
关于OS Page Cache的简单介绍
在现代计算机系统中,CPU,RAM,DISK的速度不相同。CPU与RAM之间,RAM与DISK之间的速度差异常常是指数级。为了在速度和容量上折中,在CPU与RAM之间使用CPU cache以提高访存速度,在RAM与磁盘之间,操作系统使用page cache提高系统对文件的访问速度。
操作系统在处理文件时,需要考虑两个问题:
1.相对于内存的高速读写,缓慢的硬盘驱动器,特别是磁盘寻道较为耗时。
2.文件加载到物理内存一次,并在多个程序间共享。
幸运的是,操作系统使用page cache机制解决了上面的两个问题。page cache(页面缓存),内核在其中存储页面大小倍数的文件块。现假设一名为render的程序需要读取512字节scene.dat文件的内容,流程分析如下:
1.render请求获取512字节scene.dat文件的内容,使用系统调用 read(scene.dat, to_heap_buf, 512, offset=0)
2.内核从页面缓存中搜索满足请求的scene.dat文件的4KB的块,如果数据尚未缓存,则进入下一步
3.内核申请页帧空间,进行I/O操作,从偏移位置0开始请求4KB的数据,并复制到页帧中
4.内核从page cache中复制512字节的数据到render的缓存中,read()系统调用结束
对于系统的所有文件I/O请求,操作系统都是通过page cache机制实现的,对于操作系统而言,磁盘文件都是由一系列的数据块顺序组成,数据块的大小随系统的不同而不同,x86 linux系统下是4KB(一个标准的页面大小)。内核在处理文件I/O请求时,首先到page cache中查找(page cache中的每一个数据块都设置了文件以及偏移信息),如果未命中,则启动磁盘I/O,将磁盘文件中的数据块加载到page cache中的一个空闲块,之后copy到用户缓冲区中。
很明显,同一块文件数据,在内存中保存了两份,这既占用了不必要的内存空间,冗余的拷贝,也导致了CPU cache利用率不高。针对此问题,操作系统提供了内存映射机制(Linux中的mmap,windows中的Filemapping)。
在使用mmap调用时,系统并不马上为其分配内存空间,而仅仅是添加一个VMA(Virtual Memory Area)到该进程中,当程序访问到目标空间时,产生缺页中断。在缺页中断中,从page cache中查找要访问的文件块,若未命中,则启动磁盘I/O从磁盘中加载到page cache,然后将文件块在page cache中的物理页映射到进程mmap地址空间。
当程序退出或关闭文件时,系统是否会马上清除page cache中的相应页面呢?答案是否定的。由于该文件可能被其它进程访问,或该进程一段时间后会重新访问,因此,在物理内存足够的情况下,系统总是将其保存在page cache中,这样可以提高系统的整体性能。只有当系统物理内存不足时,内核才会主动清理page cache。
当进程调用write修改文件时,由于page cache的存在,修改并不会马上更新到磁盘,而只是暂时更新到page cache中,同时mark目标page为dirty,当内核主动释放page cache时,才将更新写入到磁盘(主动调用sync时,也会更新到磁盘)。
下面介绍一下Kafka中对于page cache的利用。
Kafka是一种高吞吐量的分布式发布订阅消息系统,有如下特性:
1.通过O(1)的磁盘数据结构提供消息的持久化,这种结构对于即使数以TB的消息存储也能够保持长时间的稳定性能
2.高吞吐量,即使是非常普通的硬件,Kafka也可以支持每秒数百万的消息
3.支持Kafka服务器和消费机集群来分区消息
4.支持Hadoop并行数据加载
生产者写入速度快,不同于Redis和MemcacheQ等内存消息队列,Kafka的设计是把所有的Message都要写入速度低,容量大的硬盘,以此来换取更强的存储能力。实际上,Kafka使用硬盘并没有带来过多的性能损失,而是“规规矩矩”的抄了一条近道。
首先说“规规矩矩”是因为Kafka在磁盘上只做Sequence I/O(顺序写),由于消息系统读写的特殊性,这并不存在什么问题。关于磁盘I/O的性能,Kafka官方给出的测试数据(RAID-5,7200rpm):
Sequence I/O: 600MB/s (实验室)
Sequence I/O: 400MB-500MB/s (工作场景)
Random I/O: 100KB/s
所以通过只做Sequence I/O的限制,规避了磁盘访问速度低下对性能可能造成的影响。
接下来谈谈Kafka如何“抄近道”的。
首先,Kafka重度依赖底层OS提供的page cache功能。当上层有写操作时,OS只是将数据写入到page cache,同时标记page属性为dirty。当读操作发生时,先从page cache中查找,如果发生缺页才进行磁盘调度,最终返回需要的数据。
实际上page cache是把尽可能多的空闲内存都当做磁盘缓存来使用,同时如果有其它进程申请内存,回收page cache的代价又很小,所以现代的OS都支持page cache。使用page cache功能同时可以避免在JVM内部缓存数据,JVM为我们提供了强大的GC功能,同时也引入了一些问题不适用与Kafka的设计。如果在heap內管理缓存,JVM的GC线程会频繁扫描heap空间,带来不必要的开销。如果heap过大,执行一次Full GC对系统的可用性来说将会是极大的挑战。此外所有在JVM內的对象都不免带有一个Object Overhead(对象数量足够多时,不可小觑此部分内存占用),内存的有效空间利用率会因此降低。所有In-Process Cache在OS中都有一份同样的page cache。所以通过将缓存只放在page cache,可以至少让可用缓存空间翻倍。如果Kafka重启,所有的In-Process Cache都会失效,而OS管理的page cache依然可以继续使用。
消费者获取数据快,page cache还只是第一步,Kafka为了进一步的优化性能还采用了Sendfile技术。在解释Sendfile之前,先介绍一下传统的网络I/O操作流程,大体上分为以下四步:
1.OS从硬盘把数据读到内核的page cache
2.用户进程把数据从内核拷贝到用户空间
3.然后用户进程再把数据写入到Socket,数据流入内核空间的socket buffer上
4.OS再把数据从buffer中拷贝到网卡到buffer上,这样完成一次发送
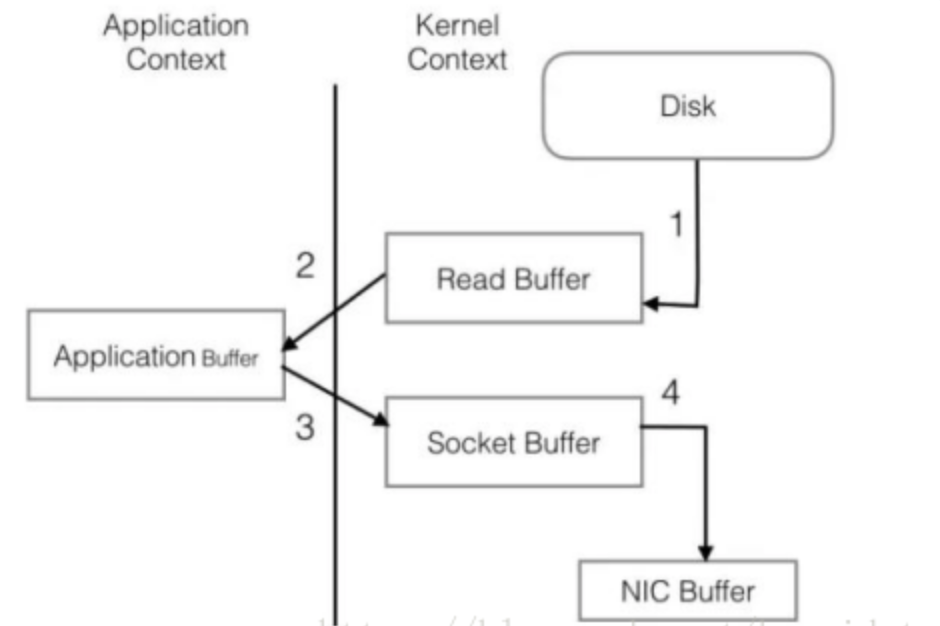
整个过程共经历两次context switch,四次system call。同一份数据在内核buffer与用户buffer之间重复拷贝,效率低下。其中2,3两步没有必要,完全可以直接在内核空间完成数据拷贝。这也是sendfile所解决的问题,经过sendfile优化后,整个I/O过程变成了下面的样子:
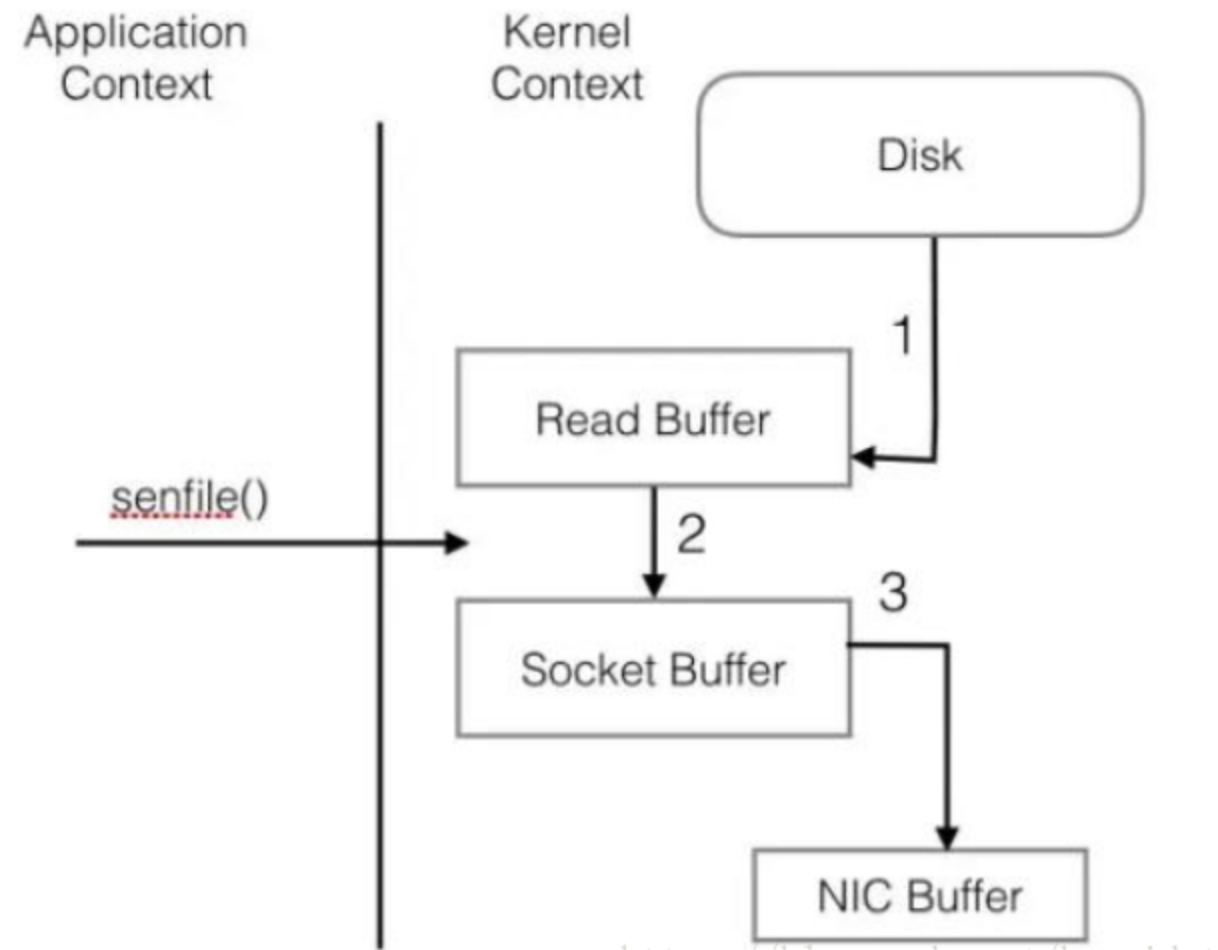
参考博文:
http://www.manongjc.com/article/24518.html
https://zhuanlan.zhihu.com/p/54762255
https://blog.csdn.net/pizi0475/article/details/49493841

 浙公网安备 33010602011771号
浙公网安备 33010602011771号