
datawhale吃瓜教程Task01-概览西瓜书+南瓜书1、2章
第一章 绪论
基本术语
机器学习定义: 假设用P来评估计算机程序在某一个任务类T上的性能,若一个程序通过利用经验E在T中任务上获得了性能改善,则我们就说关于T和P,该程序对E进行了学习。
属性: 反映事件或对象在某方向的表现或性质,也称为特征。如西瓜的“色泽”、“敲声”等。
属性值: 顾名思义,属性的取值就称为属性值,如“青绿”、“乌黑”等。
属性空间: 属性张成的空间称为属性空间,也称为样本空间或者“输入空间”。如把“色泽”、“根蒂”、“敲声”作为三个坐标轴,则他们张成一个描述西瓜的三维空间,每个西瓜都可以在这个空间中找到自己的坐标位置。由于空间中每个点都对应一个坐标向量,所以我们也在一个实例称为一个“特征向量”。
数据集: 一组记录的集合称为数据集。
样本: 其中每一条记录是关于一个事件或对象的描述,称为示例或样本,例如:(色泽=青绿;根蒂=稍蜷;敲声=沉闷)
学习: 从数据中学得模型的过程称为学习,这个过程一般通过执行某个学习算法来完成,也称为训练。
训练数据: 训练过程中使用的数据称为训练数据。
训练样本: 训练过程的每个样本称为训练样本。
训练集: 由训练样本组成的集合称为训练集。
假设: 学得模型对应了关于数据的某种潜在的规律,即hypothesis,这个英文名我们会在后续文章中继续用到。
学习器: 其实学习的过程是为了找出或者逼近真相,所以我们有时候也把模型称为“学习器”,可看作学习算法在给定数据和参数空间上的实例化。
标记(label): 想要学得一个模型,仅有已有的示例数据是不够的。要建立一个关于预测的模型,需要获得训练样本的“结果”信息。例如“((色泽=青绿;根蒂=稍蜷;敲声=浊响),好瓜)”。这里关于示例结果的信息“好瓜”,就称为标记。
分类: 如果我们预测的值是离散值,如“好瓜”、“坏瓜”,这一类学习任务就称为分类。
回归: 如果我们预测的值是连续值,例如西瓜的成熟度0.78,0.37,则我们称此类学习任务为回归。
监督学习(supervised learning): 训练的数据既有特征又有标签(,通过训练,典型代表是分类和回归。
无监督学习(unsupervised learning): 训练的数据没有标签存在,通过数据之间的内在联系和相似性将他们分成若干类。典型代表为聚类。
泛化能力: 我们学的模型可以适用于新样本的能力称为泛化能力,具有强泛化能力的模型可以很好的适用于整个样本空间。
独立同分布: 假设样本空间中全体样本服从一个未知的“分布”D,我们获得的每个样本都是独地从这个分布上采样获得的,即“独立同分布”。
奥卡姆剃刀
奥卡姆剃刀为我们提供了一种常用的,自然科学研究种最基本的法则,可以用来引导算法确立“正确”的偏好。即“若有多个假设与观察一致,则选择最简单的那个”。
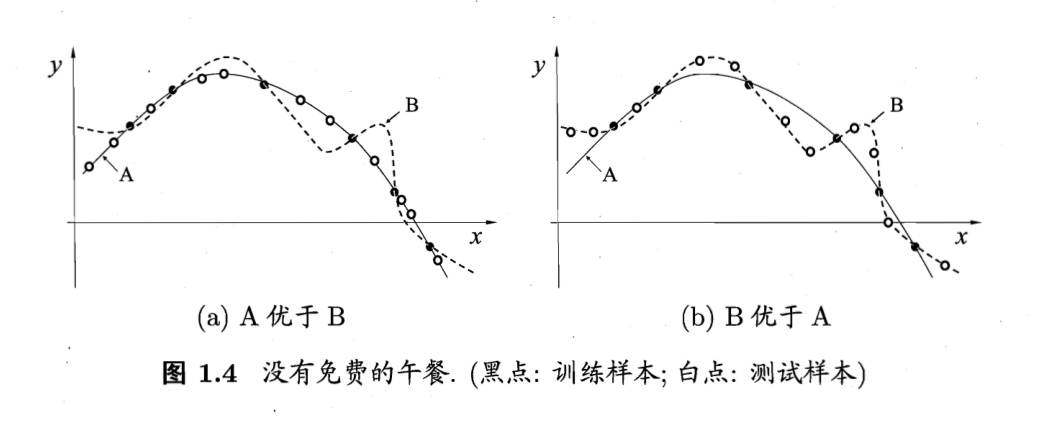
根据“奥卡姆剃刀”法则,对于如下两个算法A和B,我们根据平滑曲线的某种“描述简单性”希望算法A的性能比算法B更好。左图的结果显示:与B相比,A与训练集外的样本更一致,换言之,A的泛化能力比B强。但是右图的结果显示算法B的性能更好,这种情况也有可能出现。
第二章 模型评估与选择
基本术语:
错误率(error rate):分类错误的样本数占样本总数的比例
精度(accuracy):精度 = 1 - 错误率
误差(error):学习器的实际预测输出与样本的真实输出之间的差异
训练误差(training error)/经验误差(empirical error):学习器在训练集上的误差
泛化误差(generalization error):学习器在新样本上的误差
过拟合(overfitting):学习器把训练样本自身的一些特点当作了所有潜在样本都会具有的一般性质,导致泛化性能下降
欠拟合(underfitting):学习器对训练样本的一般性质尚未学好
评估方法:
留出法 (hold-out)
交叉验证法(cross validation)
自助法 (bootstrapping)
性能度量:
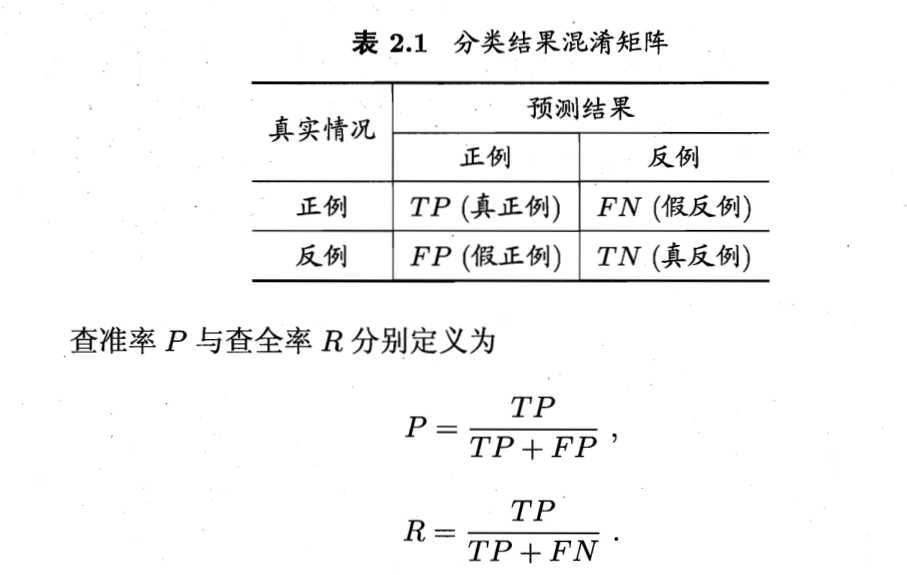
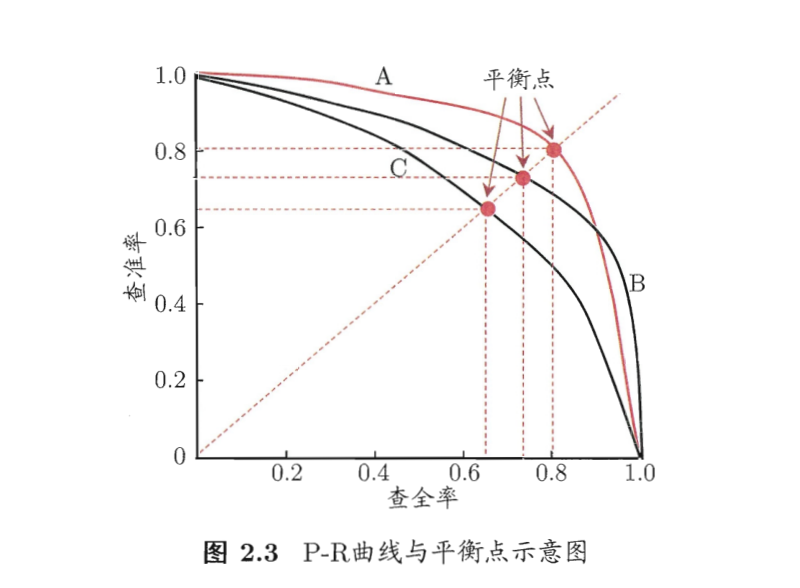
查准率(precision)
查全率(recall)
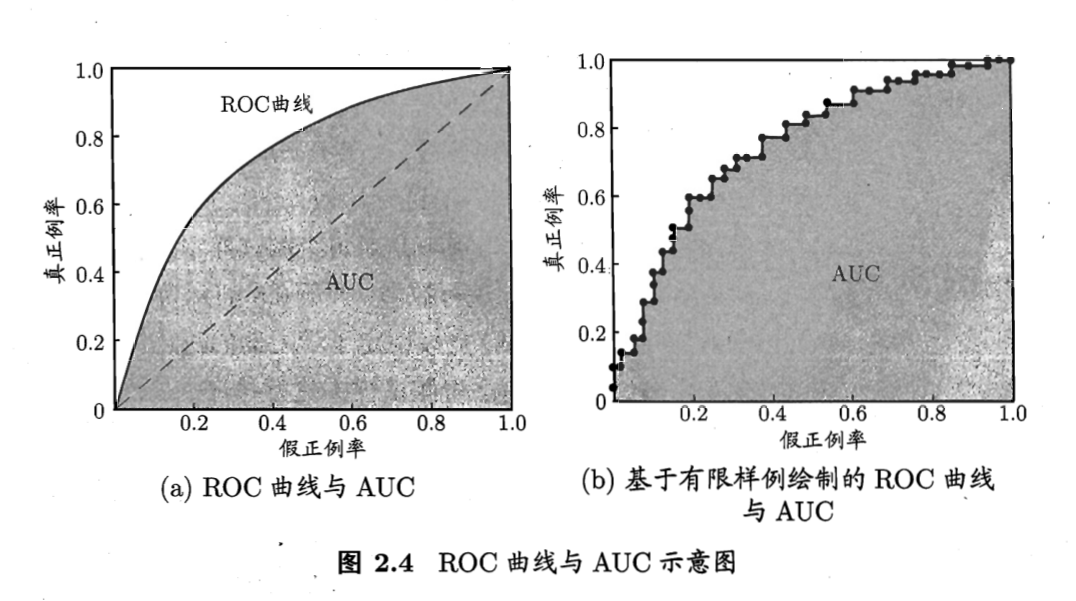
ROC 与AUC
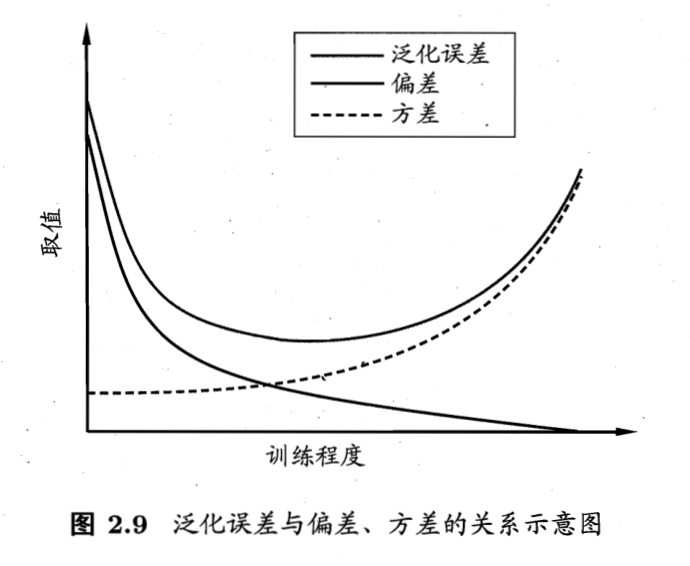
偏差与方差
泛化误差 = 偏差 + 方差 + 噪声
偏差度量了学习算法的期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力
方差度量了同样大小的训练集的变动所导致的学习性能的变化,即刻画了数据扰动所造成的影响
噪声表达了在当前任务上任何学习算法所能达到的期望泛化误差的下界,即刻画了学习问题本身的难度
参考资料
机器学习 周志华

 浙公网安备 33010602011771号
浙公网安备 33010602011771号