间的相对关系
考虑重合面积,可以较好的反应预测框和真实框的接近程度,但是但二者不相交时,损失值恒为1
考虑了不重合部分的面积对于损失的影响
考虑了中心点的偏移,即两个框中心的距离与两个框最远距离的比值
考虑了长和宽的比值
在yoloV4中,采用了CIou Loss
def box_ciou(b1, b2): b1_xy = b1[..., :2] b1_wh = b1[..., 2:4] b1_wh_half = b1_wh / 2. b1_mins = b1_xy - b1_wh_half b1_maxes = b1_xy + b1_wh_half b2_xy = b2[..., :2] b2_wh = b2[..., 2:4] b2_wh_half = b2_wh / 2. b2_mins = b2_xy - b2_wh_half b2_maxes = b2_xy + b2_wh_half intersect_mins = K.maximum(b1_mins, b2_mins) intersect_maxes = K.minimum(b1_maxes, b2_maxes) intersect_wh = K.maximum(intersect_maxes-intersect_mins, 0.) # 两个框相交部分面积 intersect_area = intersect_wh[..., 0] * intersect_wh[..., 1] b1_area = b1_wh[..., 0] * b1_wh[..., 1] b2_area = b2_wh[..., 0] * b2_wh[..., 1] union_area = b1_area + b2_area - intersect_area # 两个框的iou iou = intersect_area / K.maximum(union_area, K.epsilon()) # 两个框中心点的距离 center_distance = K.sum(K.square((b1_xy - b2_xy)), axis=-1) enclose_mins = K.minimum(b1_mins, b2_mins) enclose_maxes = K.maximum(b1_maxes, b2_maxes) enclose_wh = K.maximum(enclose_maxes - enclose_mins, 0.0) # 两个框的最远距离 enclose_diagonal = K.sum(K.square(enclose_wh), axis=-1) # 计算DIOU(CIOU的前半部分) ciou = iou - 1.0 * (center_distance) / K.maximum(enclose_diagonal, K.epsilon()) # 计算两个框的长宽比的差值的平方 v = 4*K.square(tf.math.atan2(b1_wh[..., 0], K.maximum(b1_wh[..., 1],K.epsilon())) - tf.math.atan2(b2_wh[..., 0], K.maximum(b2_wh[..., 1],K.epsilon()))) / (math.pi * math.pi) alpha = v / K.maximum((1.0 - iou + v), K.epsilon()) ciou = ciou - alpha * v ciou = K.expand_dims(ciou, -1) return ciou
ciou_loss = object_mask * box_loss_scale * (1 - ciou)
ciou_loss = K.sum(ciou_loss) / mf
其中 box_loss_scale 为 (2 - 对应真实框的面积),范围为(1-2),当真实框的面积越大,box_loss_scale越小,意味着对大框的偏差容忍度越大。
解决了以上问题以后,我们还有一个重要问题没有解决,预测框的(x, y, h, w)如何得到?
在yolo中,我们的(x,y)是通过对应grid左上角偏移得到;(h,w)是通过对对应anchor的长宽缩放得到,
box_xy = (K.sigmoid(feats[..., :2]) + grid) / K.cast(grid_shape[..., ::-1], K.dtype(feats))
box_wh = K.exp(feats[..., 2:4]) * anchors_tensor / K.cast(input_shape[..., ::-1], K.dtype(feats))
前半部分(斜体加粗),公式转化如图所示
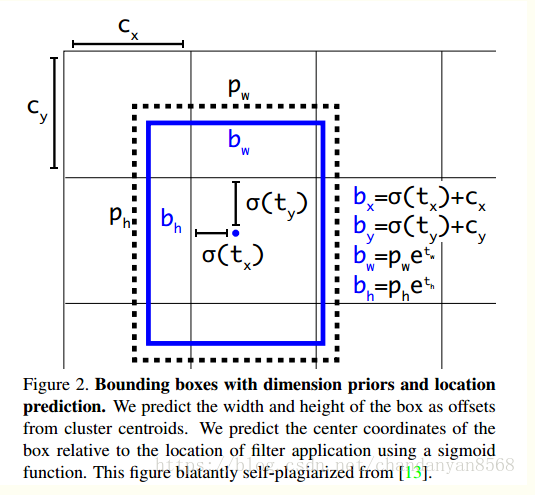
后半部分,box_xy 除以grid_shape 将中心点坐标转化为(0-1),与y_true中中心点的坐标的编码对应,同样转化为(0-1),即中心点相对于输入图像的位置;同样也是作归一化处理;box_hw 除以input_shape 将长宽转化为(0-1),与y_true中长宽的编码对应。
3.置信度损失
置信度损失分为两个部分,有目标的置信度损失,无目标的置信度损失
3.1 有目标的置信度损失
有目标的地方,即object_mask,
置信度损失:采用二元交叉熵损失
K.binary_crossentropy(object_mask, raw_pred[..., 4:5]
总的损失为
object_mask * K.binary_crossentropy(object_mask, raw_pred[..., 4:5], from_logits=True)
3.2 无目标的置信度损失
无目标的地方,即(1-object_mask)
(1 - object_mask) * K.binary_crossentropy(object_mask, raw_pred[..., 4:5], from_logits=True)
存在一个问题,因为一张图中大部分是背景,即大部分是负样本,如果所有的负样本都参与计算,会极大的放大负样本的损失,导致训练结果偏向于负样本,
所以在计算无目标的置信度损失时只会选择部分负样本,如何选择负样本?原则是计算预测值框和真实值框的iou,每个预测值的每个grid中都有三个框(以13*13)为例,每个真实值(一幅图)中有那个框
依次计算iou,会得到(13*13*3*n)个iou,选取最大的iou作为预测值和真实值的iou,得到的维度为(13,13,3,1),设置一个iou阈值,小于此阈值的视为负样本,其实质笔者认为是一种随机取样的方法。
def loop_body(b, ignore_mask): true_box = tf.boolean_mask(y_true[l][b, ..., 0:4], object_mask_bool[b, ..., 0]) iou = box_iou(pred_box[b], true_box) best_iou = K.max(iou, axis=-1) # 13, 13, 3 ignore_mask = ignore_mask.write(b, K.cast(best_iou<ignore_thresh, K.dtype(true_box))) return b+1, ignore_mask
得到ignore_mask ,所以无目标的置信度损失为:
confidence_loss = object_mask * K.binary_crossentropy(object_mask, raw_pred[..., 4:5], from_logits=True) + \
(1 - object_mask) * K.binary_crossentropy(object_mask, raw_pred[..., 4:5], from_logits=True) * ignore_mask
confidence_loss = K.sum(confidence_loss) / mf
所以最终的目标检测损失为三者的损失之和:
loss += location_loss + confidence_loss + class_loss

 浙公网安备 33010602011771号
浙公网安备 33010602011771号