

以“猫眼电影热映”信息为例,爬取了数据,然后存入MySQL中
今天又爬了一下数据,是猫眼电影中正在热映的数据,主要获取的字段为,电影标题(title)、图片链接(img_url)、评分(score)
网站URL地址:https://maoyan.com/films?showType=1&offset=*(0,30,60)三个页面
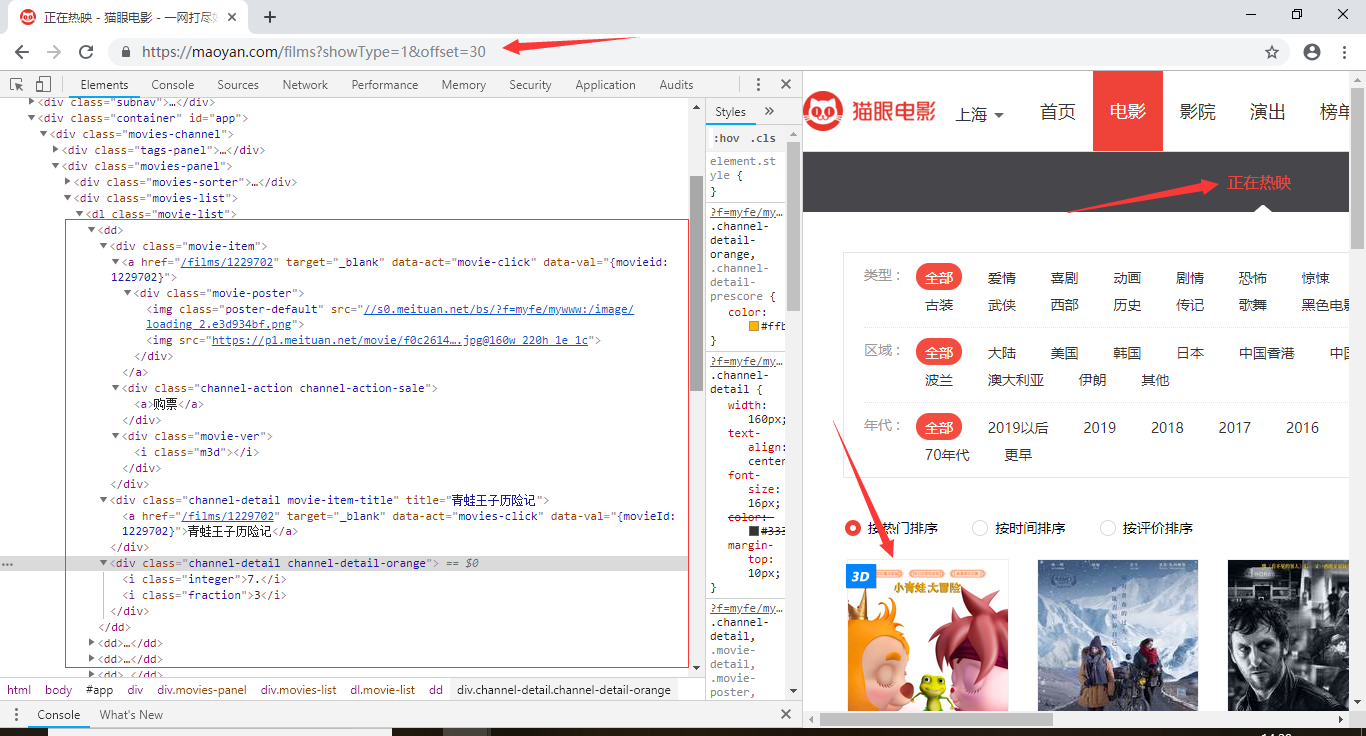
具体信息都标出来了,
源代码如下:
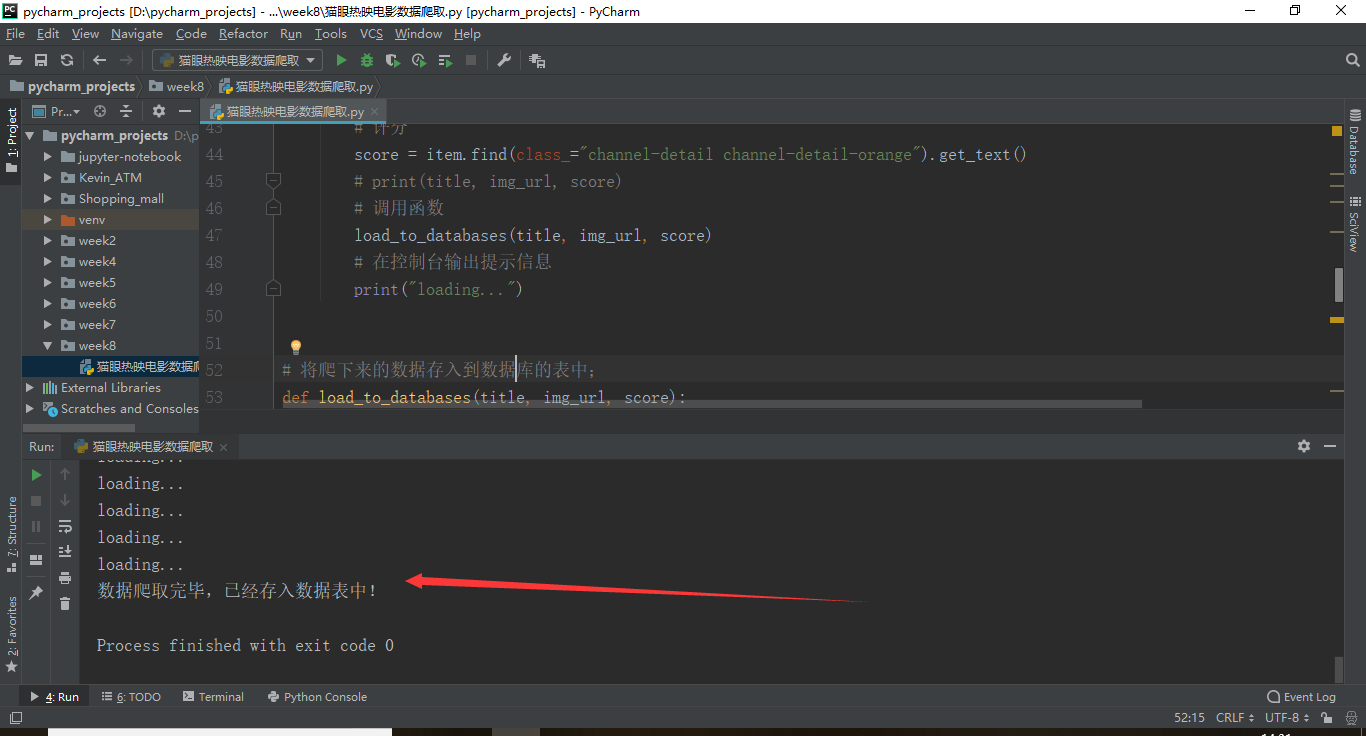
1 # Author Kevin_Lu 2 # Date 2019/4/9 3 # 导入模块 4 import requests 5 from requests import RequestException 6 from bs4 import BeautifulSoup 7 import pymysql 8 9 10 # 目标地址:https://maoyan.com/films?showType=1&offset=0,offset=30为翻页 11 # 获取页面信息 12 def get_page_info(pages): 13 try: 14 # 伪装成浏览器 15 headers = { 16 "user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.121 Safari/537.36" 17 } 18 # 目标地址 19 url = "https://maoyan.com/films?showType=1&offset=" + str(pages) 20 # 获取源代码 21 response = requests.get(url, headers=headers) 22 # 判断响应码 23 if response.status_code == 200: 24 # 返回页面源码 25 return response.text 26 except RequestException as e: 27 return e 28 29 30 # 解析页面信息 31 def parser_page_info(response): 32 # 调用BeautifulSoup 33 soup = BeautifulSoup(response, "lxml") 34 # find内容 35 items = soup.find("dl", class_="movie-list").findAll("dd") 36 # 循环find目标字段信息 37 for item in items: 38 # 标题 39 title = item.find(class_="channel-detail movie-item-title").get("title") 40 # 因为每个movie-poster下面有两个img标签,所有要使用findAll找出所有的img再使用[1]来获取第二个标签data-src 41 # 根据print显示,源代码中data-src隐藏为了src.于是爬取的时候实际需要爬取的是data-src 42 img_url = item.findAll("img")[1].get("data-src") 43 # 评分 44 score = item.find(class_="channel-detail channel-detail-orange").get_text() 45 # print(title, img_url, score) 46 # 调用函数 47 load_to_databases(title, img_url, score) 48 # 在控制台输出提示信息 49 print("loading...") 50 51 52 # 将爬下来的数据存入到数据库的表中; 53 def load_to_databases(title, img_url, score): 54 # 连接数据库 55 conn = pymysql.connect(host="127.0.0.1", port=3306, user="root", password="123", db="maoyanreying") 56 # 获取cursor 57 cursor = conn.cursor() 58 # sql语句 59 sql = ''' 60 insert into maoyanreying_tb(title, img_url, score) values("%s","%s","%s"); 61 ''' % (title, img_url, score) 62 # 执行sql 63 cursor.execute(sql) 64 # 提交代码 65 conn.commit() 66 # 关闭cursor、conn 67 cursor.close() 68 conn.close() 69 70 71 # main函数 72 if __name__ == '__main__': 73 # 获取页面信息函数 74 # 起始页 75 pages = 0 76 while pages <= 60: 77 # 调用函数 78 response = get_page_info(pages) 79 parser_page_info(response) 80 # 页面翻页 81 pages += 30 82 # 提示信息 83 print("数据爬取完毕,已经存入数据表中!")
创建数据库(mysql为例):
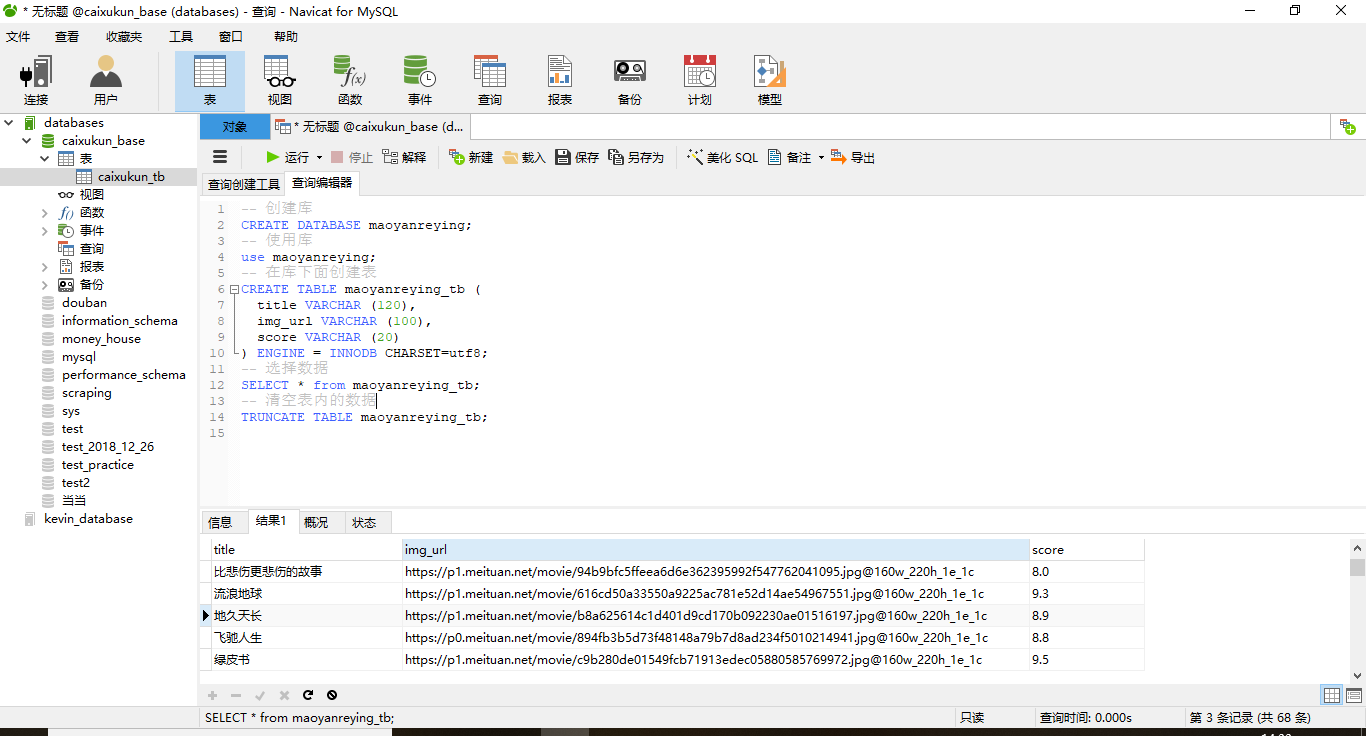
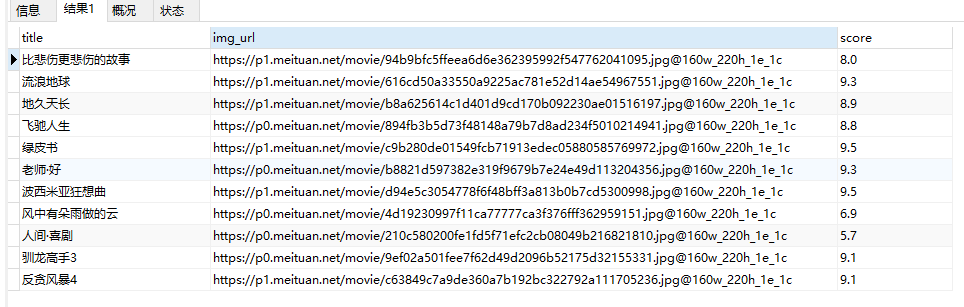
接下来其实可以进行分析,目前我还没有进行分析;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号