
【Flask源码分析——请求上下文与应用上下文】
Flask中有两种上下文,请求上下文和应用上下文。两者的作用域都处于一个请求的局部中。
查看源代码,上下文类在flask.ctx模块中定义
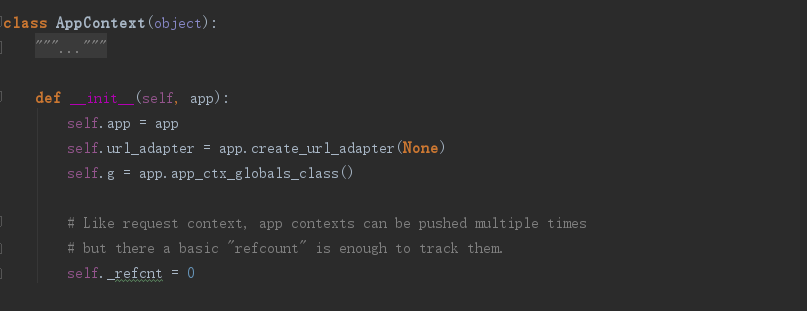
AppContext类定义应用上下文,app是当前应用Web对象的引用,g是当前请求内全局变量,每个请求的g都是独立的,在整个请求内都是全局可访问修改的。
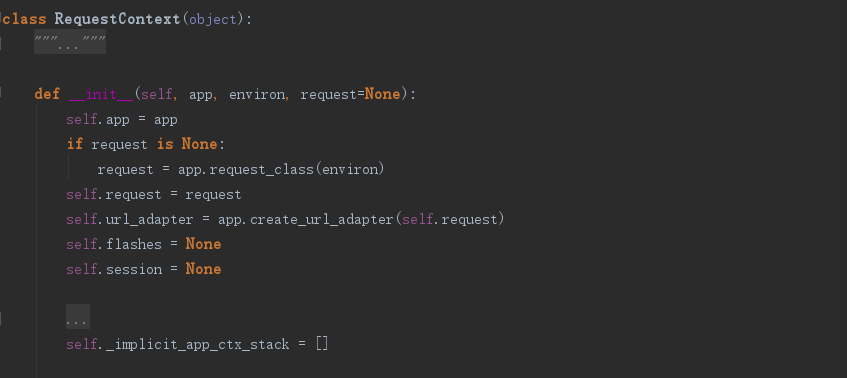
RequestContext类定义请求上下文,request、session是所熟悉的经常用到的,app涵义和AppContext中相同。
上下文对象的作用域:
先说结论:请求上下文和应用上下文一样,他们的作用域是当前请求内,在当前请求内全局可访问。
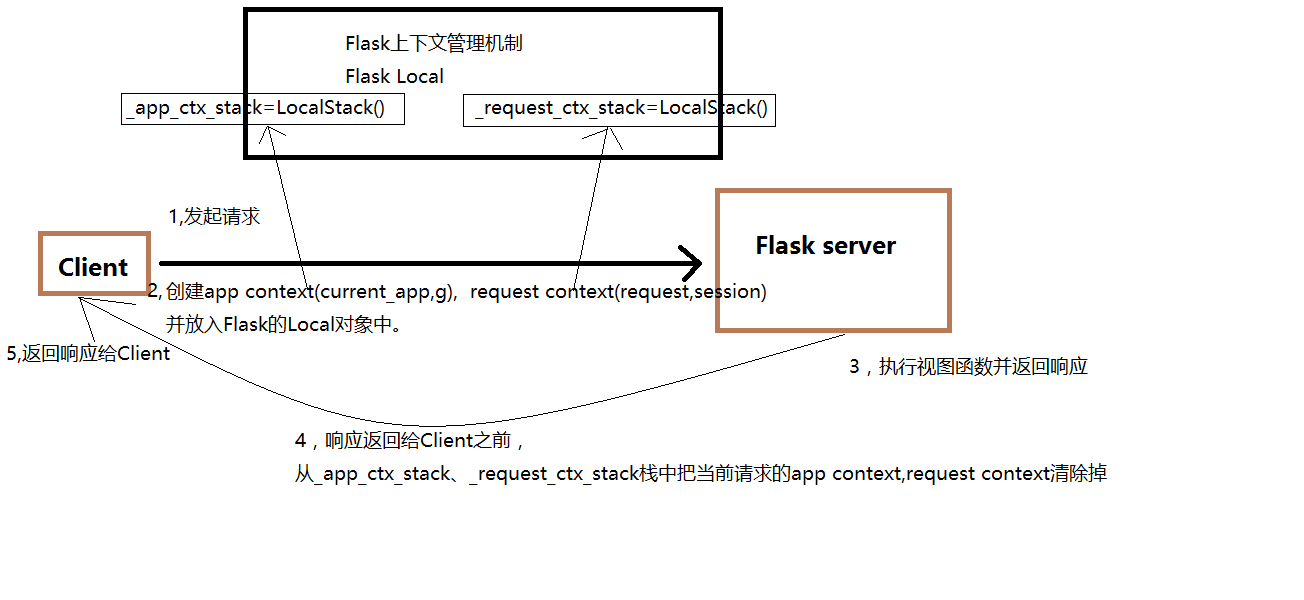
线程中用ThreadLocal类实现线程间的隔离。同样的,werkzeug实现了自己的线程隔离类werkzeug.local.Local,看下图Flask处理一个请求的中间过程
LocalStack类是flask定义的用于线程隔离的栈存储对象,_app_ctx_stack和_request_ctx_stack由LocalStack类定义,分别用来保存应用和请求上下文。
(线程隔离:每个线程只能看到自己的结果,对于不同的线程,它们访问这两个对象看到的结果是不一样的、完全隔离的。这是根据线程pid的不同实现的。)
他们的定义在flask.globals模块中:
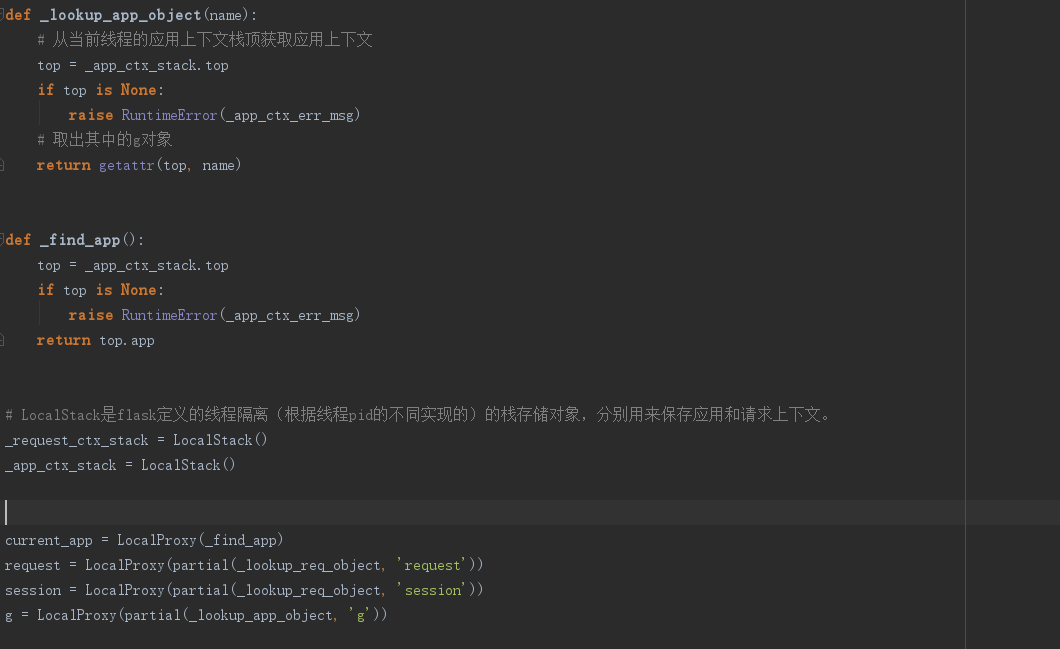
其中也定义了current,session等常用请求内全局对象,他们用LocalProxy定义,LocalProxy类的构造函数接收一个callable参数,上面这几个就传入了一个偏函数。以g为例,当对g进行操作时,就会调用作为参数的偏函数,并把操作转发到偏函数返回的对象上。
例如g对象的调用过程:
- 从当前线程应用上下文栈顶获取应用上下文
- 取出其中的g对象
- 进行操作
由图中flask处理请求的过程可知,客户端发起请求,创建了应用请求上下文并且推送到对应栈内,待flask server处理完成返回响应给客户端前,从栈中把当前请求的应用请求上下文删除掉,再返回响应给客户端就完成了一次完整的请求处理过程。
又因为每个应用里线程同时只处理一个请求,故上请求、应用下文栈肯定只有一个对象。并且,在请求结束后都会释放,所以新的请求来的时候都会重新推送两个上下文。
上下文的推送
Flask对象调用run()作为WSGI 应用启动后,每当有请求进入时,Flask调用push函数推送请求上下文
来看RequestContext类源码,push函数:
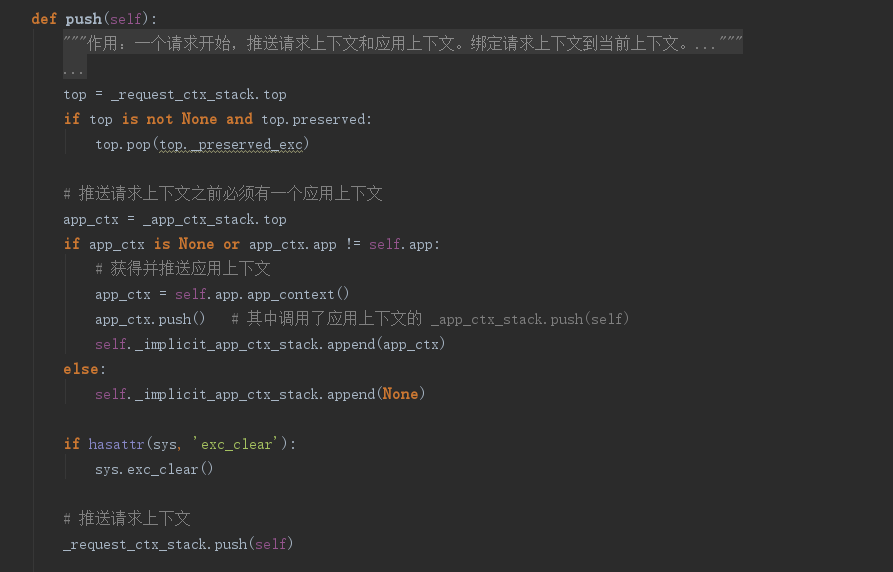
在推送请求上下文之前必须有应用上下文,Flask会检查当前线程的应用上下文栈顶是否有应用上下文:
- 如果有,判断与请求上下文是否属于同一个应用,(在单WSGI应用的程序中无意义,因为只创建一个app)
- 如果没有,就会推送一个当前应用的上下文,并记录下来。
请求处理结束,调用auto_pop函数,其中又调用自身的pop函数:
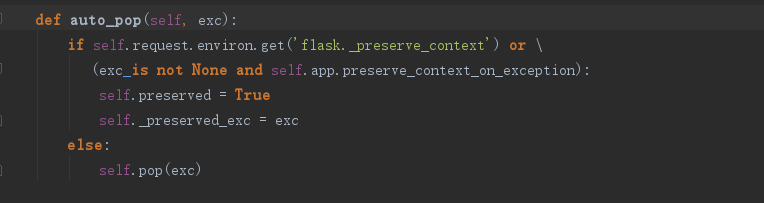
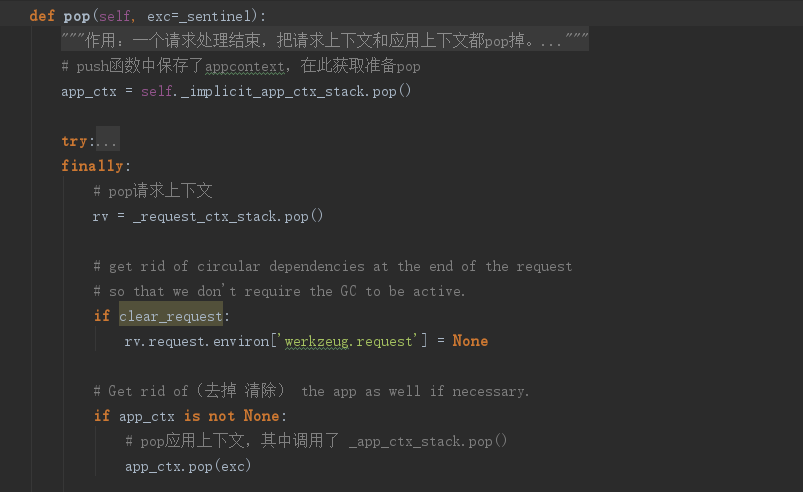
在pop函数中会把请求上下文和应用上下文都pop掉。
应用上下文AppContext源码,push,pop函数:
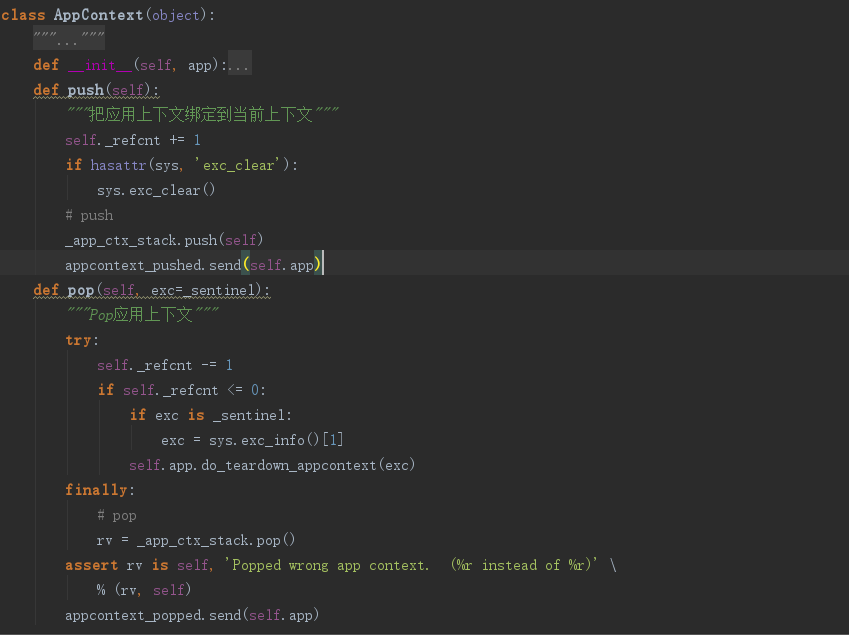
所以,在每个WSGI应用里,每个请求的两个上下文都是完全独立的,每次请求到来的时候都会推送请求上下文和应用上下文。如果应用上下文不存在,则会隐式的创建。
那么还有两个问题:
①应用和请求上下文在运行时都是线程隔离的,为何要分开来?
②每个线程同时只处理一个请求,上下文栈肯定只有一个对象,为何要用栈来存储?
参考其他资料后得出:这两个设计都是为了在离线状态下调试用。 下图是一位前辈的总结
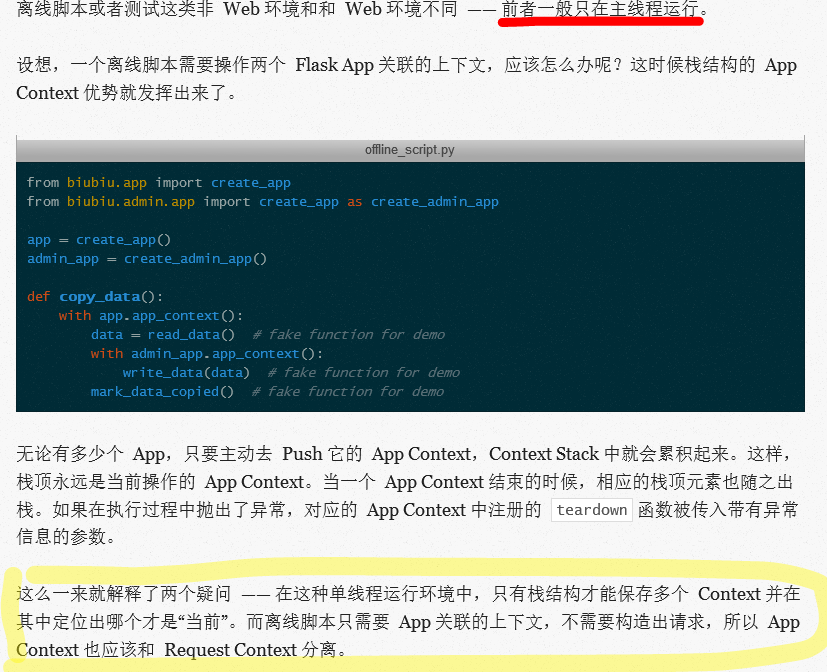
小结:
对于flask编程来说,只有一个应用上的结论:每个请求的g都是独立的,并且在整个请求内都是全局可访问修改的。
所以,在每个WSGI应用里,每个请求的两个上下文都是完全独立的,每次请求到来的时候都会推送请求上下文和应用上下文。如果应用上下文不存在,则会隐式的创建。
