
Session机制在页面间保持Cookie——大街网
解决Cookie有效期,页面间Cookie传递
解決大规模,长期有效采集。
之前做一个项目,要采集招聘网站的职位信息,智联,拉钩,中华英才,BOOS,大街网,写完了前4个,大街网数据加载方式是AJAX,高高兴兴写完了,关机睡觉。
第二天早上,XXXXX,大街网失效了,原因是COOKIE具有有效时间,大概10分钟。然后有了这篇文章。
整体思路:
1,开始采集前,先请求一个URL拿到COOKIE。
2,更新会话COOKIE。
3,启动主爬虫采集。大量采集时,不需要每次都请求URL获取COOKIE再更新,设置一个时间,十分钟左右更新一次COOKIE即可,避免了每次爬都请求的时间等待与资源消耗。
示例代码:
# encoding: utf-8 # Author: Timeashore # Email: 1274866364@qq.com '''
大街网 requests.Session()会话保持Cookie一直有效 s.cookies.update() ''' import requests import pprint header = { "user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36", "referer" : "https://so.dajie.com/job/search?keyword=python&from=job&clicktype=blank" } # ---------获取一个起始Cookie,用来启动整个爬虫------------------- url = 'https://so.dajie.com/job/search?keyword=python&from=job&clicktype=blank' # 创建一个新会话 s = requests.Session() content = s.get(url, headers=header) print("SO_COOKIE_V2 : ", content.cookies['SO_COOKIE_V2']) # -----------更新会话Cookie,换成刚获取的Cookie------------------- s.cookies.update({"SO_COOKIE_V2" : content.cookies['SO_COOKIE_V2']}) url2 = 'https://so.dajie.com/job/ajax/search/filter?keyword=%E4%BA%92%E8%81%94%E7%BD%91%E4%BA%A7%E5%93%81%E7%BB%8F%E7%90%86&order=0&city=&recruitType=&salary=&experience=&page=1&positionFunction=&_CSRFToken=&ajax=1' c = s.get(url2, headers=header) # 发请求,会话里携带着更新后的Cookie,保证请求有效 pprint.pprint(c.text)
运行结果:
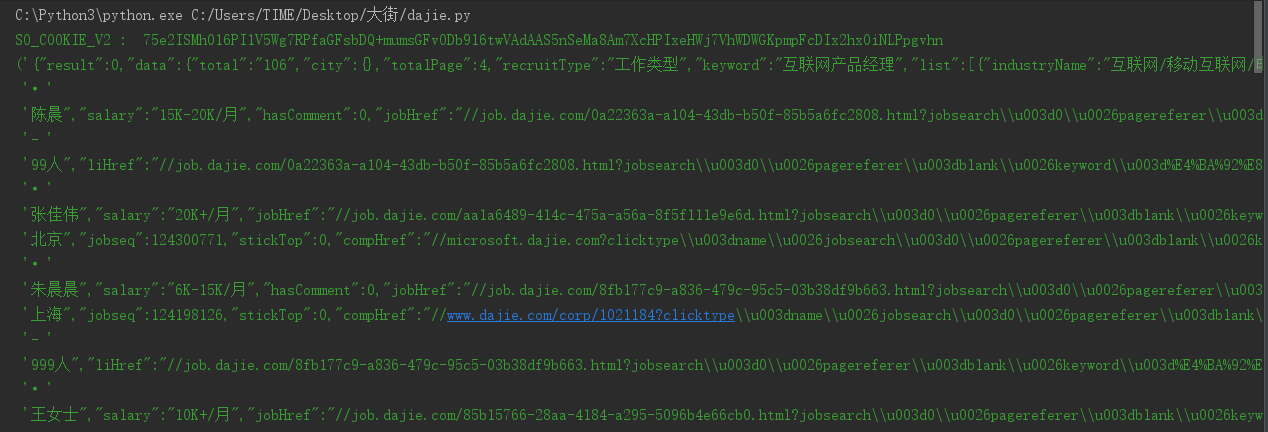
requests使用socks5代理示例:
import requests proxy = 'socks5://127.0.0.1:1080' proxies = {'http': proxy, 'https': proxy} headers = { 'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.81 Safari/537.36', 'Cookie': 'BIDUPSID=BF8CC8E28BEE6F632F17266972E50A19;......'
} response = requests.get('https://www.baidu.com/s?&wd=ip', headers=headers, proxies=proxies) print(response.text)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号