

Hadoop分布式系统的安装部署
1、关于虚拟机的复制
新建一台虚拟机,系统为CentOS7,再克隆两台,组成一个三台机器的小集群。正常情况下一般需要五台机器(一个Name节点,一个SecondName节点,三个Data节点。)
此外,为了使网络生效,需要注意以下几点:
1> 编辑网络配置文件
/etc/sysconfig/network-scripts/ifcfg-eno16777736
先前的版本需要删除mac地址行,注意不是uuid,而是hwaddr,这一点新的CentOS不再需要
2> 删除网卡和mac地址绑定文件
rm -rf /etc/udev/rules.d/70-persistent-net.rules
3> 重启动系统
此外,mapreduce在运行的时候可能会随机开放端口,在CentOS7中,可以使用下面的命令将防火墙关闭
systemctl stop firewalld
或者使用下面的命令,使在集群中的机器可以不受限制的互相访问
#把一个源地址加入白名单,以便允许来自这个源地址的所有连接
firewall-cmd --add-rich-rule 'rule family="ipv4" source address="192.168.1.215" accept' --permanent firewall-cmd --reload
2、将IP地址设置为静态
准备了三个IP地址
192.168.1.215
192.168.1.218
192.168.1.219
在CentOS7下,修改ip地址的文件为/etc/sysconfig/network-scripts/ifcfg-eno16777736
主要作如下设置,其他的不需要变
# none或static表示静态 OOTPROTO=static # 是否随网络服务启动 ONBOOT=yes IPADDR=192.168.1.215 # 子网掩码 NETMASK=255.255.255.0 # 网关,设置自己的 GATEWAY=192.168.0.1 # dns DNS1=202.106.0.20
3、修改hostname与hosts文件
这两个文件均处于系统根目录的etc文件夹之中
下图显示了映射后的机器名称以及对应的ip地址(#localhost.localdomain这一行多余,仅master刚刚好)
主节点master,两个数据节点data1,data2

4、添加用户与组
需要为Hadoop软件系统设置单独的用户和组,本例中新添加的用户和所属组的名称均为hadoop
adduser hadoop passwd hadoop
5、利用ssh实现免密码登录
注意,目的是使Hadoop系统的所属用户在集群之间实现免密码登录,而不是root用户(除非Hadoop系统的所有者root,但一般不建议这么做)。这一点非常重要。
在本例中,软件所有者是上面新建的hadoop用户,密钥也要由hadoop用户来生成。
1> 更改配置文件
需要对sshd_config文件进行修改,主要是以下三项,取消注释即可
vim /etc/ssh/sshd_config
RSAAuthentication yes
PubkeyAuthentication yes
AuthorizedKeysFile .ssh/authorized_keys
之后,执行以下命令重启sshd服务
service sshd restart
2> 生成密钥并分发相关文件
简单的方法,密钥生成后,使用直接使用 ssh-copy-id 命令把密钥追加到远程主机的 .ssh/authorized_key 上,如下:
# 生成密钥
ssh-keygen -t rsa
# 密钥追加到远程主机
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@192.168.1.218
ssh-copy-id -i ~/.ssh/id_rsa.pub hadoop@data2
复杂的方法,不再推荐,具体实现步骤如下:
a> 将三台计算机(master、data1、data2)分别切换到hadoop用户下,并分别cd到hadoop用户的家目录,然后执行 ssh-keygen -t rsa 命令,这样的结果,是在各自家目录的.ssh文件夹中生成了对应的id_rsa.pub 与id_rsa 密钥对。
b> 将data1(192.168.1.218),data2(192.168.1.219)两台计算机中的公钥文件复制到master(192.168.1.215)中,并重命名为id_rsa.pub218,id_rsa.pub219,置于hadoop用户家目录下的.ssh文件夹下。命令参考如下:
scp id_rsa.pub hadoop@master:~/.ssh/id_rsa.pub218 scp id_rsa.pub hadoop@master:~/.ssh/id_rsa.pub219
hadoop@master表示用master中的hadoop用户登录master
这样以来,master主机hadoop用户的.ssh文件夹就有了以下三个公钥文件:
d_rsa.pub、d_rsa.pub218、d_rsa.pub218
c> 在master中,将以上三个文件以追加的形式写入authorized_keys文件,这些文件均位于hadoop用户.ssh文件夹中。
cat id_rsa.pub >> authorized_keys cat id_rsa.pub218 >> authorized_keys cat id_rsa.pub219 >> authorized_keys
d> 更改 authorized_keys 文件的权限。这一步也可在分发后单独进行。
chmod 600 authorized_keys
e> 分发authorized_keys 文件到data1,data2中hadoop用户的.ssh文件中,并再次检查权限。
scp authorized_keys hadoop@data1:~/.ssh/authorized_keys scp authorized_keys hadoop@data2:~/.ssh/authorized_keys
之后就可以在小集群中使用hadoop用户实现免密码登录了。
注意的是,如果使用的linux登录用户不是root用户,需要修改以下.ssh文件夹以及authorized_key文件的权限,否则是无法实现免密码登录的
chmod 700 .ssh cd .ssh/ chmod 600 authorized_keys
6、安装jdk
先在master中安装,之后分发,这里使用的是jdk-8u112-linux-x64.tar.gz
1> 解压安装
首先需要切换到root用户
su root cd /usr mkdir java tar -zxvf jdk-8u112-linux-x64.tar.gz ./java ln -s jdk1.8.0_112/ jdk
2> 分发
scp -r /usr/java root@data2:/usr/ scp -r /usr/java root@data2:/usr/
3> 设置环境变量,三台都要设置
vim /etc/profile
export JAVA_HOME=/usr/java/jdk export JRE_HOME=/usr/java/jdk/jre export CLASSPATH=.:$CLASSPATH:$JAVA_HOME/lib:$JRE_HOME/lib export PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
source /etc/profile

7、安装hadoop
先在master下安装,再分发
安装的版本为2.6.5解压安装到/usr/Apache/目录下,并建立软连接
Hadoop所有配置文件的目录位于/usr/Apache/hadoop-2.6.5/etc/hadoop下,由于建立了一个软连接,所以/usr/Apache/hadoop/etc/hadoop是一样的
在hadoop软件目录的dfs文件夹中创建三个子文件夹name、data、tmp,下面属性的设置会用到,注意其所有者和所属组。
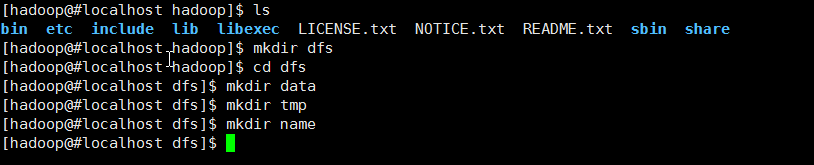
以下是配置文件的设置:
1> hdfs.site.xml
<property> <name>dfs.namenode.name.dir</name> <value>file:/usr/Apache/hadoop/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/Apache/hadoop/dfs/data</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.namenode.secondary.http-address</name> <value>master:50090</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property>
2> mapred-site.xml
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>master:19888</value> </property>
3> yarn-site.xml
设置如下:
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>master:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>master:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>master:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>master:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>master:8088</value> </property>
4> slaves配置文件
master
data1
data2
注:本例将master也作为了一个数据节点
5> hadoop-env.sh和yarn-env.sh
这是两个相当重要的环境变量配置文件,由于目前仅安装Hadoop,所以仅设置jdk即可,其他默认。
export JAVA_HOME=/usr/java/jdk
6> core-site.xml
<property> <name>hadoop.tmp.dir</name> <value>/usr/Apache/hadoop/tmp</value> <description>A base for other temporary directories.</description> </property> <property> <name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property>
7> 将Apache文件夹分发到data1,data2对应的目录下
# 分发 scp -r ./Apache root@data1:/usr/ scp -r ./Apache root@data2:/usr/ # 这里使用了root用户,记得分发后要改所有者与所属组 chown -R hadoop:hadoop Apache/
注意jdk是不需要改所有者与所属组的,因为通用
8> 三台机器分别配置hadoop用户的.bashrc文件,设置环境变量
su hadoop vim ~/.bashrc
export $HADOOP_HOME=/usr/Apache/hadoop export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_YARN_HOME=$HADOOP_HOME export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export CLASSPATH=.:$HADOOP_HOME/lib:$CLASSPATH export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
source ~/.bashrc
8、开启与结束
start-dfs.sh
start-yarn.sh
mr-jobhistory-daemon.sh start historyserver
yarn-daemon.sh start historyserver
#####
stop-dfs.sh
stop-yarn.sh
mr-jobhistory-daemon.sh stop historyserver
yarn-daemon.sh stop historyserver
9、运行结果
相关进程


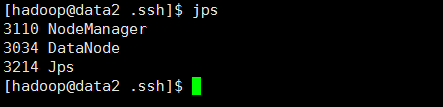
All Applications
http://192.168.1.215:8088
JobHistory
http://192.168.1.215:19888
Master
http://192.168.1.215:50070


 浙公网安备 33010602011771号
浙公网安备 33010602011771号