
pytorch教程[2] Tensor的使用
[1]中的程序可以改成如下对应的Tensor形式:
import torch dtype = torch.FloatTensor # dtype = torch.cuda.FloatTensor # Uncomment this to run on GPU # N is batch size; D_in is input dimension; # H is hidden dimension; D_out is output dimension. N, D_in, H, D_out = 64, 1000, 100, 10 # Create random input and output data x = torch.randn(N, D_in).type(dtype) y = torch.randn(N, D_out).type(dtype) # Randomly initialize weights w1 = torch.randn(D_in, H).type(dtype) w2 = torch.randn(H, D_out).type(dtype) learning_rate = 1e-6 for t in range(500): # Forward pass: compute predicted y h = x.mm(w1) h_relu = h.clamp(min=0) y_pred = h_relu.mm(w2) # Compute and print loss loss = (y_pred - y).pow(2).sum() print(t, loss) # Backprop to compute gradients of w1 and w2 with respect to loss grad_y_pred = 2.0 * (y_pred - y) grad_w2 = h_relu.t().mm(grad_y_pred) grad_h_relu = grad_y_pred.mm(w2.t()) grad_h = grad_h_relu.clone() # copy一份,硬拷贝 可以用这样的代码测试 a=torch.Tensor(3) b=a.clone() b[2]=100 b[2] b[2] grad_h[h < 0] = 0 grad_w1 = x.t().mm(grad_h) #x.t()表示x的转置,x没变;如果想改变x,x.t_() _表示原地操作 # Update weights using gradient descent w1 -= learning_rate * grad_w1 w2 -= learning_rate * grad_w2
有两个函数需要说明 h.clamp(min=0)
clamp表示夹紧,夹住的意思,torch.clamp(input,min,max,out=None)-> Tensor
将input中的元素限制在[min,max]范围内并返回一个Tensor
用法:
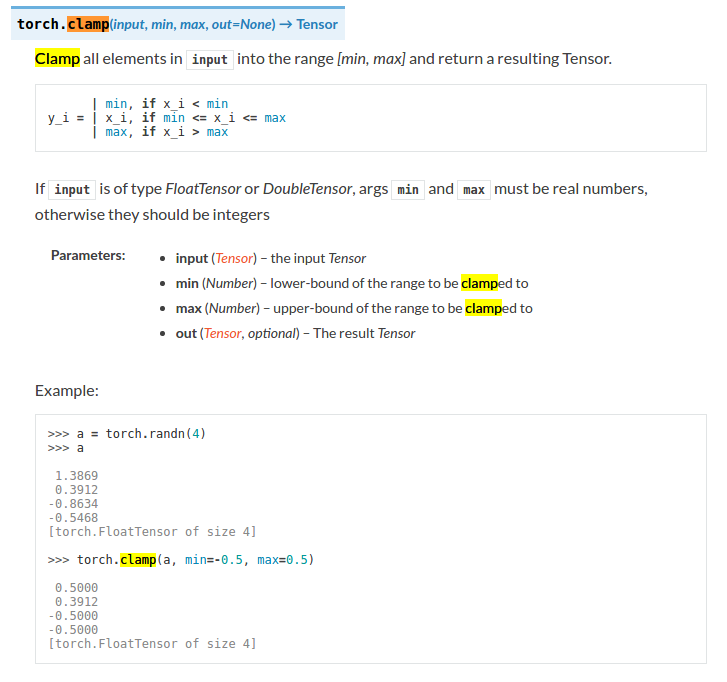
下面的doc有错误: 应为
torch.clamp(input,min,*,out=None)->Tensor


 浙公网安备 33010602011771号
浙公网安备 33010602011771号