
线上SpringCloud网关调用微服务跨机房了,咋整?
1、前言
公司内考虑到服务器资源成本的问题,目前业务上还在进行服务的容器化改造和迁移,计划将容器化后的服务,以及一些中间件(MQ、DB、ES、Redis等)尽量都迁移到其他机房。
那你们为什么不用阿里云啊,腾讯云啊,还用自己的机房?
的确是这样,公司内部目前还是有专门的运维团队。也是因为历史原因,当时业务发展比较迅猛,考虑到数据的安全性也是自建机房的。对于中小型公司这样做,显然成本太高了,所以一般都用阿里云。对于中大型企业或者对数据安全性要求高的公司,自建机房维护的也不再少数。
对于中间件来说,比如 Redis 缓存,有的业务也是因为历史原因,当时上线后都是单独申请,并部署的一套集群,但是量并不是很大,所以类似这种情况的,可以考虑跟其他项目使用的集群合并为一个,这样就可能节省了一部分服务器资源。
现在大多数企业都已经微服务化,容器化了。
所以,将非容器化的业务要求都迁移到容器中,这里的容器基本都是指 Kubernetes 平台了,通过容器发布调度服务,对于运维来说,维护变得更加便捷,高效。
对于研发来说,业务需要部署服务,不再需要重新提 JIRA 工单,走一系列审核流程,最后给到你的可能还是一台虚拟机,依赖的软件单独安装部署。用了容器,只要在 集装箱 中提前安装好所需软件环境,按照发布规范打好镜像,发布服务的过程一路就是 点点点...。

2、线上业务场景介绍
继续来说今天的主题。
有一个项目是 SpringCloud 架构的,其中使用到了 网关 Zuul,并且也使用了到了 Eureka 作为注册中心。
因为该项目提前已经迁移到北京机房节点部署的容器环境,我们最终目标是迁移到其他机房(如:天津机房)。
北京有两个机房:A机房、B机房,因为都在北京,所以两个机房之间的 网络延时 是可以接受的。
微服务也同样在这两个机房之间都有部署。
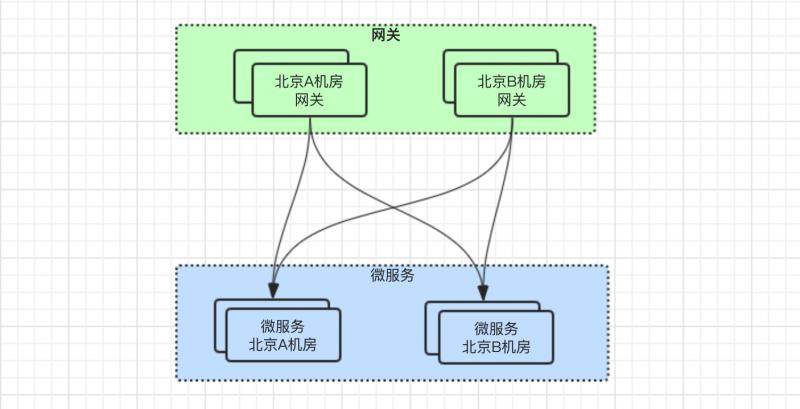
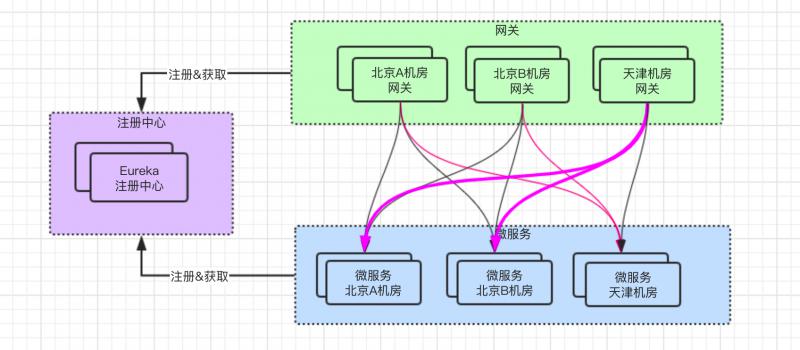
此时,如果只是将微服务部署到 天津机房,会变成如下图所示的关系:
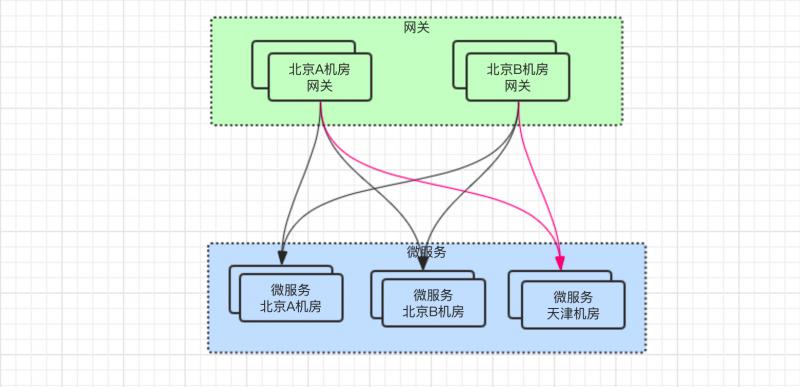
问题很明显,就是网关服务只有北京的,而微服务新增了天津机房的,此时会导致 跨机房调用,即北京网关调用到了天津微服务。
尽管北京到天津 ping 的网络延时仅有 3 毫秒 之差,但是服务与服务之间的调用,可就不止这 3 毫秒了。
其中包括服务器与服务器之间 TCP连接的建立、数据传输的网络开销,如果数据包过大,跨机房访问耗时就会很明显了。
所以呢,尽量避免跨机房访问,当然要将网关也要迁移到天津机房。
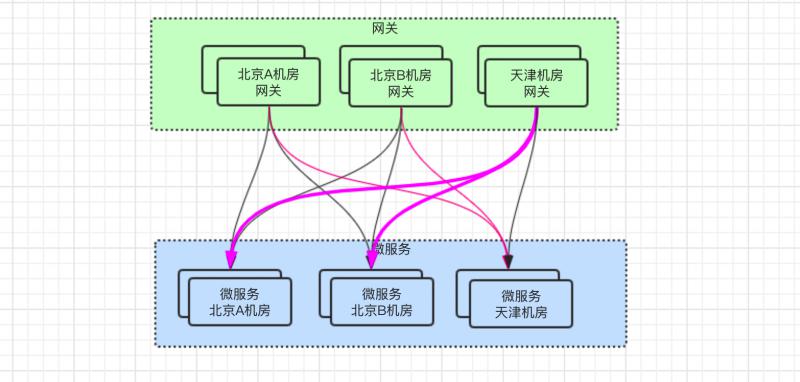
但是,大家看 粉红色粗体 的线条,仍然存在跨机房调用,天津网关调用到北京微服务。
对于线上并发访问量稍微大点,或者有些接口响应体大的,又或者网络抖动等场景下,可能就会导致接口响应时间变长了。
如何解决呢?
因大部分业务都部署到天津,可以将天津机房的服务权重调高
SLB配置 (类Nginx):
upstream {
server 北京机房网关IP 20;
server 天津机房网关IP 80;
}
网关与微服务之间,都是通过 Eureka 注册中心媒介来沟通,即 注册服务 拉取服务。
仅仅在网关层配置好权重还不够,此时还会存在天津网关路由到北京微服务上。
Eureka 内部是基于 Ribbon 实现负载均衡的,自行实现按权重的负载均衡策略,Eureka做一点改造,界面上支持权重的修改。
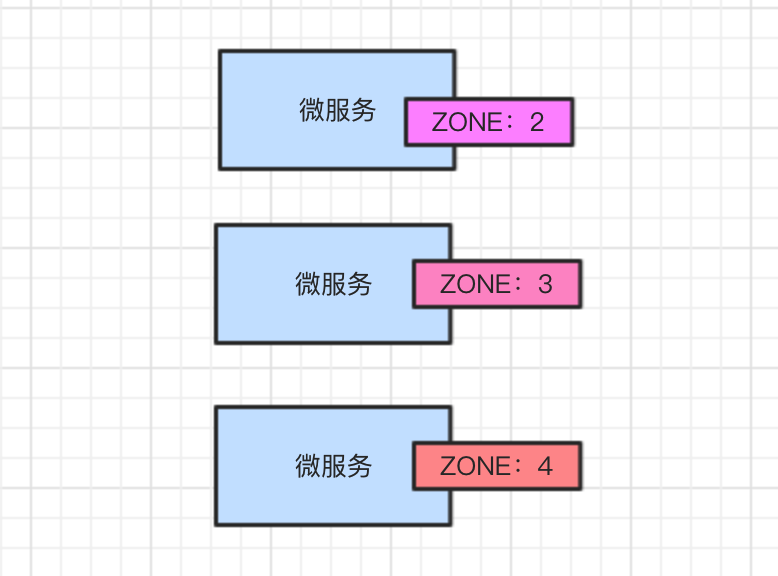
下图截图了部分示例:

IP后面的就是权重值,可以在界面上输入权重值进行调整。
我们可以将北京微服务权重调低,天津微服务权重调高。
相当于网关以及微服务两侧都是通过基于 权重 的负载均衡算法来尽量减少跨机房调用的,但是无法避免跨机房调用。
使用 Eureka 的分区改进
上面描述的方案对于 20% 的流量仍然存在跨机房访问,我们能不能做到先访问同一机房的服务,如果同一机房的服务都不可用了,再访问其他机房的呢?
答案是 可以的。
我们可以借助于 Eureka 注册中心里提供了 region 和 zone 的概念来实现。
region 和 zone 两个概念均来自亚马逊的 AWS:
region:简单理解为地理上的分区,比如亚洲地区,或者华北地区等等,没有具体大小的限制。根据项目情况,自行合理划分 region。
zone:简单理解为 region 内的具体机房,比如说 zone 划分为北京、天津,且北京有两个机房,就可以在 region 内划分为三个zone,北京划分为zone1、zone2,天津为zone3。
结合上面的示例,假设仅设置一个 region 为京津地区。
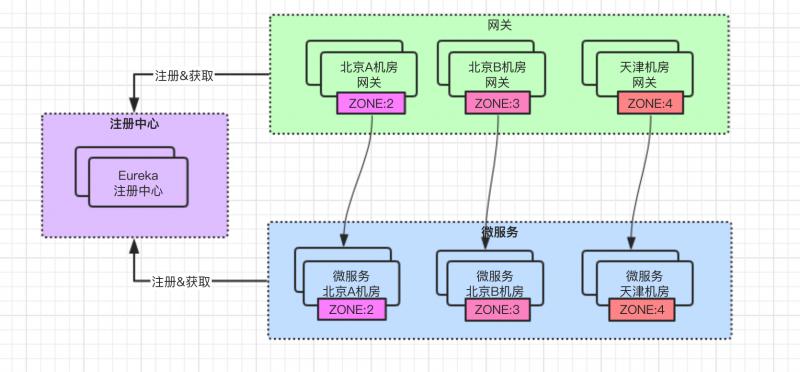
然后我们给这个区域下的网关服务、微服务打上 zone 机房标签,在系统运维上将机房也称作 IDC 数据中心。
网关服务打上zone标签:

微服务打上zone标签:
这个功能都是在 Eureka注册中心 上实现的,在给服务配置 zone 前,调用路径如下所示:
给服务配置 zone 之后,框架内部的路由机制的实现下,调用路径如下所示:
当前使用的 Eureka 是部署在北京,如果想让服务在注册、续约、拉取 动作时也能实现 就近机房访问,部署架构就变成如下这个样子:
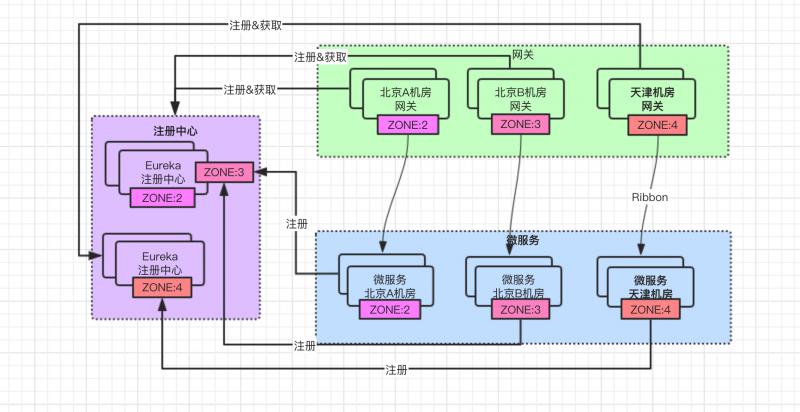
北京区域不同机房假设认为网络延时小,所以北京两个机房可以使用同一个 Eureka 集群;天津可以单独再部署一套 Eureka 集群,这样就可以实现优先路由到同机房访问。
服务注册的关键配置
基本原理就是这样,贴上一段 Eureka 使用 region 和 zone 的配置供大家参考:
spring:
application:
name: mananger
server:
port: ${EUREKA_SERVER_PORT:8011}
eureka:
instance:
# 全网服务实例唯一标识
instance-id: ${EUREKA_SERVER_IP:127.0.0.1}:${server.port}
# 服务实例的meta数据键值对集合,可由注册中心进行服务实例间传递
metadata-map:
# [HA-P配置]-当前服务实例的zone
zone: ${EUREKA_SERVER_ZONE:tz-1}
profiles: ${spring.profiles.active}
# 开启ip,默认为false=》hostname
prefer-ip-address: true
ip-address: ${EUREKA_SERVER_IP:127.0.0.1}
# [HA-P配置]-当前服务实例的region
client:
region: ${EUREKA_SERVER_REGION:cn-bj}
# [HA-P配置]-开启当前服务实例优先发现同zone的注册中心,默认为true
prefer-same-zone-eureka: true
# [服务注册]-允许当前服务实例注册,默认为true
register-with-eureka: true
# [服务续约]-允许当前服务实例获取注册信息,默认为true
fetch-registry: true
# [HA-P配置]-可用region下zone集合
availability-zones:
cn-bj: ${eureka.instance.metadata-map.zone},zone-bj,zone-tj
service-url:
# [HA-P配置]-各zone下注册中心地址列表
zone-bj: http://BJIP1:8011/eureka,http://BJIP2:8012/eureka
zone-tj: http://TJIP1:8013/eureka,http://TJIP2:8014/eureka
prefer-same-zone-eureka :
默认就为true,首先会通过 region 找到 availability-zones 内的第一个 zone,然后通过这个 zone 找到 service-url 对应该机房的注册中心地址列表,并向该列表内的 第一个URL 地址发起注册和心跳,不会再向其它的URL地址发起操作。只有当第一个URL地址注册失败的情况下,才会依次向其它的URL发起操作,重试一定次数仍然失败,会间隔一段心跳时间继续重试。
eureka.instance.metadata-map.zone:
服务提供者和消费者都要配置该参数,表示自己属于哪一个机房的。网关服务也属于消费者,从注册中心拉取到注册表之后会根据这个参数中指定的 zone 进行过滤,过滤后向同 zone 内的服务会有多个实例 ,通过 Ribbon 来实现负载均衡调用。如果同一 zone 内的所有服务都不可用时,会其他 zone 的服务发起调用。
另外注意一点 availability-zones 下 region 的配置是 ${eureka.instance.metadata-map.zone},... 这样配置的好处是,你只要指定好了 eureka.instance.metadata-map.zone,优先会将这个参数放到可用分区下作为第一个 zone 来访问。
Zuul 网关路由分区源码分析
网关使用的 zuul,其内部也是通过 ribbon 和 eureka 的结合来实现服务之间的调用,因为网关实际也是个服务消费者,同样会注册到 eureka 上,被网关拉取过来的注册表里的服务,作为服务提供者,同样会注册到eureka上。
通过一张图把控整个请求的大致脉络:
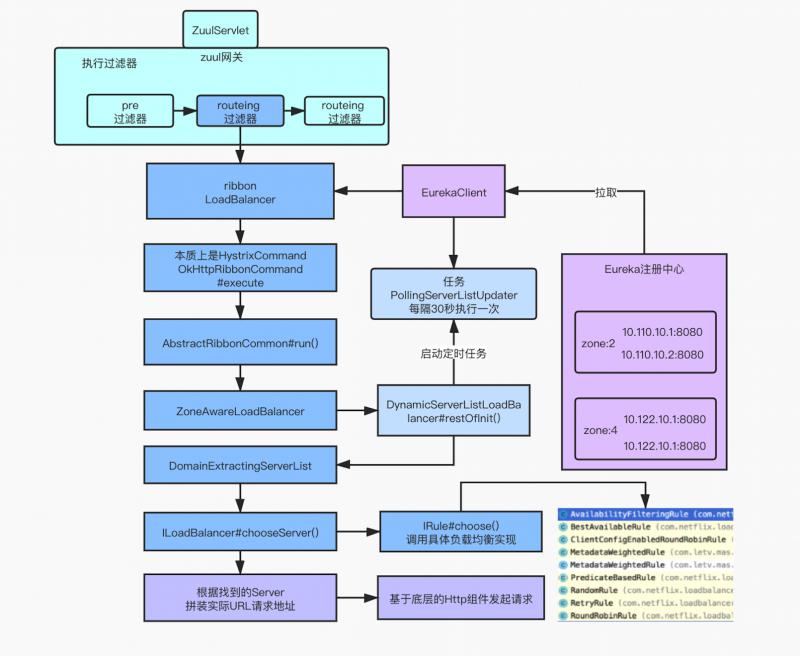
上述图示中部分核心源码如下所示:
PollServerListUpdater#start(final UpdateAction action) 启动后会每隔30秒(默认)去Eureka注册中心拉取一次注册表信息,更新本地缓存的数据结构。
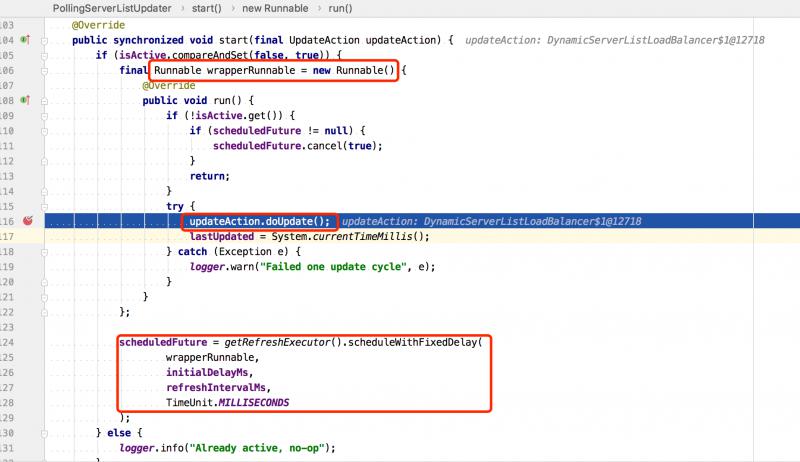
调用到了DyamicServerListLoadBalancer匿名实现类中。
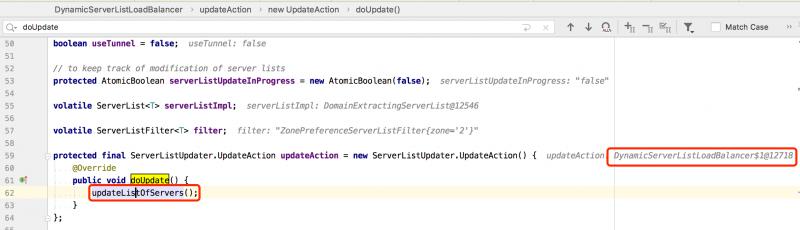
通过DyamicServerListLoadBalancer类调用了 updateListOfServer() 方法更新服务列表,serverListImpl的实现是DiscoveryEnabledNIWSServerList类

在DiscoveryEnabledNIWSServerList类内部会调用 obtainServersViaDiscovery() 方法,其内部通过 EurekaClient 来实现从 Eureka 注册中心拉取服务列表。
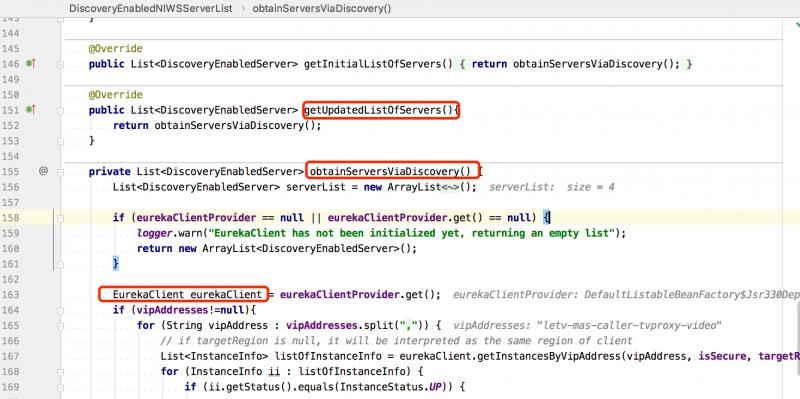
过滤器内部获取同一机房(zone)的服务列表,先后会调用 ZonePreferenceServerListFilter 和 ZoneAffinityServerListFilter 两个过滤器实现 zone 的过滤。
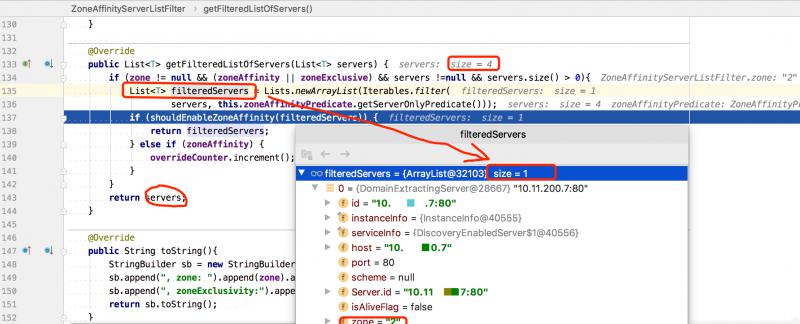
最开始获取的Servers一共是有4条记录,根据调试的代码看,我们是为了获取 zone 为2的服务,所以得到的结果是一条,即 zone = "2" ,说明找到了同 zone 服务。
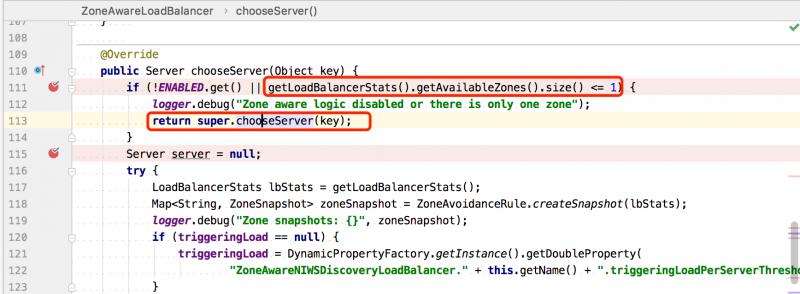
请求接口后会调用到 LoadBalancerContext#getServerFromLoadBalancer(...),内部会调用到ILoadBalancer 具体实现的 chooseServer() 方法,最终会获取到 zone="2" 里的一个Server。
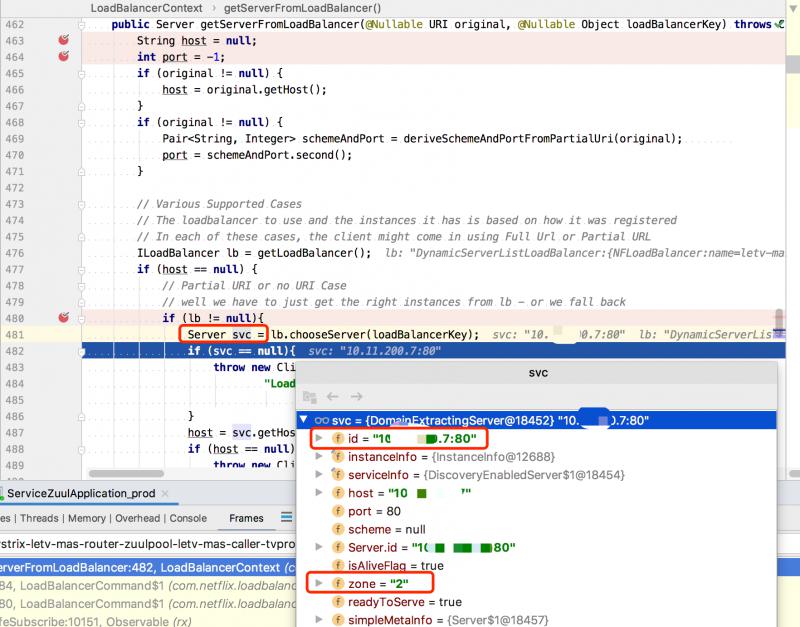
那么这里是如何选择的Server呢?
本地调试时,只配置了已给可用的zone,所以这里条件满足会直接调用 super.chooseServer(key) 父类的方法:
BaseLoadBalancer#chooseServer(...) 父类的选择Server的方法,其内部通过 IRule#choose(key) 会调用到具体的负载均衡器的实现:
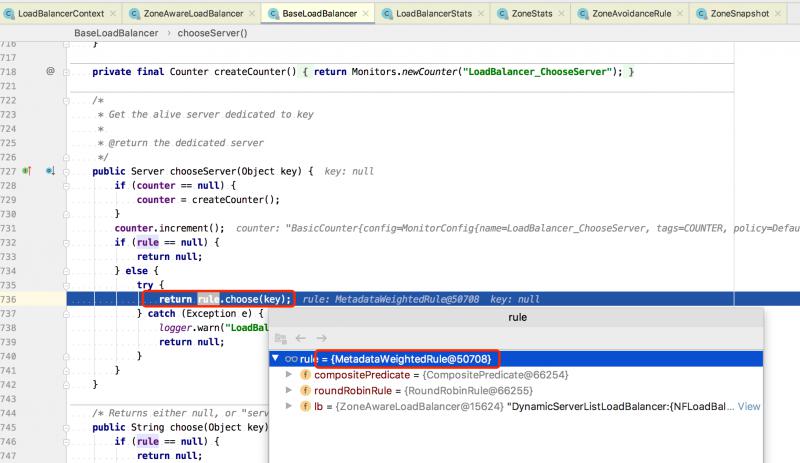
上述截图中,能看到 MetadataWeightedRule ,这个类是我们自行基于权重负载均衡实现。
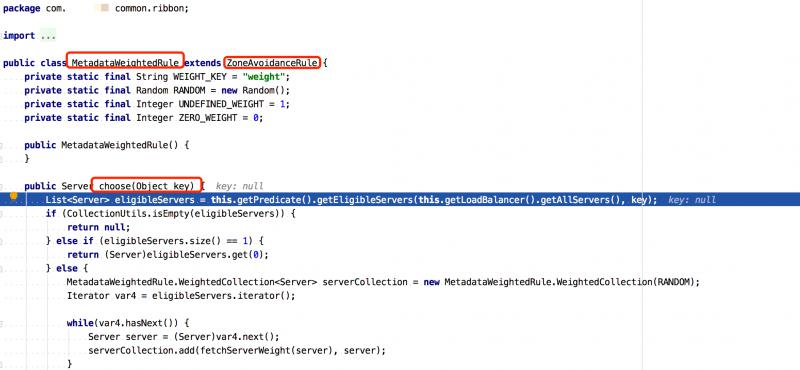
该实现类是继承了 ZoneAviodanceRule ,目的就是利用了 zone 的概念,所重写的 choose(Object key) 方法,调用了 this.getPredicate().getEligibleServers(...) 会走同样的过滤规则获取到同一机房(zone)下的所有服务列表,然后在基于每个服务配置的权重筛选一个Server。
获取到 Server 后,拼接接口的URI请求地址 http://IP:PORT/api/.../xxx.json ,通过底层的 OkHttp 实现完成 Http 接口的调用过程。
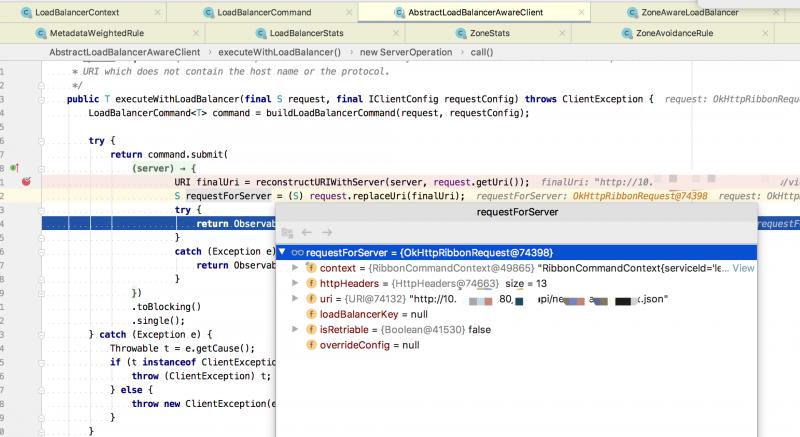
好了,到此基本就分析完了,从网关请求,通过 ribbon 组件从 eureka 注册中心拉取服务列表,如何基于 zone 分区来实现多数据中心的访问。
对于 服务注册,要保证服务能注册到同一个 zone 内的注册中心,如果跨 zone 注册,会导致网络延时较大,出现拉取注册表,心跳超时等问题。
对于 服务调用,要保证优先调用同一个 zone 内的服务,当无法找到同 zone 或者 同 zone 内的服务不可用时,才会转向调用其他 zone 里的服务。
本文提到的只是网关到微服务之间的调用,实际项目中,微服务还会调用其他第三方的服务,也要同时考虑到跨机房调用的问题,尽量都让各服务之间在同机房调用,减少网络延时,提高服务的稳定性。
欢迎关注我的公众号,扫二维码关注获得更多精彩原创文章,与你一同成长~


 浙公网安备 33010602011771号
浙公网安备 33010602011771号