性能优化
性能的目标
跑得更快吗?是用更少的资源跑得更快。如果不能兼得,我们通常选择跑得更快,这也是大多数时候性能优化的目的,也有些时候性能优化是为了减少资源消耗。
系统性能的定义
1.吞吐量,系统每s能处理的请求数、任务数
2.时延,系统处理一个请求或者任务的耗时
3.并发数,次级指标,同时接入的客户端数量有时也会成为一个考核指标,一般的后台服务会要求支持100-1000区间的并发连接数,而网站会要求支持10K甚至更大的并发数。
时延和吞吐量往往呈现某种正比关系,吞吐量越高,时延趋于越大,当请求超过系统处理能力时,时延趋于无限大。
并且根据实际经验,时延不会是一个稳定的值,而是一个波动范围,计算吞吐量需要计算区间以及百分比
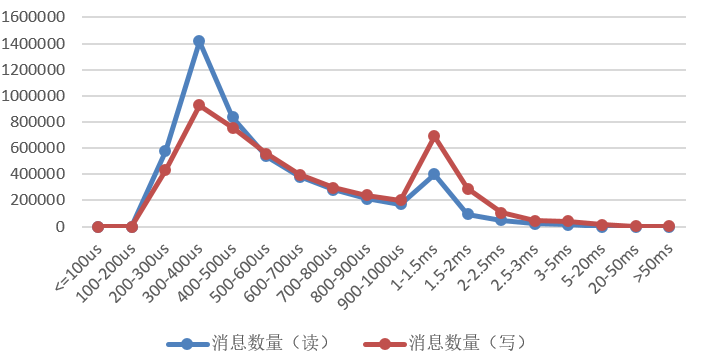
提高吞吐量,时延区间从400us随之增大
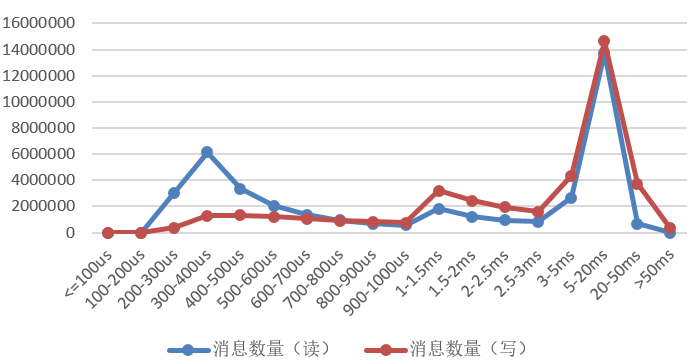
更严重的是,当吞吐量达到一定程度,延迟将会剧烈抖动,出现超长时延,如上图的>50ms.
系统性能测试
收集吞吐量和时延
延迟:每个系统都是有硬性要求的,网站可能是1S-5S,后台系统比如消息队列,可能是100us-5ms之间。
测试工具:调整并发数来模拟不同的吞吐量和时延
在测量延迟的时候,既然延迟是一个区间,我们就需要用百分比来衡量,比如60%以上的时延在1-3ms区间,允许小于2%的大于3ms,一旦不满足任何一个百分比区间,都说明系统还需要优化,case是无效的。
性能测试也要经得起时间考验,一个程序只能高速运行10分钟,之后就拖垮了cpu和内存,那是没有意义的。设计良好的程序在运行1天、1周、1月、1季度、1年后仍应保持一样的效率。
定位性能瓶颈
1.定位操作系统的负载,如果操作系统的网络、磁盘、cpu、内存出现了巨量占用或者不稳定,这时候定位我们的程序是没有用的。linux下可以使用nmon追踪cpu、网络、磁盘、内存的占用率,这个需要先生成文件,是否分析,也可以通过iostat、vmstat、top、tcpdump等查看实时的占用率。
cpu利用率,cpu利用率不高,说明程序忙于做其他的一些事情。
io,io和cpu利用率一般是相反的,如果cpu利用率无法提高,说明程序往往在忙于做其他的事情,比如io,磁盘io或者网络io。
磁盘io影响程序的原因一般有:io吞吐量过大,多线程/多进程IO,同步/阻塞IO。
解决io对程序的影响可以添加或者更换更大吞吐量的磁盘和网卡,降低程序产生io数据的速率(比如降低日志级别,压缩后再输出),降低io同步的频率(减少fflush到磁盘的频率,改为1s一次),采用bio机制(把fflush和close这些会阻塞程序的调用通过队列放到一个bio线程来完成),合并io(同一主机的日志都写入到共享内存,由一个子系统日志server负责日志的落地)
如果cpu、io、内存、网络都不高,那程序设计存在问题,最典型的是程序存在单点瓶颈,尝试把单点瓶颈并行化,也有可能是通信队列和互斥资源采用了粗粒度的锁,细化粒度减少冲突发生的概率。
2.定位程序的瓶颈
添加日志来定位瓶颈,找出程序中调用频繁且耗时久、单点运行且性能低下的
如果程序存在单点瓶颈,简化单点瓶颈的工作量或者尝试并行化处理,并行化的过程虽然会带来互斥的额外开销,但可以通过细化粒度降低对性能的影响。
具体的措施:数据库提取数据的接口使用流水线接口,一次提取10-1000条数据,减少网络RTT的时延;串行的单点瓶颈改为并行的程序;粗粒度的消息队列改成细粒度的;io改成异步模式;轮询的io或者多个io读写改成epoll的多路复用检测状态。关键数据使用缓存服务,使用redis远程缓存、静态数据且多个程序调用缓存到共享内存,小量数据缓存到内存中。
使用性能检测工具来定位,寻找最频繁的调用和耗时来优化
使用inline或者宏替换函数调用,对于非常频繁的调用也有不可忽视的性能提升
使用排好序的数据结构,帮助cpu做预判,也能提升性能

