

【二】python学习总结
一i、python概念
python是一种解释型语言,速度比java慢
二、运算符和格式输出、导入
1、Python3 运算符 | 菜鸟教程 (runoob.com)
2、格式输出
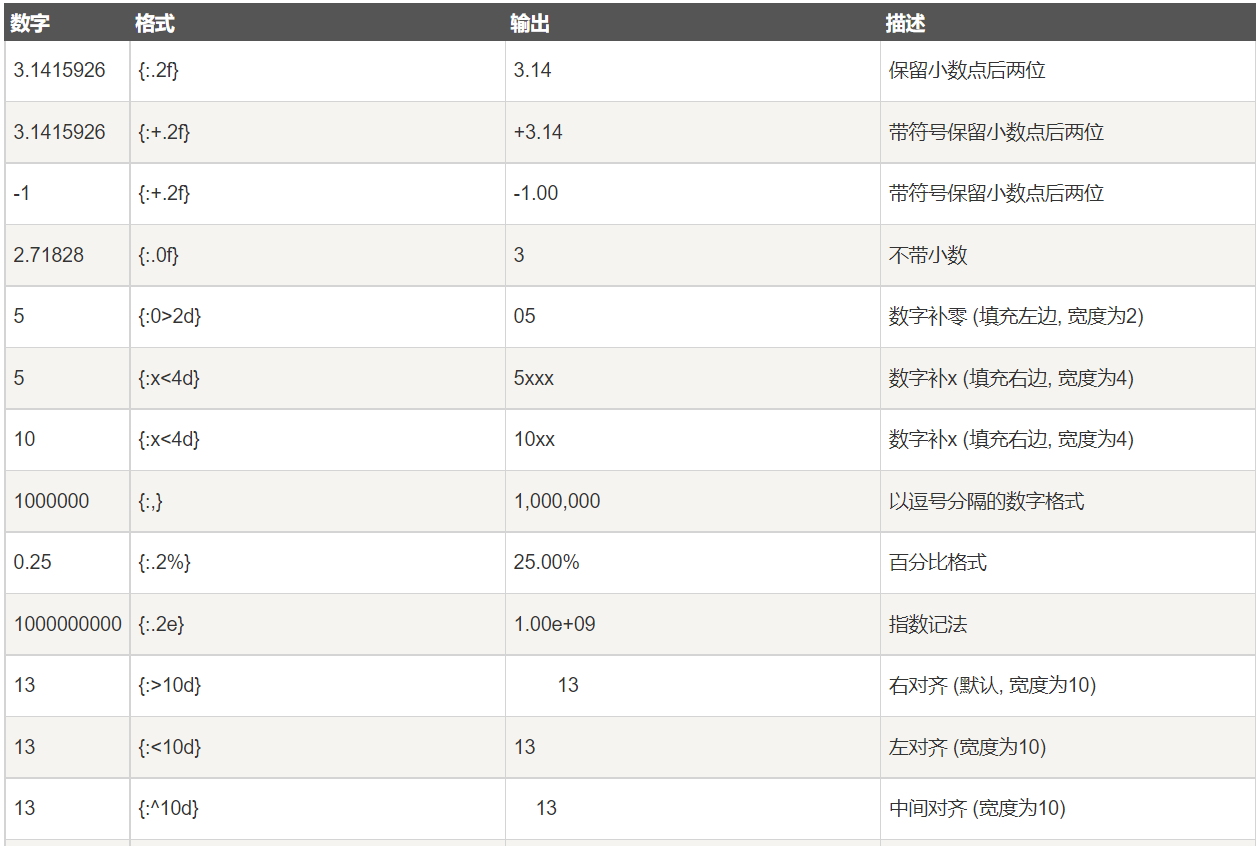
% 和.format()

name="zahngsan" li=['A','B',2.123] print('print1:%s'%name) print("print2:{}".format(li)) print(r'print3:{:a>4}'.format(li[0],li[2])) print(f'print4:{name}') print(r'print3:{:.2f}{}'.format(li[2],li[0])) print('print6:{name},{age}'.format(age=19,name='sbw')) 结果: print1:zahngsan print2:['A', 'B', 2.123] print3:aaaA print4:zahngsan print3:2.12A print6:sbw,19
3、导入的方式
三、数据类型及其结构
四种数据结构:List、Tuple、Dict、Set
六种数据类型:string、number、list、tuple、dict、set
不可变数据类型(修改值变量会变更为引用新值的id存放地址):string、number、tuple
可变数据类型(对象与子对象修改互不影响):list、dict、set
注:可变数据类型的赋值只是复制引用给新变量,子对象的id未改变,是浅拷贝
浅拷贝和深拷贝
可以用id(a)查看变量a的id地址
以下a=[1, 2],b为list类型
浅拷贝:如copy,b=a,只会给新list对象分配id地址,但里面的子对象还是引用a的子变量id
例:b=a.copy(),id(a)与id(b)不同,但id(a[0][0])与id(b[0][0])的值一致,因为引用的是同一个地址
深拷贝:deepcopy,赋予新的list对象id,并复制list里子对象的值,有一定的缺陷,引用自身会导致无限循环
例:b=a.deepcopy(),id(a)与id(b)不同,但id(a[0][0])与id(b[0][0])不同,因为引用不是同一个地址
不可变数据类型:赋值的本质就是复制id引用
注:number和string没有copy函数
a=3 b=a print(id(a),' '*4,id(b)," "*4,b is a) a=a+1 print(a," "*4,b) print(id(a),' '*4,id(b)," "*4,b is a) 结果: 2010418538864 2010418538864 True 4 3 2010418538896 2010418538864 False
结论:a改变前,a,b引用同一个id,是相同变量
a改变后,a的引用会更新,而b依旧引用原来的id
可变数据类型:
#对一维列表而言,copy和deepcopy没有区别 a=[1,2,3] b=a c=a.copy() d=deepcopy(a) print(a," ",b,' ',c,' ',d) print(id(a),' ',id(b),' ',id(c),' ',id(d)) print(id(a[1]),' ',id(b[1]),' ',id(c[1]),' ',id(d[1])) print('--'*10) a[1]=4 print(a," ",b,' ',c,' ',d) print(id(a),' ',id(b),' ',id(c),' ',id(d)) print(id(a[1]),' ',id(b[1]),' ',id(c[1]),' ',id(d[1])) 结果: [1, 2, 3] [1, 2, 3] [1, 2, 3] [1, 2, 3] 2192060687424 2192060687424 2192060676608 2192062287552 2192054970704 2192054970704 2192054970704 2192054970704 -------------------- [1, 4, 3] [1, 4, 3] [1, 2, 3] [1, 2, 3] 2192060687424 2192060687424 2192060676608 2192062287552 2192054970768 2192054970768 2192054970704 2192054970704
结论:a改变前,
单纯的赋值是直接复制引用,a,b对象id一致,子对象id一致,
而copy的c对象被分配新的id,子对象继续引用a的子对象的id
而deepcopy的d对象被分配新的id,子对象继续引用a的子对象的id
a改变后:
a,b子对象id一致,
c对象的子对象继续引用原来a的子对象的id
d对象的子对象继续引用原来a的子对象的id
#比较copy和deepcopy的区别 #copy只能复制一维列表值,而deepcopy可以复制多维列表值 假定 from copy import copy,deepcopy a=[1,2,[3,4]] b=a.copy() c=deepcopy(a) print(a," ",b,' ',c) print(id(a),' ',id(b),' ',id(c)) print(id(a[2][0]),' ',id(b[2][0]),' ',id(c[2][0])) print("-"*30) a[2][0]=5 print(a," ",b,' ',c) print(id(a),' ',id(b),' ',id(c)) print(id(a[2][0]),' ',id(b[2][0]),' ',id(c[2][0])) 结果: [1, 2, [3, 4]] [1, 2, [3, 4]] [1, 2, [3, 4]] 2745325025536 2745325025664 2745325588096 2745319450992 2745319450992 2745319450992 ------------------------------ [1, 2, [5, 4]] [1, 2, [5, 4]] [1, 2, [3, 4]] 2745325025536 2745325025664 2745325588096 2745319451056 2745319451056 2745319450992
结论:a改变前,
而copy的b对象被分配新的id,子对象继续引用a的子对象的id
而deepcopy的c对象被分配新的id,子对象继续引用a的子对象的id
a改变后:
b对象的二维子对象继续引用a改变后的子对象的id
c对象的二维子对象继续引用原来a的子对象的id
结论:
假定a=[1,2,[3,4]]
- 通过b=a赋值的方式,b会随着a任何改变而变
- 通过copy方式得到的b,b的一维列表id值不会随a一维列表的改变而变,但二维列表会随a变化而变
- 通过deepcopy方式得到的b,b不随a任意变化而变
问题:append和extend是否为浅拷贝?
答:append添加感觉相当于赋值,直接复制了引用,会随原值变而变
extend添加感觉相当于copy,添加的序列对象的子对象被重新分配了id,第二层数据才会随原值变而变
但都是浅拷贝
1、Number
number包括:int、float、complex(复数)、boolean(1/0)
number的常用函数
cell() #上入函数cell(2.1)==3 floor() #下舍函数floor(2.9)==2 max() min() round(x,[n]) #保留n位小数 abs() #绝对值
mod(x) #返回(小数部分,整数部分)
一些随机函数
choice(seq) 从序列的元素中随机挑选一个元素,比如random.choice(range(10)),从0到9中随机挑选一个整数。 randrange ([start,] stop [,step]) 从指定范围内,按指定基数递增的集合中获取一个随机数,基数默认值为 1 random() 随机生成下一个实数,它在[0,1)范围内。 seed([x]) 改变随机数生成器的种子seed。如果你不了解其原理,你不必特别去设定seed,Python会帮你选择seed。 shuffle(lst) 将序列的所有元素随机排序 uniform(x, y) 随机生成下一个实数,它在[x,y]范围内。
2、String
常用函数
str.upper() str.lower() str.capitalize() 首字母大写 str.count('ab',1,10) ‘ab’在str字符串中出现的次数,后边则是范围 str.encode(encoding='UTF-8',errors='strict') #以 encoding 指定的编码格式编码字符串,如果出错默认报一个ValueError 的异常,除非 errors 指定的是'ignore'或者'replace' str.find('ab', beg=0, end=len(string)) 检测 str 是否包含在字符串中,如果指定范围 beg 和 end ,则检查是否包含在指定范围内,如果包含返回开始的索引值,否则返回-1 str.index('ab', beg=0, end=len(string)) 跟find()方法一样,只不过如果str不在字符串中会报一个异常。 str.isalnum() #字符串至少有一个字符且 字符都是字母或数字返回true str.isalpha() #字符串至少有一个字符并且所有字符都是字母或中文字则返回 True str.isnumeric() 字符串中只包含数字字符,则返回 True str.strip() lstrip() rstrip() 截掉字符串左边的空格或指定字符,默认截掉空格 str.replace(old, new [, max]) max(str) min(str) 返回字符串 str 中最大/小的字母 str.split(' ',[num]) 默认以空格分离字符串,次数为num str.join() 以指定字符串str作为分隔符,将 seq 中所有的元素(的字符串表示)合并为一个新的字符串
3、元组Tuple
常用函数:len、max、min
4、列表List
常用函数
list():以list(dict.items())将字典转为长度为2的元组列表
append(obj) extend(seq) count(obj) index(obj) sort() reverse() insert(index,obj) pop([index=-1]) remove(obj) clear() copy()
5、字典Dict
list 不使用 hash 值进行索引,故其对所存储元素没有可哈希的要求;set / dict 使用 hash 值进行索引,也即其要求欲存储的元素有可哈希的要求。Python不支持dict的key为list或dict类型,因为list和dict类型是unhashable(不可哈希)的
常用函数
clear() copy() fromkeys(seq[,value]) get(key,default=none) items() keys() values() setdefault(key,default=none) update(dict2) pop(key[,default]) popitem()
6、集合Set
set1=set(seq) 创建集合
add() 为集合添加元素
clear() 移除集合中的所有元素
copy() 拷贝一个集合
difference() 返回多个集合的差集a-b
difference_update() 移除集合中的元素,该元素在指定的集合也存在。
discard() 删除集合中指定的元素
intersection() 返回集合的交集a&b
intersection_update() 返回None,移除a中不同b中元素,集合a中只剩下a&b的元素
isdisjoint() 判断两个集合是否包含相同的元素,如果没有返回 True,否则返回 False。
issubset() 判断指定集合是否为该方法参数集合的子集。
issuperset() 判断该方法的参数集合是否为指定集合的子集
pop() 随机移除元素
remove() 移除指定元素
symmetric_difference() 返回两个集合中不重复的元素集合a^b。
symmetric_difference_update() 移除当前集合中在另外一个指定集合相同的元素,并将另外一个指定集合中不同的元素插入到当前集合中。
union() 返回两个集合的并集a|b
update() 给集合添加元素
7、切片
序列seq指:string、list、tuple这些可通过下标index取值的数据类型
切片是序列seq高级索引取值的方式
seq[start:stop:step] :start开始位置、stop结束位置、step步长,三者可为负数
四、流程控制语句
for name in names: 语句1 if a in (1,2); yuuju1 elif a in list: yuju2 else: yuju3 while true: yuju1 yeild try: yuju1 exception as e yuju2 else: yuju3 finally: yuju4
#python3.10新增 match a: case 1: yuju1 case _: yuju2
五、函数
1、函数的必须参数、默认参数,关键字参数、不定长参数
def study(name,number=None,*args,**kwargs,city) type(args) #type为list type(kwargs) #type为dict print(*args, **kwargs) #打印:’1‘ ’2‘ ’a‘=1 ’b‘=2 list1=['1','2'] dic1={'a':1, 'b': 2} study('zhangsan',12,*list1,**dict1,city='shenzhen') #study中name、city为必须参数
#study中的number为默认参数 #study中city为关键字参数,实例化必须是study(...,city='cs') #study中*args、*kwargs为不定长参数,分别以列表、字典的方式传值
2、递归函数
#分解因子 def jisuan(n,m=1): while m<=n: if n%m==0: print(m) return jisuan(n,m+1) jisuan(14)
六、迭代器和生成器
可以使用isinstance()判断一个对象是否是Iterable对象
from collections import Iterable,Iterator print(isinstance('1234',Iterable))
- 迭代对象Iterable:
1、string,list,tuple,dict,set
2、生成器,包括生成器,和yield的函数
- 迭代器Iterator:
1、能够使用next()调用返回下一个值,如(for i in range(10))整体是一个迭代器
2、’abc‘不是不是迭代器,但iter('abc')是迭代器,可以通过iter()函数把迭代对象变成迭代器
3、Iterator表示的是数据流,可以使用next()调用不断返回下一个值,直到没有数据时抛出StopIteration错误
4、迭代器是惰性的,只有在需要调用next()返回数据时才计算,就是按需计算
5、可以吧迭代器看作是有序的序列,但不能提前知道它的具体长度
- 生成器Generator:
1、生成器使用的场景:列表数据太多,占据太大的存储空间,可以使用生成器边用边计算
2、生成器也是迭代器的一种,但只迭代一次便计算完毕,
3、生成器是在调用的时候在内存中生成,而不是在事先存储在内存中
#列表生成器 a=[1,2,3] b=[i+1 for i in a] print(type(b),"\n",b) #字典生成器 c={1:'a',2:'b'} d={key:value*2 for key,value in c.items()} print(type(d),"\n",d) 结果: <class 'list'> [2, 3, 4] <class 'dict'> {1: 'aa', 2: 'bb'}
带yield的函数作为生成器
#yield的函数作为生成器 def feibo(max): a, b, total = 0, 1, 0 while total < max: yield b a, b, total = b, a + b, total + 1 if __name__ == '__main__': f = feibo(8) while True: try: print(next(f), end=" ") except StopIteration: break
类和函数作为迭代器
七、简单的输入输出、os、和文件处理
1、读键盘输入
python的键盘输入数据类型都为字符串
简单的输入
str=input("please input:")
2、读命令行输入
python对命令行的三种解析方式
1)sys.argv
sys.argv是一个列表,以空格分隔命令行输入
sys.argv[0]代表py文件路径,sys.argv[1:]才是所有参数
#py文件 import sys print(f"{type(sys.argv)}",sys.argv) print("py文件路径:",sys.argv[0]) print("第一个参数:",sys.argv[1]) print("第一个参数:",sys.argv[2]) #命令行输入 D:\code\request+pytest\testcase\taobao>python python_study.py abc 123 <class 'list'> ['python_study.py', 'abc', '123'] py文件路径: python_study.py 第一个参数: abc 第一个参数: 123
2)argparse
暂定
3)getopt
暂定
2、os模块常用方法
os.getcwd() #获取当前工作目录,即当前python脚本工作的目录路径 os.chdir("dirname") #改变当前脚本工作目录;相当于shell下cd os.curdir #返回当前目录: ('.') os.pardir #获取当前目录的父目录字符串名:('..') os.makedirs('dirname1/dirname2') #可生成多层递归目录 os.removedirs('dirname1') #若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推 os.mkdir('dirname') #生成单级目录;相当于shell中mkdir dirname os.rmdir('dirname') #删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname os.listdir('dirname') #列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印 os.remove() #删除一个文件 os.rename("oldname","newname") #重命名文件/目录 os.stat('path/filename') #获取文件/目录信息 os.sep #输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/" os.linesep #输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n" os.pathsep #输出用于分割文件路径的字符串 os.name #输出字符串指示当前使用平台。win->'nt'; Linux->'posix' os.system("bash command") #运行shell命令,直接显示 os.environ #获取系统环境变量 os.path.abspath(path) #返回path规范化的绝对路径 os.path.split(path) #将path分割成目录和文件名二元组返回 os.path.dirname(path) #返回path的目录。其实就是os.path.split(path)的第一个元素 os.path.basename(path) #返回path最后的文件名。如何path以/或\结尾,那么就会返回空值。即os.path.split(path)的第二个元素 os.path.exists(path) #如果path存在,返回True;如果path不存在,返回False os.path.isabs(path) #如果path是绝对路径,返回True os.path.isfile(path) #如果path是一个存在的文件,返回True。否则返回False os.path.isdir(path) #如果path是一个存在的目录,则返回True。否则返回False os.path.join(path1[, path2[, ...]]) #将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 os.path.getatime(path) #返回path所指向的文件或者目录的最后存取时间 os.path.getmtime(path) #返回path所指向的文件或者目录的最后修改时间
3、文件读取
#文件读取方式r,rb,r+,w,wb,w+,a,ab,a+,rb+,wb+,ab+ open(filename, mode) f.read() f.readline() f.readlines() f.tell() f.write() #rom_what 的值, 是 0 表示从开头往后移, 是 1 表示当前位置往后移, 2 表示文件的结尾往前移, f.seek(offset, from_what) f.close()
八、类与对象、内置函数
类与对象的概念:
- 类(Class): 用来描述具有相同的属性和方法的对象的集合。它定义了该集合中每个对象所共有的属性和方法。对象是类的实例。
- 方法:类中定义的函数。
- 类变量:类变量在整个实例化的对象中是公用的。类变量定义在类中且在函数体之外。类变量通常不作为实例变量使用。
- 数据成员:类变量或者实例变量用于处理类及其实例对象的相关的数据。
- 方法重写:如果从父类继承的方法不能满足子类的需求,可以对其进行改写,这个过程叫方法的覆盖(override),也称为方法的重写。
- 局部变量:定义在方法中的变量,只作用于当前实例的类。
- 实例变量:在类的声明中,属性是用变量来表示的,这种变量就称为实例变量,实例变量就是一个用 self 修饰的变量。
- 继承:即一个派生类(derived class)继承基类(base class)的字段和方法。继承也允许把一个派生类的对象作为一个基类对象对待。例如,有这样一个设计:一个Dog类型的对象派生自Animal类,这是模拟"是一个(is-a)"关系(例图,Dog是一个Animal)。
- 实例化:创建一个类的实例,类的具体对象。
- 对象:通过类定义的数据结构实例。对象包括两个数据成员(类变量和实例变量)和方法。
1、类的多态、继承、重载
继承:
class test01: def ppp(self): print("test01") class test00(test01): def __init__(self): pass def ppp(self): super().ppp() print("test02") test00().ppp() 结果: test01 test02
多态:
class test01: @classmethod def ppp(cls): print(cls.__name__) class test02: @classmethod def ppp(cls): print(cls.__name__) class test00: def __init__(self,obj): print(obj.__name__) test00(test01) test00(test02) 结果: test01 test02
重载:
重载:指一个类中,方法名字相同,而参数不同。python中用*args和**kwargs可以接受任意参数,因此没有重载
重写:子类重写父类的方法,做出修改,也叫做方法覆盖
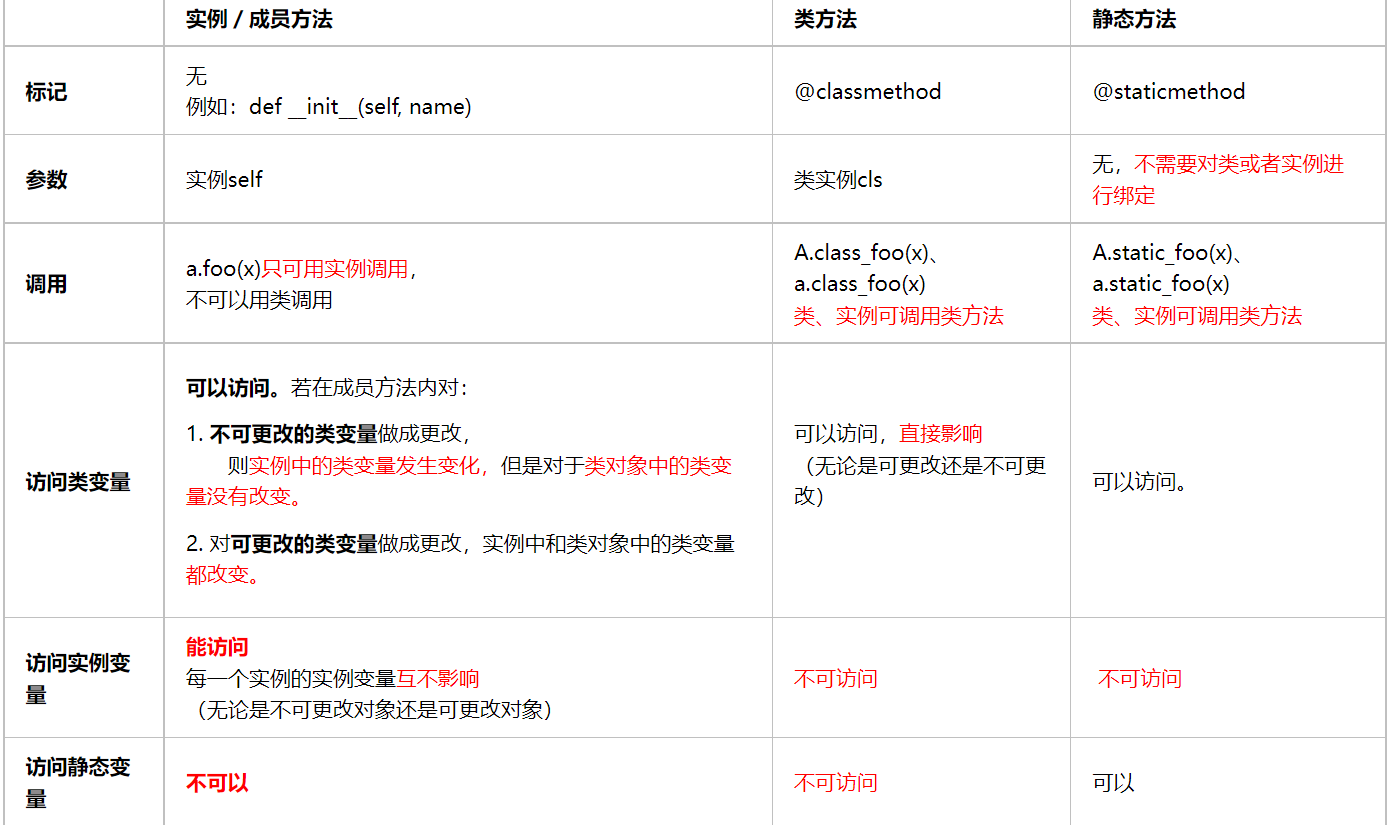
2、先总结类方法、实例方法、静态方法、类变量、实例变量
3、类的内置函数总结
1) 内置方法和属性 :暂定,还有很多内置方法没弄明白
class Test00: """__doc__获取本文档""" def __init__(self,seq): print("实例化时构造方法初始对象") self.lei = 'mystudy' # 对象调用dict打印出来 self.seq=seq def __call__(self): print("由对象加()时触发执行") def __str__(self): print("打印对象时执行") def __del__(self): print("销毁对象时执行") def __iter__(self): print("可迭代对象拥有此方法,迭代中") return iter(self.seq) tt=Test00([1,2,3]) tt() #呼叫__call__方法 print(tt.__doc__) #可类名或者实例对象调用 print("迭代中:",next(iter(tt))) print("获取name:",Test00.__name__) #只类名调用 print("获取类所在的模块名字:",tt.__module__) #可类名或者实例对象调用,本模块调用显示__main__,# 导入其他模块调用才会是模块真名字 print("获取对象的类是什么:",tt.__class__) #可类名或者实例对象调用 print("类名调用dict打印类所有属性和方法:",Test00.__dict__) print("对象调用dict打印对象所有元素:",tt.__dict__) 结果: 实例化时构造方法初始对象 由对象加()时触发执行 __doc__获取本文档 可迭代对象拥有此方法,迭代中 迭代中: 1 获取name: Test00 获取类所在的模块名字: __main__ 获取对象的类是什么: <class '__main__.Test00'> 类名调用dict打印类所有属性和方法: {'__module__': '__main__', '__doc__': '__doc__获取本文档', '__init__': <function T..........'__weakref__' of 'Test00' objects>} 对象调用dict打印对象所有元素: {'lei': 'mystudy', 'seq': [1, 2, 3]}
2)__getitem__、__setitem__、 delitem__这是对索引的操作
class Test00: def __getitem__(self, item): print("get") def __setitem__(self, key, value): print("set") def __delitem__(self, key): print("del") tt=Test00() tt['name']=123 tt['name'] del tt['name'] 结果 set get del
3)对象访问属性的内置方法
class Test00: def __init__(self,name): self.name=name def __getattribute__(self, item): print("校验属性:",item,"=",end=' ') return object.__getattribute__(self,item) t3=Test00("zhangsan") print(t3.name) 结果 校验属性: name = zhangsan
4、反射
python中的反射功能是由以下四个内置函数提供:hasattr、getattr、setattr、delattr,改四个函数分别用于对对象内部执行:检查是否含有某成员、获取成员、设置成员、删除成员。
反射的本质及其特点:
- 在命名空间中查找和字符串同名的变量(类、函数、方法或者属性),然后获取引用进行访问
- 本质上是字符串事件驱动
举例:和a=2,使用字符串a去命名空间查找到变量名a,获取a的引用,从而去访问值2
发射用法:
文件一
#betest.py文件 #反射用法 def ccc(self): print("ccc方法") class BeTest: def aaa(self): print("aaa方法") def bbb(self): print("bbb方法")
文件二
#hasattr(),setattr,getattr,delattr #反射用法 obj=__import__("Practices.betest",fromlist=True) print(hasattr(obj,"ccc")," "*5,hasattr(obj,"BeTest")) #查看模块是否存在函数及类 if hasattr(obj,"BeTest"): bt=obj.BeTest() getattr(bt,"aaa")() #执行对象bt的aaa()方法 if not hasattr(bt,"ccc"): setattr(bt,"ddd",obj.ccc) #设置新方法按照betest模块的ccc方法逻辑执行,也可设置和添加属性 print("ddd方法是否存在:",hasattr(bt,"ddd")) getattr(bt,"ddd")(bt) #因为设置的ccc之前函数,所以最后括号需要加一个self:对象本身bt delattr(bt,"ddd") #删除方法,也可删除属性 print("ddd方法是否存在:",hasattr(bt,"ddd")) 结果: True True aaa方法 ddd方法是否存在: True ccc方法 ddd方法是否存在: False
反射实际应用场景:
class User: __op_dict={"1":"login",'2':"register",'3':"logout"} def login(self): print("登录") def register(self): print("注册") def logout(self): print("退出") def opt(self): #通过一个入口去访问其他方法 getattr(self,self.__op_dict[input("输入操作码:")])() User().opt()
其他应用字符串驱动的函数,eval,exec
5、单例
所谓单例,是指一个类的实例从始至终只能被创建一次。再创建只能获取第一次创建的对象的id引用
创建方式:
1)__new__方式,绑定类变量
# 方法一:用__new__实现,将类实例绑定到类变量_instance上面 # 如果cls._instance为None说明该类还没有实例化过,实例化该类,并返回 # 如果cls._instance不为None,直接返回cls._instance
class Test00:
def __new__(cls, *args, **kwargs):
if not hasattr(Test00,'_instance'):
cls._instance=super().__new__(cls, *args, **kwargs)
return cls._instance
t1=Test00()
t2=Test00()
print(id(t1),id(t2))
2)绑定类变量字典实现,让所有的对象的方法和属性集合都指向同一个字典,没有实现单例
class Test00: _instance={} def __new__(cls, *args, **kwargs): obj=super().__new__(cls, *args, **kwargs) obj.__dict__=cls._instance return obj t1=Test00() t2=Test00() print(id(t1),id(t2))
3)装饰器实现
def singleton(cls, *args, **kwargs): instances = {} def _singleton(): if cls not in instances: instances[cls] = cls(*args, **kwargs) return instances[cls] return _singleton @singleton class MyClass4(object): a = 1 def __init__(self, x=0): self.x = x
4)基于元类实现
#暂时不懂元类实现原理 class Singleton(type): def __init__(self,name,bases,class_dict): super(Singleton,self).__init__(name,bases,class_dict) self._instance=None def __call__(self,*args,**kwargs): if self._instance is None: self._instance=super(Singleton,self).__call__(*args,**kwargs) return self._instance
5)模块导入实现
#python_calss.py文件 class Test00: def ppp(self): pass tt=Test00() #test.py文件 from python_calss import tt print(id(tt))
6)用类名创建实例对象
class Test00: def ppp(self): print("打印") Test00=Test00() Test00.ppp() #再用tt=Test00()创建会报错,因此Test00类只有一个实例对象
九、时间访问和异常处理
1、time模块
三种时间格式: time.time():时间戳,总秒数, time.localtime():时间元组 time.asctime():英文时间字符串 time.mktime(time.localtime()):将时间元组转化为时间戳 time.localtime(time.time()):将时间戳转化为时间元组 time.strftime('%H:%M:%S',time.localtime()):将时间元组转化为字符串 time.strptime('23:11:14','%H:%M:%S'):将字符串转化为时间元组 可以单独以time.localtime().tm_year获取时间元组中某个值
2、datetime模块:封装了time模块
dt=datetime.datetime.today() #获得当前时间datetime dt=datetime.datetime.now() #获得当前时间datetime datetime.datetime.now().timestamp() #将datetime转化为字符串 datetime.datetime.fromtimestamp(time.time()) #把时间戳转换成datetime dt.strftime("%Y-%m-%d") #按datetime转换成字符串 datetime.datetime.strptime('18:19:59.98', '%H:%M:%S.%f') #把字符串转换成datetime dt.year #年 dt.month #月 dt.day #日 dt.date() #日期 dt.time() #时间 dt.weekday() #星期 dt.isoweekday() #星期
from datetime import datetime, timedelta
dt = datetime.today() - timedelta(days=1) # 获取前一天的日期
dt_str = dt.strftime('%Y-%m-%d') # 将datetime对象转为日期字符串
3、calendar模块
获取年历calendar.calendar(2019) 获取某年某月的日历calendar.month(2019,12) 是否闰年calendar.isleap(2019) 返回给定日期的日期码calendar.weekday(2019,12,15)
4、异常处理
#异常处理结构 def jisuan(): try: 1/0 except ZeroDivisionError as e: print("有异常就执行") else: print("没有异常就执行") finally: print("不论有没有异常都执行") 结果: 有异常就执行 不论有没有异常都执行
九、python的一些工作机制
1、命名空间、作用域
命名空间(NameSpace)是名称到对象的映射,大部分命名空间是通过字典来实现的,本质上是一个字典,key就是变量名,value就是变量值
- 内置名称(built-in names), Python 语言内置的名称,比如函数名 abs、char 和异常名称 BaseException、Exception 等等。
- 全局名称(global names),模块中定义的名称,记录了模块的变量,包括函数、类、其它导入的模块、模块级的变量和常量,gloables()查看。
- 局部名称(local names),函数中定义的名称,记录了函数的变量,包括函数的参数和局部定义的变量。(类中定义的也是),locals()查看
访问变量名时,查找顺序:局部》全局》内置
生命周期:
内置命名空间:从解释器启动后便创建,一直保留,不删除
全局命名空间:模块定义时被创建,保留到解释器退出
局部命名空间:函数调用时创建,返回结果或抛出异常后删除
2、python内存池的管理机制
从三个方面来说:1. 引用计数;2. 垃圾回收; 3.内存池机制;
1. 引用计数
Python是动态语言,即在使用前不需要声明,对内存地址的分配是在程序运行时自动判断变量类型并赋值。
对每一个对象,都维护着一个指向改对象的引用的计数,obj_refcnt
当变量引用一个对象,则obj_refcnt+1,如果引用它的变量被删除,则obj_refcnt-1,系统会自动维护这个计数器,当其变成0时,被回收。
2. 内存池机制
Python内存机制分为6层,内存池用于管理对小块内存的申请和释放。

- -1,-2层:主要由操作系统进行操作
- 0层:是C中的malloc,free等内存分配和释放函数进行操作
- 1,2层:内存池,由Python的接口函数PyMem_Malloc函数实现,当对象<256字节的时候,由该层直接分配内存。虽然,对应的也会使用malloc直接分配256字节的内存快——解决C中malloc分配的内存碎片问题。
- 3层:最上层,我们对Python对象的操作
内存池与C不同的是,:
- 如果请求分配的内存在1~256字节之间就使用自己的内存管理系统,否则直接使用 malloc。
- 这里还是会调用 malloc 分配内存,但每次会分配一块大小为256k的大块内存。
- 经由内存池登记的内存,最后被回收到内存池,而不会调用C的free释放掉,以便下次使用。
- 对于Python对象,如数值、字符串、元组,都有其独立的私有内存池,对象间不共享他们的内存池。例如:如果分配又释放了一个大的整数,那么这块内存不能再被分配给浮点数。
3. Python的垃圾回收机制。
PythonGC主要是通过引用计数来跟踪和回收垃圾,并使用“标记-清理”技术来解决容器对象可能产生的循环引用问题,使用“分代回收”提高回收的效率。
1. 引用计数:在Python中存储每个对象的引用计数obj_refcnt。当这个对象有新的引用,则计数+1,当引用它的对象被删除,则计数-1,当技术为0时,则删除该对象。
- 优点:简单、实时性
- 缺点:效率低,维护引用计数消耗资源、无法解决循环引用的问题。
2. 标记-清理:基本思路是按需分配。等到没有空闲时,从寄存器和程序栈中的引用出发,遍历以对象为节点,引用为边所构成的图,把所有可以访问到对象都打上标记,然后清扫一遍内存空间,把没有标记的对象释放。
3. 分代收集:
总体的思想:Python将系统中所有的内存块根据对象存活时间划分为不同的代(默认是三代),垃圾收集频率随着“代”的存活时间的增大而减小。
举例:
我们分为新生代、老年代、永久代。
在对对象进行分配时,首先分配到新生代。大部分的GC也是在新生代发生。
如果新生代的某内存M进过了N次GC以后还存在,则进入老年代,老年代的GC频率远低于新生代。
对于永久代,GC频率特别低。
3、
十、装饰器
装饰器带闭包的特点,理解闭包能够更好地理解装饰器
装饰器的特点:
- 接受函数为参数,并返回一个内部函数
- 以标记的形式对动态运行的函数进行修饰,但不改变被修饰的函数功能
def decorator(func): def warpper(*args, **kwargs): print("装饰器前置内容") func(*args,**kwargs) #*args和**kwargs最好带上,否则被标记函数有参数时会报错 print("装饰器后置内容") return warpper @decorator def test(): print("被装饰的函数功能") test()
print(test.__name__) #虽然没有改变函数功能,函数输出的函数__name__变为warpper,
可能会造成某些依赖函数名字的功能出错
输出:
装饰器前置内容
被装饰的函数功能
装饰器后置内容
warpper
衍生问题:避免函数name的输出不受装饰器影响
import functools #导入 def decorator(func): @functools.wraps(func) #标记 def warpper(*args, **kwargs): print("装饰器前置内容") func() print("装饰器后置内容") return warpper @decorator def test(): print("被装饰的函数功能") test() print(test.__name__) #输出变为test
装饰器使用三层结构可以使得装饰器输入参数
import functools # 装饰器带有参数:Bug级别:level def print_debug_level(level): def print_debug(func): @functools.wraps(func) def wrapper(*args, **kwargs): print('Start login with level:' + str(level)) func(*args, **kwargs) print('End %s()' % func.__name__) return wrapper return print_debug @print_debug_level(level=5) def login(user): # 函数带有参数 print('Login in '+ user) login('sbw')
类装饰器:
class Demo: def __init__(self,func): self.func=func def __call__(self, *args, **kwargs): self.func() print("print") @Demo def login(): print('Login in ') login()
类中有函数装饰器一:
class Demo: def __init__(self): pass @staticmethod def count(func): def warpper(*args,**kwargs): print("print") func(*args,**kwargs) return warpper @Demo.count def login(user): print(f'Login in {user}') login('user')
类中有函数装饰器二:
class Demo: total=0 #统计装饰器被调用额次数,可以修改类变量和实例变量 def __init__(self): pass @classmethod def count(cls,func): def warpper(*args,**kwargs): cls.total+=1 print("print") func(*args,**kwargs) return warpper @Demo.count def login(user): print(f'Login in {user}') login('user') print(Demo.total)
应用:验证功能
import time import functools dict_cache={} # 存放所有验证过的用户和验证的结果 def cache(func): @functools.wraps(func) def wrapper(user): now = time.time() res=None if user in dict_cache: # 判断这个用户是否曾经验证过 # print('曾经验证过') time.sleep(1) cache_time = dict_cache[user] if now - cache_time > 10: # 如果上一次验证的时间在30s之前,则重新进行验证 print(u'Success:成功登录') res = func(user) dict_cache[user] = (res, now) else: # 还在缓存时间内 print(f'Fail:请{10-round(now-cache_time,2)}s后登录') else: print('Success:首次验证') res = func(user) dict_cache[user] = (res, now) return res return wrapper def login(user): print('in login:'+user,end=' ') time.sleep(0.5) validation(user) @cache def validation(user): time.sleep(1) login('sbw') login('lf') login('lf') login('sbw') login('sbw')
使用类装饰器和__get__()函数把方法变成属性,达到和@property一样效果
其他@property:把方法变成属性
十一、闭包
闭包的使用目的:使一些变量能够持久保存,不会因为外部函数结束而被释放掉。
创建一个闭包的三个条件:
- 必须有内嵌函数
- 内嵌函数必须要引用外部函数中的变量
- 外部函数返回值必须是内嵌函数
闭包的特点和作用:
- 内部函数不会因为外部函数的结束而被释放掉,而是直到保存在内存中,直到内部函数结束被调用
- 和单例中_instance类似,使得函数部分私有变量保持持久性
十二、多线程
线程、进程、协程
https://zhuanlan.zhihu.com/p/477826233
threading.Thread
threading.Lock
threading.RLock
threading.Event
threading.Condition
例子1:餐厅中,把多个厨师生产食物过程看作多线程,把不同顾客需要不同数量的食物视作多线程,厨师只生产一定量{10}的食物作为储备,多了就不生产,少了就生产
import timeimport threading,queue import random lock=threading.Lock() event=threading.Event()
fools=queue.Queue(10)
def producer(i):
global fools
while True:
if fools.full():
print("食物很多,厨师们开始休息了")
else:
time.sleep(1)
fools.put(i)
print(f"厨师{i}生产出一个,目前{fools.qsize()}")
def consumer(i,n):
global fools
if fools.qsize()<n:
print(f"食物({fools.qsize()})快没了,顾客{i}在催要{n}个")
else:
time.sleep(1)
for m in range(n):
fools.get(i)
fools.task_done()
print(f"顾客{i}吃了{n}个,目前{fools.qsize()}")
for i in range(3):#铁打的厨师,三个厨师线程一直在工作
t = threading.Thread(target=producer, args=(i,),name="厨师%s"%i,daemon=True)
t.start()
p=0 #顾客次数
while True:#流水的顾客,顾客一次性线程,没有足够的食物直接跑了
time.sleep(random.randint(0,1))
p+=1
t = threading.Thread(target=consumer, args=(p,random.randint(1,3)))#每个顾客次数可能需要的食物数量不同random
t.start()
十三、正则表达式
匹配方式:
- group() 返回被 RE 匹配的字符串。
- start() 返回匹配开始的位置
- end() 返回匹配结束的位置
- span() 返回一个元组包含匹配 (开始,结束) 的位置
#参数pattern:为匹配样式 #参数string:被匹配的字符串 #参数flag:re标志re.I大小写不区分,re.M多行查找,re.S匹配换行在内的所有字符 #参数repl:替换的字符串,也可以是函数,默认入参匹配的字符串 #参数count:匹配次数 re.match(pattern, string, flags=0) #从字符串开始匹配,查找第一个匹配的字符串 re.search(pattern, string, flags=0) #从字符串全部内容匹配,查找第一个匹配的字符串 re.sub(pattern, repl, string, count=0, flags=0) #替换匹配内容 re.compile(pattern[, flags]) #输出匹配格式 re.findall(pattern, string, flags=0) #输出list字符串内所有匹配的字段 re.finditer(pattern, string, flags=0) #输出迭代器,所有匹配的字段 group(num=0) #输出单个匹配的字段 groups() #元组形式,但不是元组,输出所有匹配的字段 str='12ddf323AdVBcccc1789' print(re.findall('\d+',str)) print(re.match('(\d+)',str).groups()) print(re.search('(\d{3,}).*([A-Z]{2})',str).group(2)) pattern=re.compile('(?i:[a-z]){3}') print(pattern.findall(str)) for i in pattern.finditer(str): print(i.group())
def ppp(matchobj):
return matchobj.group('val').upper()
print(re.sub('(?P<val>[a-z])', ppp, str))
结果: ['12', '323', '1789'] ('12',) VB ['ddf', 'AdV', 'Bcc'] ddf AdV Bcc
12DDF323ADVBCCCC1789
re.split(pattern, string[, maxsplit=0, flags=0])
pattern.findall(string[, pos[, endpos]])
re.sub例子:
def handle(match): return str(int(match.group())**2) str1="a@b5@4" print(re.sub("(\d+)",handle,str1)) --------- a@b25@16
具体匹配规则:Python3 正则表达式 | 菜鸟教程 (runoob.com)
正则匹配在线练习:https://regex101.com/
十一、python的内置函数
1、enumerate(seq[,start=0])函数
将一个序列seq分化成 元组(索引,索引代表的元素值)的模式返回
a=[1,2,[3,4]] for n in enumerate(a): print(n,type(n)) 结果 (0, 1) <class 'tuple'> (1, 2) <class 'tuple'> (2, [3, 4]) <class 'tuple'>
2、lambda函数:冒号左边为函数参数,返回的右边表达式的值,没有返回值时默认返回none
def sum1(x,y): return x+y sum2=lambda x,y:x+y x=(1,2) print(sum1(*x),sum2(*x)) ----------- 3 3
3、map:对迭代对象中的每个元素做操作
def add(x): return x*3 def squral(x): return x**x num1=[1,2,3] num2=[4,5,6] print("基础应用:",list(map(lambda x:x*2,num1))) print("多个迭代对象:",list(map(lambda x,y:x+y,num1,num2))) print("以函数名元组作为迭代对象:",list(map(lambda x,y:x(y),(add,squral),num1))) 结果-------------- 基础应用: [2, 4, 6] 多个迭代对象: [5, 7, 9] 以函数名元组作为迭代对象: [3, 4]
4、reduce:对每个元素进行累积操作
- function -- 函数,有两个参数下,举例:lambda x,y:x+y
- iterable -- 可迭代对象
- initializer -- 可选,初始参数,使用初始参数时,将值先传给函数第一个参数作为初始值
from functools import reduce 先获取迭代对象中前两个元素进行操作,得到的结果再与第三个元素进行同样的操作,累积操作,下面是求1到100的和 print(reduce(lambda x,y:x+y,[i for i in range(1,101)])) 5050 第三个参数的用法 score=[{"name":"lisi","math":76,"gender":"male"}, {"name":"zhangsan","math":45,"gender":"female"}, {"name":"wangwu","math":64,"gender":"female"}, {"name":"zhaoliu","math":83,"gender":"male"}] print(reduce(lambda x,y:x+y["math"],score,0)) 268
5、filter
score=[{"name":"lisi","math":76,"gender":"male"},
{"name":"zhangsan","math":45,"gender":"female"},
{"name":"wangwu","math":64,"gender":"female"},
{"name":"zhaoliu","math":83,"gender":"male"}]
过滤为男性的学生
print(list(filter(lambda x:x["gender"]=="male" ,score)))
结果--------------
[{'name': 'lisi', 'math': 76, 'gender': 'male'},
{'name': 'zhaoliu', 'math': 83, 'gender': 'male'}]
6、sorted(iterable, /, *, key=None, reverse=False)和列表中list.sort(cmp=None, key=None, reverse=False)的用法
sorted()参数:
iterable:必须是可迭代对象,如list,dict.items()等
key:指定一个函数作为排序的依据,输入迭代中的对象作为参数
reverse:为true是降序排序,默认false升序排序
对字典排序 score={"yingzhneg":23,"zhaogao":53,"litang":43,"yangzong":14} xxx=sorted(score.items(),key=lambda x:x[1]) print(xxx) print(dict(xxx)) ---------------------------- [('yangzong', 14), ('yingzhneg', 23), ('litang', 43), ('zhaogao', 53)] {'yangzong': 14, 'yingzhneg': 23, 'litang': 43, 'zhaogao': 53}
7、eval(expr):动态执行expr字符串代码
def cal(a,b,m): return eval("{}{}{}".format(a,m,b)) print(cal(1,1,'-')) print(cal(1,1,'/')) 结果 0 1.0
8、globals():获取所有全局变量字段,也可以用来动态创建函数和类
def aaa(): print(aaa.__name__) class BBB():b=3 globals()['ccc']=aaa globals()['DDD']=BBB ccc() print(DDD.b) 结果: aaa 3
9、ord(s):返回单个字符s的ASCLL数值
10、zip()
11、divmod(a,b):返回a/b的(除数,余数)
十三、元类
例如:有一个Student类,默认继承object
1、在程序运行时, 内存中会创建一个对象Student,而这个对象(类)也能继续创建对象(类)
2、由于类也是对象,可以将其看作是一个变量,可以赋值给其他变量,可以增删属性,也可以作为参数传递,更可以在函数中动态创建一个类(就是在函数中用class关键字定义一个类)
3、元类就是创建类的类,通常用来拦截和修改类的创建过程,如通过元类实现的单例模式
4、用type查看类型,实例对象的类型是基类,基类的类型是元类,元类的类型type
5、object是由type创建的,type也是type创建的
type动态创建类,这里的type实质上就是一个元类,举例
@staticmethod def aaa(): print("函数aaa") class BBB: def ccc(self): print("方法bbb") EEE=type("DDD",(BBB,),{'func':aaa,'value':3}) #类DDD继承BBB然后赋值给EEE,有方法func,属性value print(type(EEE)) EEE().ccc() EEE().func() #这里函数aaa没有参数获取self就会报错,除非是静态函数 print(EEE().value)
结果 <class 'type'> 方法bbb 函数aaa 3
自定义元类,举例
def zzz(name, bases, attrs): attrs['Author']='Megvii' return type(name, bases, attrs) class AAA(type): def __new__(cls, *args, **kwargs): if not hasattr(AAA,'n'): AAA.n=0 AAA.n+=1 print(cls.__name__, "实例化了{:0>3}个".format(AAA.n)) return super().__new__(cls, *args, **kwargs) class BBB(metaclass=AAA): pass class DDD(metaclass=AAA): pass print(BBB.n) 结果 AAA 实例化了001个 AAA 实例化了002个 2
14、python自带的sys、os库
十五、排序算法
参考:[算法总结] 十大排序算法 - 知乎 (zhihu.com)
import random, string, operator,math #1、冒泡排序:每次遍历不断交换元素 def Bubbling_Sort(): tup = random.sample(string.digits, 7) print(str(tup)) for i in range(1, len(tup)): for j in range(0, len(tup) - i): if tup[j] > tup[j + 1]: tup[j], tup[j + 1] = tup[j + 1], tup[j] print(str(tup)) #2、选择排序:选择遍历中最小/最大元素与起始元素交换 def Select_Sort(): tup = random.sample(string.digits, 5) print(str(tup)) for i in range(len(tup) - 1): min_num = i for j in range(i + 1, len(tup)): if tup[j] < tup[min_num]: min_num = j if i != min_num: tup[i], tup[min_num] = tup[min_num], tup[i] print(str(tup)) #3、插入排序:将起始元素之前的序列视作有序序列,然后遍历起始元素之后序列中的元素与它之前的元素作比较,插入到有序序列中适合的位置 def Insert_Sort(): tup = random.sample(string.digits, 5) for i in range(len(tup)): pre_index = i - 1 current = tup[i] while pre_index >= 0 and tup[pre_index] > current: tup[pre_index + 1] = tup[pre_index] pre_index -= 1 tup[pre_index + 1] = current print(str(tup)) #4、希尔排序 def Shell_Sort(): tup = random.sample(string.digits, 10) print(str(tup), type(tup)) gap = len(tup) // 3 print('gap=', gap) while gap > 0: for i in range(gap, len(tup)): temp = tup[i] j = i - gap while j >= 0 and tup[j] > temp: tup[j + gap] = tup[j] j -= gap tup[j + gap] = temp gap = math.floor(gap / 3) print(str(tup)) #5、归并排序:先不断分割列表,直到每个列表中元素只剩一个;然后依次比较合并列表; def Merge_Sort(): tup = random.sample(string.digits, 5) def merge_divide(arr): #分割动作,将不断分割视作一个动作 if len(arr) < 2: #分割动作终止标志,直到列表元素只有一个输出列表 return arr middle = math.floor(len(arr) / 2) # 下舍中数 left, right = arr[:middle], arr[middle:] return merge(merge_divide(left), merge_divide(right)) #递归调用自身 def merge(left, right): #合并动作,比较left和right两个列表的元素,返回一个有序列表 res = [] while left and right: if left[0] <= right[0]: res.append(left.pop(0)) else: res.append(right.pop(0)) if left or right: res.extend(left) res.extend(right) return res print(merge_divide(tup)) #6、快速排序:以分区第一个数为基准数,比它大的放后边,比它小的放前边
排序前:['4', '9', '5', '7', '2', '3', '1']
-------------------------------------------
第一轮:['1', '3', '2', '4', '7', '5', '9']
第二轮:['1', '3', '2', '4', '7', '5', '9']
第三轮:['1', '2', '3', '4', '7', '5', '9']
第四轮:['1', '2', '3', '4', '5', '7', '9']
第五轮:['1', '2', '3', '4', '5', '7', '9']
temp=4 #分区第一轮排序详解,以列表第一个数为基准temp=4,
right找出比它小的数,left找出比它大的数,然后交换位置,right<=left时,将left位置赋予基准值
1957231 #while第一个循环:right找到了1,然后list[left]=1,此时就是left[0]=1
1957239 # left找到了1,然后list[right]=9,此时就是left[1]=9
1357239 #while第二个循环:right找到了3,然后list[left]=3,此时就是left[1]=3
1357259 # left找到了5,然后list[right]=5,此时就是left[6]=5
1327259 #while第三个循环:right找到了2,然后list[left]=2,此时就是left[4]=2
1327759 # left找到了7,然后list[right]=7,此时就是left[5]=5
1324759 #while循环外:list[left]=temp,也就是left[3]=4
def Quick_Sort(): tup = random.sample(string.digits, 7) def part(arr, left, right): temp = arr[left] while right > left: while arr[right] >= temp and right > left: right -= 1 arr[left] = arr[right] while arr[left] < temp and right > left: left += 1 arr[right] = arr[left] arr[left] = temp return left def quick(arr, left=None, right=None): left = 0 if not isinstance(left, int) else left right = len(arr) - 1 if not isinstance(right, int) else right if right > left: mid_index = part(arr, left, right) quick(arr, left, mid_index - 1) quick(arr, mid_index + 1, right) return arr print(str(quick(tup)))
泛型函数

安装PyQt5
pip install PyQt5 -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
pip install PyQt5-tools -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
python -m pip install --upgrade pip -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
安装anaconda
https://blog.csdn.net/fan18317517352/article/details/123035625
本文来自博客园,作者:执剑之心,转载请注明原文链接:https://www.cnblogs.com/ldzcy/p/15789609.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· Manus的开源复刻OpenManus初探
· AI 智能体引爆开源社区「GitHub 热点速览」
· 三行代码完成国际化适配,妙~啊~
· .NET Core 中如何实现缓存的预热?