
MapRedue开发实例
一些例子,所用版本为hadoop 2.6.5
1、统计字数
数据格式如下(单词,频数,以tab分开):
A 100 B 97 C 98
A 98
1 package com.mr.test; 2 3 import java.io.IOException; 4 import org.apache.hadoop.conf.Configuration; 5 import org.apache.hadoop.fs.Path; 6 import org.apache.hadoop.io.IntWritable; 7 import org.apache.hadoop.io.Text; 8 import org.apache.hadoop.mapreduce.Job; 9 import org.apache.hadoop.mapreduce.Mapper; 10 import org.apache.hadoop.mapreduce.Reducer; 11 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 12 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 13 14 public class MRTest { 15 16 public static class C01Mapper extends Mapper<Object, Text, Text, IntWritable> { 17 18 @Override 19 public void map(Object key, Text value, Context context) throws IOException, InterruptedException { 20 String[] line = value.toString().split("\t"); 21 if(line.length == 2) { 22 context.write(new Text(line[0]),new IntWritable(Integer.parseInt(line[1]))); 23 } 24 } 25 } 26 27 public static class C01Reducer extends Reducer<Text, IntWritable, Text, IntWritable> { 28 29 @Override 30 public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { 31 int i =0; 32 for(IntWritable value : values){ 33 i += value.get(); 34 } 35 context.write(key, new IntWritable(i)); 36 } 37 } 38 39 public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException { 40 //参数含义: agrs[0]标识 in, agrs[1]标识 out,agrs[2]标识 unitmb,agrs[3]标识 reducer number, 41 42 int unitmb =Integer.valueOf(args[2]); 43 String in = args[0]; 44 String out = args[1]; 45 int nreducer = Integer.valueOf(args[3]); 46 47 Configuration conf = new Configuration(); 48 conf.set("mapreduce.input.fileinputformat.split.maxsize", String.valueOf(unitmb * 1024 * 1024)); 49 conf.set("mapred.min.split.size", String.valueOf(unitmb * 1024 * 1024)); 50 conf.set("mapreduce.input.fileinputformat.split.minsize.per.node", String.valueOf(unitmb * 1024 * 1024)); 51 conf.set("mapreduce.input.fileinputformat.split.minsize.per.rack", String.valueOf(unitmb * 1024 * 1024)); 52 53 Job job = new Job(conf); 54 FileInputFormat.addInputPath(job, new Path(in)); 55 FileOutputFormat.setOutputPath(job, new Path(out)); 56 job.setMapperClass(C01Mapper.class); 57 job.setReducerClass(C01Reducer.class); 58 job.setNumReduceTasks(nreducer); 59 job.setCombinerClass(C01Reducer.class); 60 job.setMapOutputKeyClass(Text.class); 61 job.setMapOutputValueClass(IntWritable.class); 62 job.setOutputKeyClass(Text.class); 63 job.setOutputValueClass(IntWritable.class); 64 job.setJarByClass(MRTest.class); 65 job.waitForCompletion(true); 66 } 67 }
2、统计用户在网站的停留时间
数据格式(用户,毫秒数,网站,以tab分开):
A 100 baidu.com B 900 google.com C 515 sohu.com D 618 sina.com E 791 google.com B 121 baidu.com C 915 google.com D 112 sohu.com E 628 sina.com A 681 google.com C 121 baidu.com D 215 google.com E 812 sohu.com A 128 sina.com B 291 google.com
1 package com.mr.test; 2 3 import java.io.IOException; 4 import org.apache.hadoop.conf.Configuration; 5 import org.apache.hadoop.fs.Path; 6 import org.apache.hadoop.io.IntWritable; 7 import org.apache.hadoop.io.Text; 8 import org.apache.hadoop.io.WritableComparable; 9 import org.apache.hadoop.io.WritableComparator; 10 import org.apache.hadoop.mapreduce.Job; 11 import org.apache.hadoop.mapreduce.Mapper; 12 import org.apache.hadoop.mapreduce.Partitioner; 13 import org.apache.hadoop.mapreduce.Reducer; 14 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 15 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 16 17 public class MRWeb { 18 19 public static class C02Mapper extends Mapper<Object, Text, Text, Text> { 20 @Override 21 public void map(Object key, Text value, Context context) throws IOException, InterruptedException{ 22 String line[] = value.toString().split("\t"); 23 //格式检查 24 if(line.length == 3){ 25 String name = line[0]; 26 String time = line[1]; 27 String website = line[2]; 28 context.write(new Text(name + "\t" + time), new Text(time + "\t" + website)); 29 } 30 } 31 } 32 33 public static class C02Partitioner extends Partitioner<Text, Text> { 34 35 @Override 36 public int getPartition(Text key, Text value, int number) { 37 String name = key.toString().split("\t")[0]; 38 int hash =name.hashCode(); 39 //以此实现分区 40 return Math.abs(hash % number); 41 } 42 43 } 44 45 public static class C02Sort extends WritableComparator { 46 //必须有的 47 protected C02Sort() { 48 super(Text.class,true); 49 } 50 51 @Override 52 public int compare(WritableComparable w1, WritableComparable w2) { 53 Text h1 = new Text(((Text)w1).toString().split("\t")[0] ); 54 Text h2 = new Text(((Text)w2).toString().split("\t")[0] ); 55 IntWritable m1 =new IntWritable(Integer.valueOf(((Text)w1).toString().split("\t")[1])); 56 IntWritable m2 =new IntWritable(Integer.valueOf(((Text)w2).toString().split("\t")[1])); 57 58 int result; 59 if(h1.equals(h2)){ 60 result = m2.compareTo(m1); 61 }else { 62 result =h1.compareTo(h2); 63 } 64 return result; 65 } 66 } 67 68 public static class C02Group extends WritableComparator{ 69 protected C02Group() { 70 super(Text.class,true); 71 } 72 @Override 73 public int compare(WritableComparable w1, WritableComparable w2) { 74 Text h1 = new Text(((Text)w1).toString().split("\t")[0] ); 75 Text h2 = new Text(((Text)w2).toString().split("\t")[0] ); 76 77 return h1.compareTo(h2); 78 } 79 } 80 81 public static class C02Reducer extends Reducer<Text, Text, IntWritable, Text> { 82 83 @Override 84 protected void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException { 85 int count = 0; 86 String name =key.toString().split("\t")[0]; 87 //分组排序已经做好了,这里只管打印 88 for(Text value : values){ 89 count++; 90 StringBuffer buffer = new StringBuffer(); 91 buffer.append(name); 92 buffer.append("\t"); 93 buffer.append(value.toString()); 94 context.write(new IntWritable(count), new Text(buffer.toString())); 95 } 96 } 97 } 98 99 public static void main(String[] args) throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException { 100 //参数含义: agrs[0]标识 in, agrs[1]标识 out,agrs[2]标识 unitmb,agrs[3]标识 reducer number, 101 if(args.length != 4){ 102 System.out.println("error"); 103 System.exit(0); 104 } 105 106 int unitmb =Integer.valueOf(args[2]); 107 String in = args[0]; 108 String out = args[1]; 109 int nreducer = Integer.valueOf(args[3]); 110 111 Configuration conf = new Configuration(); 112 conf.set("mapreduce.input.fileinputformat.split.maxsize", String.valueOf(unitmb * 1024 * 1024)); 113 conf.set("mapred.min.split.size", String.valueOf(unitmb * 1024 * 1024)); 114 conf.set("mapreduce.input.fileinputformat.split.minsize.per.node", String.valueOf(unitmb * 1024 * 1024)); 115 conf.set("mapreduce.input.fileinputformat.split.minsize.per.rack", String.valueOf(unitmb * 1024 * 1024)); 116 117 Job job = new Job(conf); 118 FileInputFormat.addInputPath(job, new Path(in)); 119 FileOutputFormat.setOutputPath(job, new Path(out)); 120 job.setMapperClass(C02Mapper.class); 121 job.setReducerClass(C02Reducer.class); 122 job.setNumReduceTasks(nreducer); 123 job.setPartitionerClass(C02Partitioner.class); 124 job.setGroupingComparatorClass(C02Group.class); 125 job.setSortComparatorClass(C02Sort.class); 126 job.setMapOutputKeyClass(Text.class); 127 job.setMapOutputValueClass(Text.class); 128 job.setOutputKeyClass(IntWritable.class); 129 job.setOutputValueClass(Text.class); 130 job.setJarByClass(MRWeb.class); 131 job.waitForCompletion(true); 132 } 133 }
运行:hadoop jar ~/c02mrtest.jar com.mr.test.MRWeb TestData/webcount.txt /DataWorld/webresult 128 1
结果的样子:
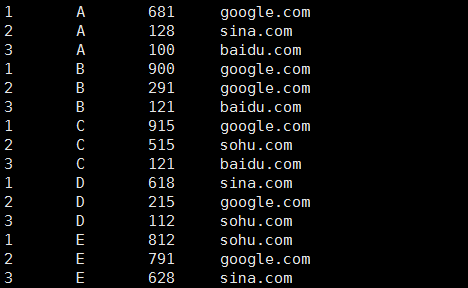
3、json数组分析
数据格式(前面以tab分开):
1 [{"name":"A","age":16,"maths":100}]
2 [{"name":"B","age":17,"maths":97}]
3 [{"name":"C","age":18,"maths":89}]
4 [{"name":"D","age":15,"maths":98}]
5 [{"name":"E","age":19,"maths":100}]
1 package com.mr.test; 2 3 import java.io.IOException; 4 import org.apache.hadoop.conf.Configuration; 5 import org.apache.hadoop.fs.Path; 6 import org.apache.hadoop.io.Text; 7 import org.apache.hadoop.mapreduce.Job; 8 import org.apache.hadoop.mapreduce.Mapper; 9 import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; 10 import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; 11 import net.sf.json.JSONArray; 12 import net.sf.json.JSONObject; 13 14 public class MRString { 15 16 public static class C03Mapper extends Mapper<Object, Text, Text, Text> { 17 @Override 18 protected void map(Object key, Text value, Mapper<Object, Text, Text, Text>.Context context) 19 throws IOException, InterruptedException { 20 String[] line = value.toString().split("\t"); 21 if(line.length ==2){ 22 String c = line[0]; 23 String j = line[1]; 24 JSONArray jsonArray =JSONArray.fromObject(j); 25 int size = jsonArray.size(); 26 for(int i=0;i<size;i++){ 27 String name = ""; 28 String age = ""; 29 String maths = ""; 30 JSONObject jsonObject =jsonArray.getJSONObject(i); 31 if(jsonObject.containsKey("name")){ 32 name = jsonObject.getString("name"); 33 } 34 if(jsonObject.containsKey("age")){ 35 age = jsonObject.getString("age"); 36 } 37 if(jsonObject.containsKey("maths")){ 38 maths = jsonObject.getString("maths"); 39 } 40 StringBuffer buffer =new StringBuffer(); 41 buffer.append(name); 42 buffer.append("\t"); 43 buffer.append(age); 44 buffer.append("\t"); 45 buffer.append(maths); 46 context.write(new Text(c), new Text(buffer.toString())); 47 } 48 } 49 } 50 } 51 52 public static void main(String[] args) throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException { 53 //参数含义: agrs[0]标识 in, agrs[1]标识 out,agrs[2]标识 unitmb,agrs[3] 54 if(args.length != 3){ 55 System.out.println("error"); 56 System.exit(0); 57 } 58 59 int unitmb =Integer.valueOf(args[2]); 60 String in = args[0]; 61 String out = args[1]; 62 63 Configuration conf = new Configuration(); 64 conf.set("mapreduce.input.fileinputformat.split.maxsize", String.valueOf(unitmb * 1024 * 1024)); 65 conf.set("mapred.min.split.size", String.valueOf(unitmb * 1024 * 1024)); 66 conf.set("mapreduce.input.fileinputformat.split.minsize.per.node", String.valueOf(unitmb * 1024 * 1024)); 67 conf.set("mapreduce.input.fileinputformat.split.minsize.per.rack", String.valueOf(unitmb * 1024 * 1024)); 68 69 Job job = new Job(conf); 70 job.addFileToClassPath(new Path("TestData/json-lib-2.4-jdk15.jar")); 71 job.addFileToClassPath(new Path("TestData/ezmorph-1.0.6.jar")); 72 FileInputFormat.addInputPath(job, new Path(in)); 73 FileOutputFormat.setOutputPath(job, new Path(out)); 74 job.setMapperClass(C03Mapper.class); 75 //没有reducer的情况下必须设置 76 job.setNumReduceTasks(0); 77 job.setMapOutputKeyClass(Text.class); 78 job.setMapOutputValueClass(Text.class); 79 job.setOutputKeyClass(Text.class); 80 job.setOutputValueClass(Text.class); 81 job.setJarByClass(MRString.class); 82 job.waitForCompletion(true); 83 } 84 }
运行 hadoop jar ~/c03mrtest.jar com.mr.test.MRString TestData/jsonarray.txt /DataWorld/jsonoutput 128
结果:

这个例子还有一点值得注意(Path中的目录是HDFS中的目录):
job.addFileToClassPath(new Path("TestData/json-lib-2.4-jdk15.jar")); //jar文件下载地址:http://json-lib.sourceforge.net/
job.addFileToClassPath(new Path("TestData/ezmorph-1.0.6.jar")); //jar文件下载地址:http://ezmorph.sourceforge.net/
使用这两句,在程序中动态添加了用于json解析的jar文件,而利用服务器中的ClassPath是访问不到这两个文件的。在编程的时候,在windows客户端下,为了语法书写方便,导入了json-lib-2.4-jdk15.jar,但是并没有导入ezmorph-1.0.6.jar 。
也就是说,可以在程序中动态的加入jar文件,只要知道了它在HDFS中的位置。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号