理论小笔记
平常一般用markdown写博客,最近翻出这篇古早博客就懒得改了,凑活着看吧QAQ。
看这里看这里!
关于几个类型的范围
int -2147483647-2147483648 -2^31~2^31-1
long -2147483647~2147483648 -2^31~2^31-1 (和int相等)
unsigned long long 0~18446744073709551615 0~2^64-1
unsigned int 0~4294967295 0~2^32-1
unsigned long 0~4294967295 0~2^32-1
long long的最大值: -9223372036854775808 ~ 9223372036854775807 -2^63,2^63-1
0x3f3f3f3f与0x7fffffff的意义
当使用min等函数的时候,会需要定义无穷大。一般会有两个选择:0x7fffffff和0x3f3f3f3f
- 0x7fffffff
首先了解数字的含义,"0x"是一个前缀,表示十六进制。
而"7"在二进制中是7的二进制码为 0111,f是指1111。
这样, 0x7FFFFFFF 的二进制表示就是除了符号位是 0表示正数,其余都是1。
对于int而言,0x7fffffff是最大的数值。
所以可以把需要比较的无穷大设为0x7fffffff再进行比较。
- 0x3f3f3f3f
在实际写代码的时候,有的时候并不会出现接近于2^31这样的数值,因此可以把无穷大设得小一点,一般设为0x3f3f3f3f。
0x3f3f3f3f的数值为1061109567,它的两倍也只有2122219134,不会溢出。
这样就有一个好处,当两个无穷大相加的时候可以使int型整数不溢出,并使数值仍为无穷大。
而使用0x3f3f3f3f在对于数组定义的时候也比较方便,一般数组批量赋值时会使用memset函数,如果想将一个数组全部定义为"无穷大"的0x3f3f3f3f,因为memset函数是对字节进行操作,而0x3f3f3f3f的每个字节都是0x3f,所以可以直接定义为
memset(数组名,0x3f,sizeof(数组名));
特别的,浮点数数组如double,float初始化为正无穷应使用
memeset(数组名,127,sizeof(数组名));
数组初始化(memset的使用)
同上,数组初始化可以使用memset快速赋值。需要加上#include<string.h>的头文件
例:
memset(arr,0,sizeof(arr));//将arr数组全部赋值为0
这是一般的数组赋值,char型的二维数组也可以使用memset赋值,但是!不能用于int型二维数组的赋值。
为什么?
就像上面说过的,memset中输入的1,相当于转换成了0x01010101,转换成十进制就是16843009,而全赋值为0是允许的。
如何在O(n)时间复杂度中查找第k大元素
比如,4, 2, 5, 12, 3 这样一组数据,第 3 大元素就是 4。
我们选择数组区间 A[0…n-1] 的最后一个元素 A[n-1] 作为 pivot,对数组 A[0…n-1] 原地分区,这样数组就分成了三部分,A[0…p-1]、A[p]、A[p+1…n-1]。
如果 p+1=K,那 A[p] 就是要求解的元素;如果 K>p+1, 说明第 K 大元素出现在 A[p+1…n-1] 区间,我们再按照上面的思路递归地在 A[p+1…n-1] 这个区间内查找。同理,如果 K<p+1,那我们就在 A[0…p-1] 区间查找。
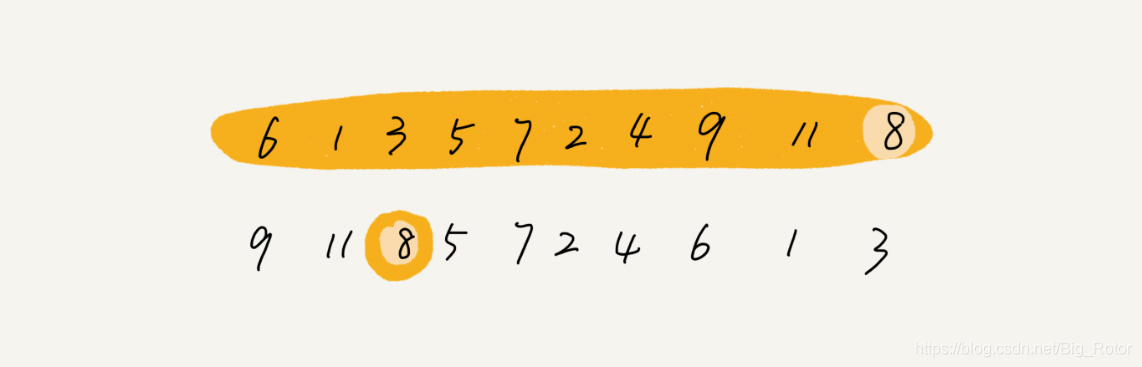
我们再来看,为什么上述解决思路的时间复杂度是 O(n)?
第一次分区查找,我们需要对大小为 n 的数组执行分区操作,需要遍历 n 个元素。第二次分区查找,我们只需要对大小为 n/2 的数组执行分区操作,需要遍历 n/2 个元素。依次类推,分区遍历元素的个数分别为、n/2、n/4、n/8、n/16.……直到区间缩小为 1。
如果我们把每次分区遍历的元素个数加起来,就是:n+n/2+n/4+n/8+…+1。这是一个等比数列求和,最后的和等于 2n-1。所以,上述解决思路的时间复杂度就为 O(n)。
附录:
进制代称
H(Hexadecimal)——16进制
D(Decimal)——10进制
O(Octonary)——8进制
B(Binary)——2进制
占位符类型
%c ASCII 字符
%f 浮点数
%p 指针
%u 无符号十进制整数(unsigned int)
%s 字符串
%d 整数转成十进位
%o 整数转成八进位
%x 整数转成小写十六进位
%X 整数转成大写十六进位
%e 浮点数、e-记数法
%g 自动舍去小数点后多余0
%G 根据数值不同自动选择%f或%e
%i 有符号十进制数(与%d相同)
时间复杂度与空间复杂度
| 排序法 | 最差时间分析 | 平均时间复杂度 | 稳定度 | 空间复杂度 |
| 冒泡排序 | O(n²) | O(n²) | 稳定 | O(1) |
| 快速排序 | O(n²) | O(n*log2n) | 不稳定 | O(log2n)~O(n) |
| 选择排序 | O(n²) | O(n²) | 不稳定 | O(1) |
| 二叉树排序 | O(n²) | O(n*log2n) | 不一定 | O(n) |
| 插入排序 | O(n²) | O(n²) | 稳定 | O(1) |
| 堆排序 | O(n*log2n) | O(n*log2n) | 不稳定 | O(1) |
| 希尔排序 | O(n^1.5) |
O(n^1.5) |
不稳定 |
O(1) |
| 计数排序 | O(n+k) | O(n+k) | 稳定 |
O(n+k) |
| 基数排序 | O(nk) | O(nk)(k为维度) | 稳定 |
O(n+k) |
| 归并排序 | O(n*log2n) | O(n*log2n) | 稳定 |
O(n) |
杂烩
1 Byte(字节)=8 bits,TB>GB>MB>KB>Byte
常见的面向过程高级语言: C语言、Fortran语言
常见的低级语言:汇编
高级语言与低级语言的区别:高级语言更易移植,需要编译运行,低级语言(汇编)常数极小,运行速度快
Catalan数 通项公式:h(n)=C[n,2n]/(n+1)
第一类stirling数 递推公式:S(n, k)= (n - 1) * S(n- 1, k) + S(n - 1, k - 1)
第二类stirling数 递推公式:S(n, k)=k* S(n- 1, k) + S(n - 1, k - 1)
Bell数 通项公式![]()
任意二叉树,叶子节点数是度为2点节点数数量+1
中国获图灵奖的人物:姚期智

 浙公网安备 33010602011771号
浙公网安备 33010602011771号