寒假作业2/2
作业基本信息
| 这个作业属于哪个课程 | 2021春软件工程实践|W班(福州大学) |
|---|---|
| 这个作业要求在哪里 | 作业要求 |
| 这个作业的目标 | 阅读构建之法,提出5-10个问题 词频统计程序的编程 |
| 其他参考文献 | 无 |
任务一:阅读《构建之法》并提出问题
问题一:
在2.1.2中,作者认为,单元测试必须由最熟悉代码的人,也就是程序的作者来编写,从大体上来讲,我是支持这个想法的,毕竟代码的作者是最了解代码的目的、特点、流程的人。但是,有时候可能往往因为这代码是自己写的,自己的想法就已经局限在这里面了,就没有意识到某些问题。比如这次作业的单元测试环节,我在编写写测试样例的时候,能想到的例子往往都是在编写代码时候有考虑到的情况了,而一些潜在的易错的点往往自己却不容易发现,因此我认为作者该处的说法并不完全正确。
问题二:
在4.5.2中,作者提出了结对编程的协助模式,每人在各自独立设计、实现软件的过程中不免要犯这样那样的错误。在结对编程中,因为有随时的复审和交流,程序各方面的质量取决于一对程序员中各方面水平较高的那一位。这样,程序中的错误就会少很多,程序的厨师质量就会高很多,这样会省下很多以后修改、测试的时间。书中介绍了不少关于结对编程所带来的好处,这里就不详细列举。不过,在我看来,作者的想法是否过于理想化?如果回归到现实,在一些相对极端的情况下如两个同学编程经验都不多,这样是不是就等于一对跨了呢?又或者出现"一神带一坑"的情况,编程能力高的人是否会被拖后腿,编程能力低的是不是就可以"躺赢"呢?
问题三:
在5.3.6中,作者介绍了一种名为MVP(Minimum Viable Product)——最小功能集的方法,它的具体做法是把产品最核心的功能用最小成本实现或描绘出来,然后快速征求用户意见。诚然,该开发方法符合敏捷思想,它适用于市场不确定的情况下,通过设计实验来快速检验产品是否可行。
但是,MVP这种方法是任何时候都可行的吗?如果乔布斯发布的是最小可用的 iPhone,我们是不是会得出结论说大家更喜欢键盘?如果 Tesla(电动车)制造的是最小可用汽车,还有没有人去开它?带着我的疑惑我上网查找了资料,有人解释到,这不是“最小可用”理念本身的问题,硬件不是免费的而且也不能方便快速更新,所以说只是有些市场不合适。但是我还是不太懂,就好比饿了么跟美团两家公司,如果它们只是把最核心的功能——"点外卖"(我个人理解是这样)做出来,在市场上他们会不会失去竞争的能力?所以,MVP的方法在什么情况下最适用呢?
问题四:
在12.2中,作者在介绍用户体验设计和步骤时讲到,用户体验设计的一个重要目的就是降低用户的认知阻力,即用户对软件界面的认知和实际结果的差异。
读完这段话我产生了一些思考,是不是说认知阻力极大的软件会降低用户的体验感?这里举一个关于自己的例子,曾经有段时间我的同学强烈给我推荐vim编辑器,据说各种便捷、强大、无所不能、不可思议、上天入地等等等等,当时我就兴致勃勃地去学习了各个命令并且在常用的IDE里面安装了插件强迫着自己去使用,但是对于刚入门的我来说这个认知过程总感觉磕磕绊绊,甚至在赶作业ddl的时候心中有了卸载的冲动。对此我想问的是,针对这种专业性较强的软件来讲,降低认知阻力还是用户体验设计的一个重要目的吗?还是说在一些情况下,总有一些软件是开发给那些需要功能强大,忽略认知阻力的受用团体的?
问题五:
在17章人、绩效和职业道德中,这里讲到对于创造性思维的活动来说,创造力的激发和金钱成反比。对此我存在疑惑,为何两者会形成负相关的关系?在我上网查阅资料之后,了解到,参考的文献中通过一个实验说明了虽然基础良好的待遇的工作环境,是基本的保障,人们在良好的基础保障上在发挥创造力,就是现实的可操作的。但是人脑其实非常孱弱,因此要好好发挥其灵光闪耀,则必须提供和营造良好的分享氛围,强调和激励工作人员去关注创造力本身,而不去纠结奖金激励。我对此想法是赞同的,但是我认为作者观点中金钱与创造力不是简单的形成反比,它们一个是有一个临界条件的。
附加题:关于著名的计算机科学家Donald E. Knuth和他的排版软件TeX的趣事
Donald E. Knuth在写完《计算机程序设计艺术》(The Art of Computer Programming,TAOCP)第三卷后,由于对当时粗糙的排版技术忍无可忍,开始开发排版软件TeX。他原本以为只需要半年时间就能完成,但最终用了超过十年时间,直到1989年TeX才最终停止修改。
TeX的版本号码十分有趣。从TeX第三版开始,之后的升级是在小数点后加入一个新数位,使之越来越接近圆周率π的值。当前版本的TeX是3.14159265,它的最后更新时间是2014-01-12。这显示了TeX已经十分稳定,任何的升级都十分细微。高德纳曾表示“最后一次升级是(于我过世后)将版本数改为π,那时任何余下的漏洞将被看作程序的功能。”
TeX是非常稳定的程序,高德纳悬赏奖励任何能够在TeX中发现程序漏洞(bug)的人。每一个漏洞的奖励金额从2.56美元开始,并每年翻倍,直到目前的327.68美元封顶。然而高德纳从未因此而损失大笔金钱,因为TeX中的漏洞少之又少,而真正发现漏洞的人在获得支票后,宁愿将其裱起来留作纪念也不愿拿去兑现。
引用链接click here
任务二:WordCount编程
github地址
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 15 | 20 |
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 60 | 90 |
| • Design Spec | • 生成设计文档 | 30 | 30 |
| • Design Review | • 设计复审 | 20 | 30 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 120 | 90 |
| • Design | • 具体设计 | 30 | 40 |
| • Coding | • 具体编码 | 300 | 360 |
| • Code Review | • 代码复审 | 20 | 20 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 40 | 30 |
| Reporting | 报告 | ||
| • Test Repor | • 测试报告 | 30 | 40 |
| • Size Measurement | • 计算工作量 | 20 | 15 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 15 | 15 |
| 合计 | 700 | 780 |
解题思路
在阅读完任务儿WordCount的需求说明后,首先对需求做了分析,任务主要做的是对文件文本的一些指标的统计,当时大致的思路就是先使用java的IO工具,对文件的文本进行获取,然后在核心Core中分别实现各个统计功能,通过IO工具将文本处理后交付给核心Core处理。处理完之后将统计信息通过IO工具写入输出文件。
该任务主要的是核心部分的实现,具体思路如下:
- 字符数可以通过逐个读取字符进行累加;
- 单词数的统计首先需要剔除非法的分隔符,然后对各个字符子串进行正则匹配;
- 行数也可以利用正则表达式;
- 词频统计通过对存在map中的"单词:数量"键值对进行自定义排序,排序规则为——value大的优先,value相等的按key的字典序前的优先。
代码规范制定链接
设计与实现过程
模块划分
在做完需求分析之后,我将该任务划分为三个模块,分别是:程序入口,文件IO模块,计算统计模块。
因此我的项目目录结构为

函数及其关系
- FileIO
-
public static BufferedReader readFromFile(File inputFile)对输入文件进行读取操作 -
public static void writeToFile(File outputFile, String content)将处理的结果写入到输出文件中
-
- WordCount
public static void main(String[] args)项目程序的入口,调用readFromFile方法获得BufferedReader对象,作为参数传递给CountCore.java, 在CountCore.java中调用它内部的函数进行统计计算,并且得到其返回的结果。将结果按需求中的结构组织好之后,调用writeToFile方法,将内容写入到文件中。
- CountCore
-
public static int characterCount(BufferedReader bufferedReader)对字符进行统计 -
public static boolean isWord(String string)判断字符子串是否是合法的单词 -
public static Map<String,Integer> wordStore(BufferedReader bufferedReader)对每一个合法的单词进行存储,结果以单词名-单词数量形式的键值对存进map集合 -
public static int wordCount(BufferedReader bufferedReader)调用wordStore方法得到map,对map进行遍历,对单词总数进行统计 -
public static int lineCount(BufferedReader bufferedReader)对文本的行数进行统计 -
public static List<Map.Entry<String,Integer>> sortByFrequency(Map<String,Integer> map)对存在map中的"单词:数量"键值对进行自定义排序,排序规则为——value大的优先,value相等的按key的字典序前的优先
-
关键代码
...
String str;
while((str=bufferedReader.readLine())!=null){
str=str.toLowerCase().replaceAll(splitRegex," ");
//将分隔符全部替换成" "
StringTokenizer stringTokenizer=new StringTokenizer(str);
while(stringTokenizer.hasMoreTokens()) {
String substring = stringTokenizer.nextToken();
if (isWord(substring) && result.containsKey(substring)) {
int frequency = result.get(substring);
result.put(substring, frequency + 1);
} else if (isWord(substring) && (!result.containsKey(substring))) {
result.put(substring, 1);
}
}
}
...
public static List<Map.Entry<String,Integer>> sortByFrequency(Map<String,Integer> map){
List<Map.Entry<String,Integer>> list=new ArrayList<>(map.entrySet());
Collections.sort(list, new Comparator<Map.Entry<String, Integer>>() {
@Override
public int compare(Map.Entry<String, Integer> o1, Map.Entry<String, Integer> o2) {
return o1.getValue().equals(o2.getValue())?
o1.getKey().compareTo(o2.getKey()):o2.getValue()-o1.getValue();
}
});
return list;
}
性能改进
- 本次作业中,性能改进的思路主要是从IO方向入手,一开始想选用的是
FileReader和FileWriter进行文件的读写,原因是之前学习的过程中运用得比较多,相对不陌生。但经过上网查阅了多数资料后,了解到BufferedReader和BufferedWriter在内存中会自带一个8kb的字节缓冲区,并且他提供了一个程序员比较喜欢用的方法readLine();方法,它更加方便且效率更高 - 对于字符串的处理,之前常常是使用String,此作业中使用到了StringBuilder,它的对象表示的字符串是可以改变的,能够动态创建string,以克服string对象恒定性带来的性能影响。
单元测试
- 测试覆盖率截图
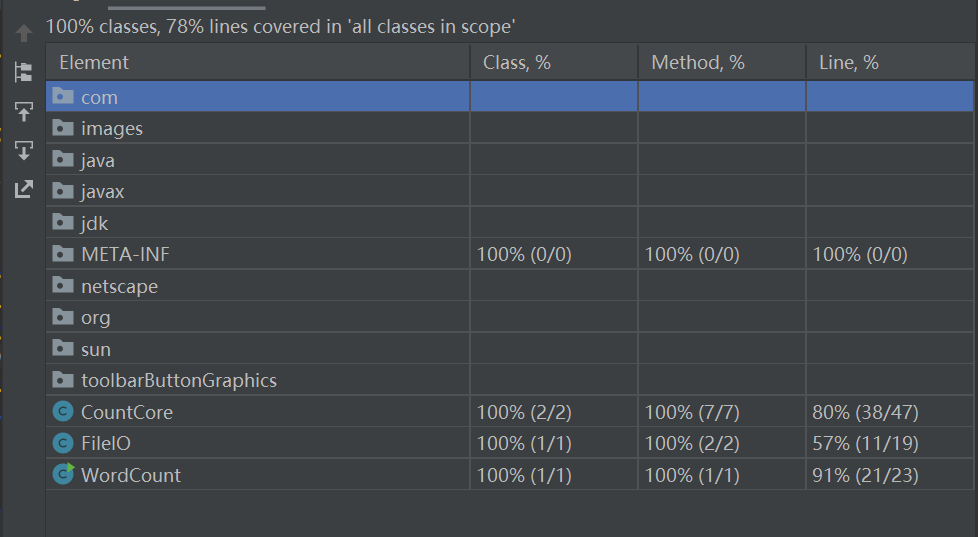
- 部分单元测试代码如下
@Test
public void testWordCount() throws Exception {
//TODO: Test goes here...
File file=new File("testInput.txt");
BufferedReader bufferedReader=FileIO.readFromFile(file);
int result= CountCore.wordCount(bufferedReader);
Assert.assertEquals(4300,result);
}
- 测试思路
- 4+个纯字母的合法单词如
abcd、software - 小于4个纯字母的非法单词如
aaa - 数字与字母混合,非连续4个字母开头 如
abc1de23 - 数字与字母混合,连续4+个字母开头如
hello123 - 相同词频不同字典序
- 仅有空白字符
- 多行换行
...
总之,就是将文中能够出现的字符的类型进行排列组合,构造出尽量涵盖可能出错的范围,不重不漏
- 4+个纯字母的合法单词如
异常处理
本次作业中可能遇到的异常如下:
- 文件不存在异常,所做处理如下
try {
...
} catch (FileNotFoundException e) {
System.out.println("文件不存在");
e.printStackTrace();
}
- 参数输入有误,所做处理如下
if(args.length!=2){
System.out.println("输入的参数个数有误,请检查后重写输入!");
return;
}
心路历程与收获
刚开始阅读完题目题目的需求时,并没有很认真去思考其中的细节,大部分的时间都花在构思如何架构这个项目,使得Core核心模块能够独立地分离出来。再确定了大致的模块划分之后又陷入到了IO工具的选择,应该选择什么样的IO工具类才能更方便、更高效呢?这也是当时犹豫许久的一个问题。在刚开始对于合法单词、空行等一些指标的判断,我仍然停留在用较为直接粗暴的if-else分支+.equals()特判的方法进行处理,在同学热心的帮助指导下,我学习了解了正则表达式,简单明了地实现了匹配规则,简化了不少代码。
本次作业中,我巩固了github的使用,相比与之前只是单纯地将一整个项目写好提交上去,这次的多次commit和最后的pull request,让我慢慢体会到了它协同工作时发挥的作用。本次作业中我也重新对自己之前代码风格做了更深刻的规范和调整,希望自己以后能够严格遵守规范,让自己的代码可阅读性提高。除此之外,我还学习到了之前所忽视的单元测试,使我们的工作完成得更轻松,而且会令我们的设计变得更好,甚至大大减少花在调试上面的时间。
总之,本次作业带给了我不少成长,让我认识到了即使一项小的任务,想要把它做得完美也是很难的一件事,它不仅需要逻辑思路,还需要综合考虑多个方面的指标,如性能、耦合性、实现可行性等等。
