ClickHouse应用之留存分析
留存
对于数据分析师和运营人员来说,留存分析这几个字并不陌生,通过观察其留存规律,在用户行为领域,通过数据分析方法的科学应用,经过理论推导,能够相对完整地揭示用户行为的内在规律。基于此帮助企业实现多维交叉分析,帮助企业建立快速反应、适应变化的敏捷商业智能决策。最近一直在做关于留存分析项目,下面就我自己的经验,来谈一下如何在hive和clickhouse中计算留存,着重突出在clickhouse中留存的计算方式,在这之前先回顾一下留存的基本定义。
留存分析是一种用来分析用户参与情况/活跃程度的分析模型,考察进行初始行为的用户中,有多少人会进行后续行为。这是用来衡量产品对用户价值高低的重要方法。
留存分析可以帮助回答以下问题:
-
一个新客户在未来的一段时间内是否完成了您期许用户完成的行为?如支付订单等;
-
某个社交产品改进了新注册用户的引导流程,期待改善用户注册后的参与程度,如何验证?
-
想判断某项产品改动是否奏效,如新增了一个邀请好友的功能,观察是否有人因新增功能而多使用产品几个月。
通过观察一段时间内留存规律,进而获取这一段时间内进行了留存事件的用户,来对这些留存人群进行一定的营销策略。
通过我们在求留存时,一般只求次日留存,三日留存,7日留存,15日留存,30留存,次日留存即是指在某一天活跃(或注册)的用户在活跃日(或注册日)的第二天仍然有活跃,这一部分留下的用户即是次日留存用户群体,次日留存用户群体的基数即为次日留存数。同样的三日、五日、7日、15日、30日都是同样的含义。
一般来讲,我们所说的N日留存即第N天仍活跃的用户,但是其他两种概念的留存,即连续N天内留存和N天内留存,连续N天内留存即连续N天内均有活跃的用户,N天内即指N天内活跃过的用户,前者的留存数会越来越小,后者会越来越大,用户最多的则是第N天活跃的用户。按照不同的应用场景来选择不同的留存类型。
计算留存
从上面留存的定义来看,在计算留存的时候需要将当天的数据和之前的数据关联起来,例要求2021-07-30的三日留存,即需要将7.30号的数据和8.2号的数据关联一起,正常来说利用如下sql来求解。通过inner join 将两天的用户关联起来,这些虽然也可以求出来,但是这样有个弊端就是如果是要一次性求次日、3日、5日、7日、15日、30日留存,那得join到什么时候去,而且这样的sql性能上面巨差。因此不采用这种写法。
select
t1.uid
from
origin_table as t1
inner join
origin_table as t2
on t1.uid = t2.uid
where t1.order_date = '2021-08-02'
and t2.order_date = '2021-07-30'
借助dateDiff来求第N天留存
鉴于上面的情况,我们采用新的方法来求留存,这种留存计算方法主要是通过求取用户之前出现的日期与之后出现日期的差值,则可以判断该用户是否为某天的N日留存,若某用户在7.1号出现,此使该用户则是7.1号的活跃用户,若该用户7.2号又出现了,则此时前后两次出现的日期差为1天,则可以确定为该用户为7.1号的留存用户,若该用户在7.3号又出现了,则该用户为7.1的2日留存用户,下面利用具体的实例来进行说明介绍,以clickhouse数据库举例说明,在clickhouse中建如下表:
CREATE TABLE login_log
(
`uid` Int32,
`login_time` DateTime
)
ENGINE = MergeTree
PARTITION BY uid
ORDER BY uid
;
往上面表中塞入一些数据,如下所示,4个用户的登录活跃情况。

要计算两个日期的datediff,我们首先login_log表进行子连接,其中一张作为"初始表",一张作为"留存表",通过子连接,则可以将该用户前后出现的日期连接起来,具体逻辑如下:
select a.uid, a.log_date t1, b.log_date t2
from (
SELECT distinct uid,
toDate(login_time) as log_date
from login_log
) a
inner join (
SELECT distinct uid,
toDate(login_time) as log_date
from login_log
) b
on a.uid = b.uid
where a.log_date <= b.log_date
就拿其中一个用户来说,如下图所示,用户2201,在6.20、6.21号出现过,t1列表示2201用户活跃的时间,t2表示该用户在t1活跃之后出现过的日期。
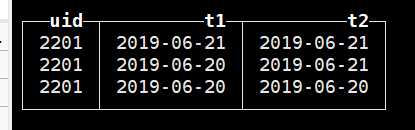
有了上述两列,下面则利用上面的结果求日期差:
select *, dateDiff('day',tab1.t1,tab1.t2) as diff
from
(
select a.uid, a.log_date t1, b.log_date t2
from (
SELECT distinct uid,
toDate(login_time) as log_date
from login_log
) a
inner join (
SELECT distinct uid,
toDate(login_time) as log_date
from login_log
) b
on a.uid = b.uid
where a.log_date <= b.log_date
) tab1
;
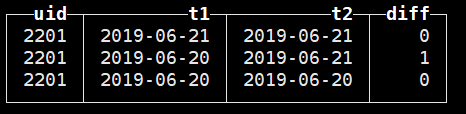
按照之前所说的,日期差=0,表示用户2201是6.20号和6.21号的当天活跃用户,日期=1表示2201用户是6.20号的次日留存用户。基于对于diff的分类,则可求出每一天的当天活跃用户以及第N日留存用户数。
select tab2.t1,
count(distinct case when diff = 0 then tab2.uid else null end) as activity_cnt,
count(distinct case when diff = 1 then tab2.uid else null end) as after_uid_cnt_1,
count(distinct case when diff = 3 then tab2.uid else null end) as after_uid_cnt_3,
count(distinct case when diff = 5 then tab2.uid else null end) as after_uid_cnt_5,
count(distinct case when diff = 7 then tab2.uid else null end) as after_uid_cnt_7,
count(distinct case when diff = 15 then tab2.uid else null end) as after_uid_cnt_15,
count(distinct case when diff = 30 then tab2.uid else null end) as after_uid_cnt_30
from (
select *, dateDiff('day', tab1.t1, tab1.t2) as diff -- 这个地方求日期差的写法是clickhouse中的,hive中联合这三个函数from_unixtime,unix_timestamp,datediff进行计算
from (
select a.uid, a.log_date t1, b.log_date t2
from (
SELECT distinct uid,
toDate(login_time) as log_date
from login_log
) a
inner join (
SELECT distinct uid,
toDate(login_time) as log_date
from login_log
) b
on a.uid = b.uid
where a.log_date <= b.log_date
) tab1
) tab2
group by tab2.t1
;
通过上面逻辑,可以得到如下留存结果,从下图中,可以得知20号当天的活跃用户数为3,核对原始数据(图1)可以发现,6.20当天的活跃用户数为3分别是1101、2201、4401,其次日留存即在6.20号和6.21号均活跃的用户,通过核对发现只有两个用户其是1101 、2201,通过比对其他日期可以发现,这种算法是正确的。而且利用datediff这样求留存要比最上面所说的left join要快速有效。

上面这种计算的思路,只要是个数据库均可以实现,要比动辄就要left join好多次的逻辑要快很多,但是我们还需要注意的是,此使还是left join了一次,多于大表来说还是比较影响性能的。但是对于接触过clickhouse的小伙伴来说,应该知道clickhouse支持复杂的数据类型,比如array、bitmap等,因此利用clickhouse的这些特有函数可以提升查询性能,而且本身clickhouse就是列式存储的其查询的性能要比其他数据库要快很多。下面就clickhouse自带的一些函数来计算留存。
利用Retention函数
retention该函数将一组条件作为参数,类型为1到32个 UInt8 类型的参数,用来表示事件是否满足特定条件。任何条件都可以指定为参数(如
语法:
retention(cond1, cond2, ..., cond32);
继续利用上面的例子来谈谈retention的应用,利用retention来求2019-06-20号的当天活跃用户、次日留存。首先,利用retention函数进行日期判断,要求2019-06-20号的当天活跃用户以及次日留存数,则对于用户判断其活跃日期是否等于2029-06-20,活跃日期+1是否等于2019-06-20
SELECT uid,
retention(
toDate(login_time) = '2019-06-20',
toDate(login_time) = '2019-06-21'
) as arr
FROM login_log
GROUP BY uid
;
通过上面sql可以查到如下结果,arr是一个数组,其第一位表示,该用户是否在2019-06-20号活跃,1表示活跃过,0表示未活跃,第二位表示,该用户是否在2019-06-21号活跃过,从该结果可以发现在2019-06-20号出现过的用户有1101、2201、4401三个用户,在2019-06-21号出现过的用户为1101、2201,从原始数据我们可以发现3301在21号有出现过,但是这个地方为0,其主要是3301用户并未在20号出现过,第一个条件非真,因此第二位也非真,因此此处为0。
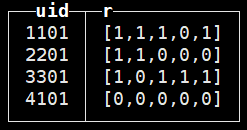
继续上面的结果来求留存,
SELECT sum(arr[1]) as active_user,
sum(arr[2]) as day_after_1
FROM
(
SELECT uid,
retention(
toDate(login_time) = '2019-06-20',
toDate(login_time) = '2019-06-21'
) as arr
FROM login_log
GROUP BY uid
) a
;

可以发现结果利用datediff求的一致,但是这样相比较上面的一个缺点是不能够把每一天的留存结果一次性得到(也可能是我没找到方法😂),如果计算留存的时候还有一些条件,在retention的每一位添加即可。
利用retention来求留存的方法,其说到底是利用了clickhouse中数据这一结构,因此,灵活的应用这一数据结构。
利用array系列函数求留存
利用arrayMap
Step1: 获取每一个用户出现的日期
SELECT distinct uid,
groupArray(distinct toDate(login_time)) AS arr
FROM login_log
group by uid
;
这一步出现的结果就是图1,此使再不赘述。
Step2: arrayMap判断日期
语法
arrayMap(fun,arr)
arrayMap对数组arr中的每一个元素应用fun操作,例arrayMap(x-> x *10,arr)即使对数组arr中的每一个元素乘以10,其和python中的map是一个性质。利用arrayMap来判断该用户是否在相应的日期活跃。
select uid,
stat_time,
arrayMap(x -> x = addDays(stat_time, 1), arr) as day_1_un,
arrayMap(x -> x = addDays(stat_time, 3), arr) as day_3_un,
arrayMap(x -> x = addDays(stat_time, 5), arr) as day_5_un,
arrayMap(x -> x = addDays(stat_time, 7), arr) as day_7_un,
arrayMap(x -> x = addDays(stat_time, 15), arr) as day_15_un,
arrayMap(x -> x = addDays(stat_time, 30), arr) as day_30_un
from (
SELECT distinct uid,
groupArray(distinct toDate(login_time)) AS arr
FROM login_log
group by uid
) t1 array join arr as stat_time
group by uid, stat_time, arr
order by uid
;
同样的,来看一下用户2201在stat_time = 2019-06-20号的结果,day_1_un的结果为[1,0],元素1表示用户在21号有活跃,元素0表示用户在22号没有出现过。用户2201在stat_time=2019-06-21号的结果,day_1_un的结果为[0,0],第一个元素0表示该用户在22号没有出现过,第二个0表示该用户在23号也未出现过。总感觉这个地方多计算了一些东西😂,但是不重要,最终结果是对的。

Step3: 结果汇总
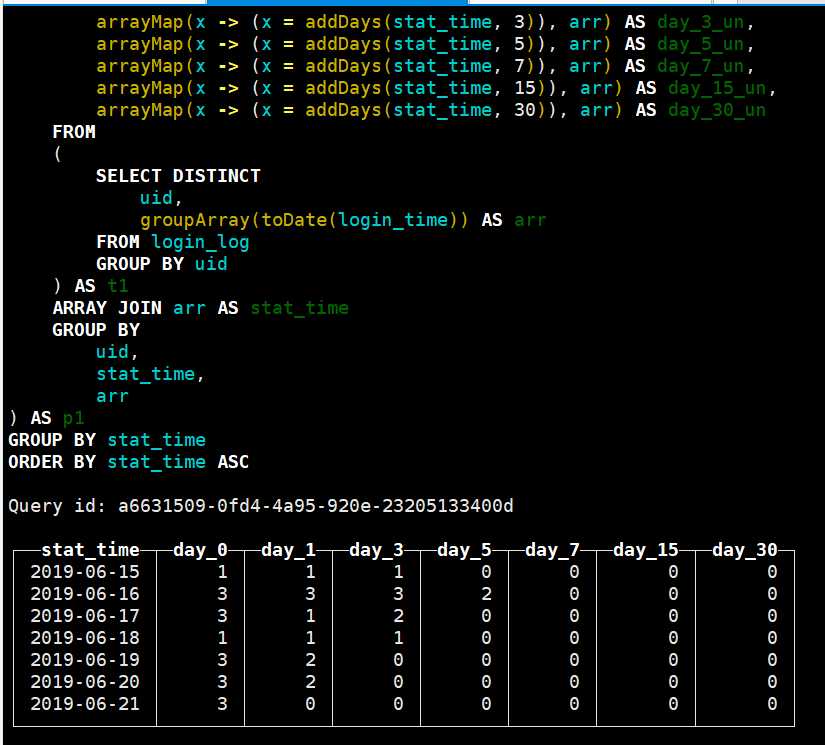
最终按照stat_time进行GROUP BY, 要求次日留存,则是sumday_1_un中元素1的个数即可,其他第N天留存同理。通过下图可以发现和之前的结果是一致的。
select
stat_time,
uniq(uid) as day_0,
uniq(case when has(day_1_un, 1) then uid end) as day_1,
uniq(case when has(day_3_un, 1) then uid end) as day_3,
uniq(case when has(day_5_un, 1) then uid end) as day_5,
uniq(case when has(day_7_un, 1) then uid end) as day_7,
uniq(case when has(day_15_un, 1) then uid end) as day_15,
uniq(case when has(day_30_un, 1) then uid end) as day_30
from (
select uid,
stat_time,
arrayMap(x -> x = addDays(stat_time, 1), arr) as day_1_un,
arrayMap(x -> x = addDays(stat_time, 3), arr) as day_3_un,
arrayMap(x -> x = addDays(stat_time, 5), arr) as day_5_un,
arrayMap(x -> x = addDays(stat_time, 7), arr) as day_7_un,
arrayMap(x -> x = addDays(stat_time, 15), arr) as day_15_un,
arrayMap(x -> x = addDays(stat_time, 30), arr) as day_30_un
from (
SELECT distinct uid,
groupArray(toDate(login_time)) AS arr
FROM login_log
group by uid
) t1 array join arr as stat_time
group by uid, stat_time, arr
) p1
group by stat_time
order by stat_time
;
利用arrayIntersect
arrayIntersect
语法
arrayIntersect(array1,array2,array3,....)
-- 用来求多个数组之间的交集
求第N天留存
同样,这里地方,我们利用arrayIntersect来求2019-06-20的次日留存,逻辑如下:
with source as (
select toDate(login_time) as stat_time,
groupArray(distinct uid) as user_arr
from login_log
group by stat_time
)
select arrayIntersect(
(select user_arr
from source
where
stat_time = '2019-06-20'),
(select
user_arr
from source
where
stat_time = '2019-06-21')) as day_1_un
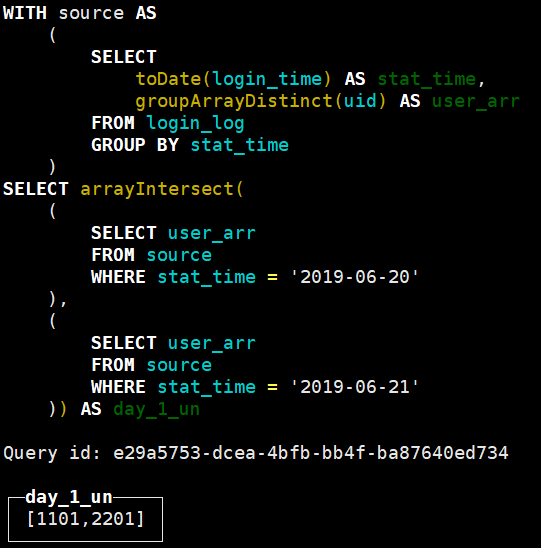
如图所示得到了06-20号的次日留存用户为1101、2201,这个结果和之前其他方法求的是统一结果。最终对于arrayIntersect应用length即可得到相应的留存数。利用arrayIntersect求多天的留存则需要不断地union。不过也可以参考一下,有的时候还是有用的。
求连续N天留存
连续N天留存和第N天不一样的点是,只需求连续N天的用户的交集即可。同样针对上面的例子,来求2019-06-19和2019-06-20号的连续2天留存,连续1天留存
with source as (
select toDate(login_time) as stat_time,
groupArray(distinct uid) as user_arr
from login_log
group by stat_time
)
select
arrayIntersect(
(select user_arr
from
source
where stat_time = '2019-06-19'),
(select user_arr
from
source
where stat_time = '2019-06-19')) as day_0_un,
arrayIntersect(
(select user_arr
from source
where
stat_time = '2019-06-19'),
(select user_arr
from source
where
stat_time = '2019-06-20')) as day_1_un,
arrayIntersect(
(select user_arr
from source
where
stat_time = '2019-06-19'),
(select user_arr
from source
where
stat_time = '2019-06-20'),
(select user_arr
from source
where
stat_time = '2019-06-21')) as day_2_un
按照上述逻辑求得如下结果,day_0_un表示所求日期当天活跃用户,day_1_un为连续留存1天用户,day_2_un为连续留存2天用户。下图所示的两张结果图中,第一张为19号的连续2天的留存结果,第二为20号的留存结果。从下图的结果可以看到留存结果越来越小。


N天内留存
N天内留存,即N天之内的活跃用户都算在内。示例如下:
with source as (
select toDate(login_time) as stat_time,
groupArray(distinct uid) as user_arr
from login_log
group by stat_time
)
select arrayIntersect(
(select user_arr
from source
where stat_time = '2019-06-19'),
(select user_arr
from source
where stat_time = '2019-06-19')) as day_0_un,
arrayIntersect(arrayConcat(
(select user_arr
from source
where stat_time = '2019-06-19'),
(select user_arr
from source
where stat_time = '2019-06-20'))) as day_1_un,
arrayIntersect(arrayConcat(
arrayConcat(
(select user_arr
from source
where stat_time = '2019-06-19'),
(select user_arr
from source
where stat_time = '2019-06-20'),
arrayConcat(
(select user_arr
from source
where stat_time = '2019-06-19'),
(select user_arr
from source
where stat_time = '2019-06-21')))))
as day_2_un

终于搞完了,期待我的下一篇随笔吧!!!

