BatchNormalization
一般而言,我们需要对输入进行归一化,保证输入的特征在都分布在0-1或者-1 - +1,这样可以加快收敛,防止因某一个特征数值大造成的模型过拟合或欠拟合问题。
但深度学习因为模型深度深,常常会出现梯度爆炸或梯度消失问题,如果对每一层输入都进行特征的归一化,可以有效地解决这个问题。
BatchNormalization,即批归一化,因为在模型训练时,常常采用mini_batch 的梯度下降,所以我们的归一化在数据的每个Batch 上进行。
首先看一下BatchNormalization的公式

以上公式可拆为两部分
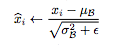
上面这个公式已经实行了归一化,其中下标i代表的时第i个特征,归一化是要数据的每一个特征都服从均值为0,方差为1的正态分布,平均值和方差的计算都是基于多条数据的,
所以当batch_size 为1 的时候,无法做归一化,当输入的数据是图片时,特征表现为各个通道。
为什么要让数据各个特征服从均值为0,方差为1的正态分布呢,以sigmoid 激活函数为例,如果数据分布在-1到1 之间,在反向传播时,会有较大的梯度,可以加快收敛。
但是存在一个问题,数据分布在-1到1 之间,正向传播时,激活函数处在线性区间内,降低了模型的表达能力。因为多个线性变换的叠加相当与一个线性变换。
所以BatchNormalization还包括下面这一部分,其中γ 和 β是可学习的参数
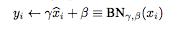
这样可以把分布微调,偏离正态分布,即保证模型处在非线性区域又能保证反向传播的梯度。
关于BatchNormalization的参数个数,对于每一个特征都有一个γ 和 β,所以总的参数个数为2倍的特征数,
如果输入的通道数为256,所以BatchNormalization的参数个数为 512.
BatchNormalization 的实现
def batchnorm_forward(x, gamma, beta, bn_param): mode = bn_param['mode'] eps = bn_param.get('eps', 1e-5) momentum = bn_param.get('momentum', 0.9) N, D = x.shape running_mean = bn_param.get('running_mean', np.zeros(D, dtype=x.dtype)) #D个平均值 running_var = bn_param.get('running_var', np.zeros(D, dtype=x.dtype)) #D个方差值 out, cache = None, None if mode == 'train': sample_mean = np.mean(x, axis=0, keepdims=True) sample_var = np.var(x, axis=0, keepdims=True) x_normalized = (x - sample_mean) / np.sqrt(sample_var + eps) out = gamma * x_normalized + beta # gamma = np.ones((1, D)) 每个特征一个gamma, 共D个 # beta = np.zeros((1, D)) 每个特征一个beta, 共D个 cache = (x_normalized, gamma, beta, sample_mean, sample_var, x, eps) # mean值更新 , 指数加权平均 running_mean = momentum * running_mean + (1 - momentum) * sample_mean # var值更新 , 指数加权平均 running_var = momentum * running_var + (1 - momentum) * sample_var elif mode == 'test': x_normalized = (x - running_mean) / np.sqrt(running_var + eps) out = gamma * x_normalized + beta else: raise ValueError("Invalid forward batchnorm mode %s" %mode) bn_param['runing_mean'] = running_mean # mean值更新 , 用于预测 bn_param['running_var'] = running_var # var值更新 , 用于预测 return out, cache

 浙公网安备 33010602011771号
浙公网安备 33010602011771号