万字长文!不为人所知的分布式锁实现全都在这里了
1、引入业务场景
2、分布式锁家族成员介绍
3、分布式锁成员实现原理剖析
4、最后的总结
2019 已经过去!
2020 已经到站!
1、引入业务场景
首先来由一个场景引入:
最近老板接了一个大单子,允许在某终端设备安装我们的APP,终端设备厂商日活起码得几十万到百万级别,这个APP也是近期产品根据市场竞品分析设计出来的,几个小码农通宵达旦开发出来的,主要功能是在线购物一站式服务,后台可以给各个商家分配权限,来维护需要售卖的商品信息。
老板大O:谈下来不容易,接下来就是考虑如何吸引终端设备上更多的用户注册上来,如何引导用户购买,这块就交给小P去负责了,需求尽快做,我明天出差!
产品小P:嘿嘿~,眼珠一转儿,很容易就想到了,心里想:“这还不简单,起码在首页搞个活动页... ”。
技术小T:很快了解了产品的需求,目前小J主要负责这块,找了前端和后端同学一起将活动页搞的快差不多了。
业务场景一出现:
因为小T刚接手项目,正在吭哧吭哧对熟悉着代码、部署架构。在看代码过程中发现,下单这块代码可能会出现问题,这可是分布式部署的,如果多个用户同时购买同一个商品,就可能导致商品出现 库存超卖 (数据不一致) 现象,对于这种情况代码中并没有做任何控制。
原来一问才知道,以前他们都是售卖的虚拟商品,没啥库存一说,所以当时没有考虑那么多...
这次不一样啊,这次是售卖的实体商品,那就有库存这么一说了,起码要保证不能超过库存设定的数量吧。
小T大眼对着屏幕,屏住呼吸,还好提前发现了这个问题,赶紧想办法修复,不赚钱还赔钱,老板不得疯了,还想不想干了~
业务场景二出现:
小T下面的一位兄弟正在压测,发现个小问题,因为在终端设备上跟鹅厂有紧密合作,调用他们的接口时需要获取到access_token,但是这个access_token过期时间是2小时,过期后需要重新获取。
压测时发现当到达过期时间时,日志看刷出来好几个不一样的access_token,因为这个服务也是分布式部署的,多个节点同时发起了第三方接口请求导致。
虽然以最后一次获取的access_token为准,也没什么不良副作用,但是会导致多次不必要的对第三方接口的调用,也会短时间内造成access_token的 重复无效获取(重复工作)。
业务场景三出现:
下单完成后,还要通知仓储物流,待用户支付完成,支付回调有可能会将多条订单消息发送到MQ,仓储服务会从MQ消费订单消息,此时就要 保证幂等性,对订单消息做 去重 处理。
以上便于大家理解为什么要用分布式锁才能解决,勾勒出的几个业务场景。
上面的问题无一例外,都是针对共享资源要求串行化处理,才能保证安全且合理的操作。
用一张图来体验一下:
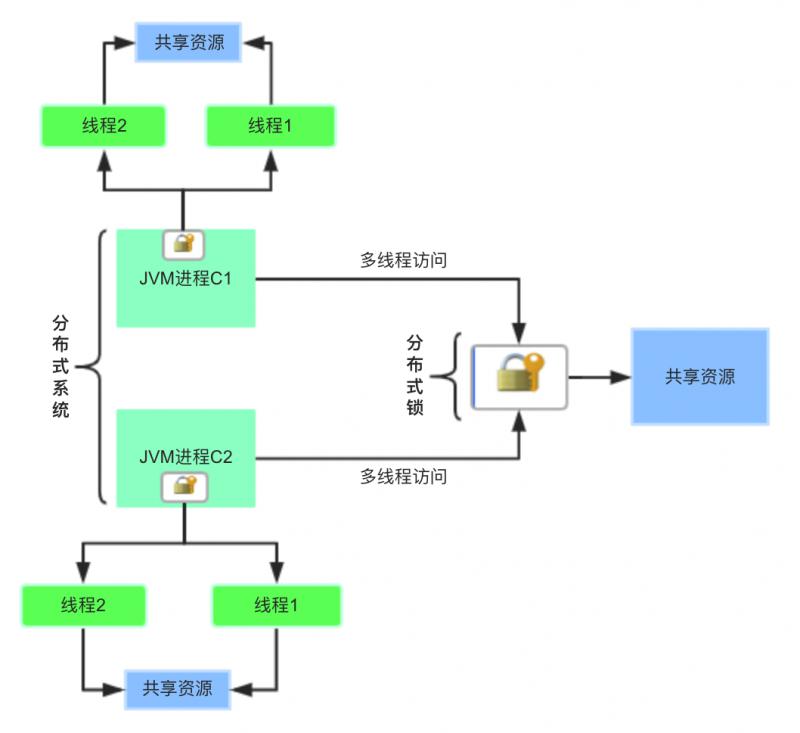
此时,使用Java提供的Synchronized、ReentrantLock、ReentrantReadWriteLock...,仅能在单个JVM进程内对多线程对共享资源保证线程安全,在分布式系统环境下统统都不好使,心情是不是拔凉呀。

这个问题得请教 分布式锁 家族来支持一下,听说他们家族内有很多成员,每个成员都有这个分布式锁功能,接下来就开始探索一下。
2、分布式锁家族成员介绍
为什么需要分布式锁才能解决?
听听 Martin 大佬们给出的说法:
Martin kleppmann 是英国剑桥大学的分布式系统的研究员,曾经跟 Redis 之父 Antirez 进行过关于 RedLock (Redis里分布式锁的实现算法)是否安全的激烈讨论。
他们讨论了啥,整急眼了?
都能单独写篇文章了请你自己看 Maritin 博客文章:
https://martin.kleppmann.com/2016/02/08/how-to-do-distributed-locking.html
效率:
使用分布式锁可以避免多个客户端重复相同的工作,这些工作会浪费资源。比如用户支付完成后,可能会收到多次短信或邮件提醒。
比如业务场景二,重复获取access_token。
对共享资源的操作是幂等性操作,无论你操作多少次都不会出现不同结果。
本质上就是为了避免对共享资源重复操作,从而提高效率。
正确性:
使用分布式锁同样可以避免锁失效的发生,一旦发生会引起正确性的破坏,可能会导致数据不一致,数据缺失或者其他严重的问题。
比如业务场景一,商品库存超卖问题。
对共享资源的操作是非幂等性操作,多个客户端操作共享资源会导致数据不一致。
分布式锁有哪些特点呢?
以下是分布式锁的一些特点,分布式锁家族成员并不一定都满足这个要求,实现机制不大一样。
互斥性: 分布式锁要保证在多个客户端之间的互斥。
可重入性:同一客户端的相同线程,允许重复多次加锁。
锁超时:和本地锁一样支持锁超时,防止死锁。
非阻塞: 能与 ReentrantLock 一样支持 trylock() 非阻塞方式获得锁。
支持公平锁和非公平锁:公平锁是指按照请求加锁的顺序获得锁,非公平锁真好相反请求加锁是无序的。
分布式锁家族实现者介绍
分布式锁家族实现者一览:
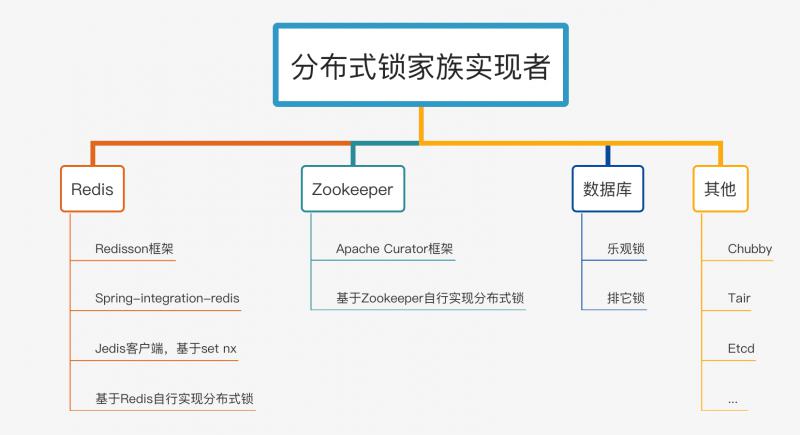
思维导图做了一个简单分类,不一定特别准确,几乎包含了分布式锁各个组件实现者。
下面让他们分别来做下自我介绍:
1、数据库
排它锁(悲观锁):基于 select * from table where xx=yy for update SQL语句来实现,有很多缺陷,一般不推荐使用,后文介绍。
乐观锁:表中添加一个时间戳或者版本号的字段来实现,update xx set version = new... where id = y and version = old 当更新不成功,客户端重试,重新读取最新的版本号或时间戳,再次尝试更新,类似 CAS 机制,推荐使用。
**2、Redis **
特点:CAP模型属于AP | 无一致性算法 | 性能好
开发常用,如果你的项目中正好使用了redis,不想引入额外的分布式锁组件,推荐使用。
业界也提供了多个现成好用的框架予以支持分布式锁,比如Redisson、spring-integration-redis、redis自带的setnx命令,推荐直接使用。
另外,可基于redis命令和redis lua支持的原子特性,自行实现分布式锁。
3、Zookeeper
特点:CAP模型属于CP | ZAB一致性算法实现 | 稳定性好
开发常用,如果你的项目中正好使用了zk集群,推荐使用。
业界有Apache Curator框架提供了现成的分布式锁功能,现成的,推荐直接使用。
另外,可基于Zookeeper自身的特性和原生Zookeeper API自行实现分布式锁。
4、其他
Chubby,Google开发的粗粒度分布锁的服务,但是并没有开源,开放出了论文和一些相关文档可以进一步了解,出门百度一下获取文档,不做过多讨论。
Tair,是阿里开源的一个分布式KV存储方案,没有用过,不做过多讨论。
Etcd,CAP模型中属于CP,Raft一致性算法实现,没有用过,不做过多讨论。
Hazelcast,是基于内存的数据网格开源项目,提供弹性可扩展的分布式内存计算,并且被公认是提高应用程序性能和扩展性最好的方案,听上去很牛逼,但是没用过,不做过多讨论。
当然了,上面推荐的常用分布式锁Zookeeper和Redis,使用时还需要根据具体的业务场景,做下权衡,实现功能上都能达到你要的效果,原理上有很大的不同。
画外音: 你对哪个熟悉,原理也都了解,hold住,你就用哪个。
3、分布式锁成员实现原理剖析
数据库悲观锁实现
以「悲观的心态」操作资源,无法获得锁成功,就一直阻塞着等待。
1、有一张资源锁表
CREATE TABLE `resource_lock` (
`id` int(4) NOT NULL AUTO_INCREMENT COMMENT '主键',
`resource_name` varchar(64) NOT NULL DEFAULT '' COMMENT '锁定的资源名',
`owner` varchar(64) NOT NULL DEFAULT '' COMMENT '锁拥有者',
`desc` varchar(1024) NOT NULL DEFAULT '备注信息',
`update_time` timestamp NOT NULL DEFAULT '' COMMENT '保存数据时间,自动生成',
PRIMARY KEY (`id`),
UNIQUE KEY `uidx_resource_name` (`resource_name `) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='锁定中的资源';
resource_name 锁资源名称必须有唯一索引。
2、使用姿势
必须添加事务,查询和更新操作保证原子性,在一个事务里完成。
伪代码实现:
@Transaction
public void lock(String name) {
ResourceLock rlock = exeSql("select * from resource_lock where resource_name = name for update");
if (rlock == null) {
exeSql("insert into resource_lock(reosurce_name,owner,count) values (name, 'ip',0)");
}
}
使用 for update 锁定的资源。
如果执行成功,会立即返回,执行插入数据库,后续再执行一些其他业务逻辑,直到事务提交,执行结束;
如果执行失败,就会一直阻塞着。
你也可以在数据库客户端工具上测试出来这个效果,当在一个终端执行了 for update,不提交事务。
在另外的终端上执行相同条件的 for update,会一直卡着,转圈圈...
虽然也能实现分布式锁的效果,但是会存在性能瓶颈。
3、悲观锁优缺点
优点:简单易用,好理解,保障数据强一致性。
缺点一大堆,罗列一下:
1)在 RR 事务级别,select 的 for update 操作是基于间隙锁(gap lock) 实现的,是一种悲观锁的实现方式,所以存在阻塞问题。
2)高并发情况下,大量请求进来,会导致大部分请求进行排队,影响数据库稳定性,也会耗费服务的CPU等资源。
当获得锁的客户端等待时间过长时,会提示:
[40001][1205] Lock wait timeout exceeded; try restarting transaction
高并发情况下,也会造成占用过多的应用线程,导致业务无法正常响应。
3)如果优先获得锁的线程因为某些原因,一直没有释放掉锁,可能会导致死锁的发生。
4)锁的长时间不释放,会一直占用数据库连接,可能会将数据库连接池撑爆,影响其他服务。
- MySql数据库会做查询优化,即便使用了索引,优化时发现全表扫效率更高,则可能会将行锁升级为表锁,此时可能就更悲剧了。
6)不支持可重入特性,并且超时等待时间是全局的,不能随便改动。
数据库乐观锁实现
乐观锁,以「乐观的心态」来操作共享资源,无法获得锁成功,没关系过一会重试一下看看呗,再不行就直接退出,尝试一定次数还是不行?也可以以后再说,不用一直阻塞等着。
1、有一张资源表
为表添加一个字段,版本号或者时间戳都可以。通过版本号或者时间戳,来保证多线程同时间操作共享资源的有序性和正确性。
CREATE TABLE `resource` (
`id` int(4) NOT NULL AUTO_INCREMENT COMMENT '主键',
`resource_name` varchar(64) NOT NULL DEFAULT '' COMMENT '资源名',
`share` varchar(64) NOT NULL DEFAULT '' COMMENT '状态',
`version` int(4) NOT NULL DEFAULT '' COMMENT '版本号',
`desc` varchar(1024) NOT NULL DEFAULT '备注信息',
`update_time` timestamp NOT NULL DEFAULT '' COMMENT '保存数据时间,自动生成',
PRIMARY KEY (`id`),
UNIQUE KEY `uidx_resource_name` (`resource_name `) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='资源';
2、使用姿势
伪代码实现:
Resrouce resource = exeSql("select * from resource where resource_name = xxx");
boolean succ = exeSql("update resource set version= 'newVersion' ... where resource_name = xxx and version = 'oldVersion'");
if (!succ) {
// 发起重试
}
实际代码中可以写个while循环不断重试,版本号不一致,更新失败,重新获取新的版本号,直到更新成功。
3、乐观锁优缺点
优点:简单易用,保障数据一致性。
缺点:
1)加行锁的性能上有一定的开销
2)高并发场景下,线程内的自旋操作 会耗费一定的CPU资源。
另外,比如在更新数据状态的一些场景下,不考虑幂等性的情况下,可以直接利用 行锁 来保证数据一致性,示例:update table set state = 1 where id = xxx and state = 0;
乐观锁就类似 CAS Compare And Swap 更新机制,推荐阅读 <<一文彻底搞懂CAS>>
基于Redis分布式锁实现
基于SetNX实现分布式锁
基于Redis实现的分布式锁,性能上是最好的,实现上也是最复杂的。
前文中提到的 RedLock 是 Redis 之父 Antirez 提出来的分布式锁的一种 「健壮」 的实现算法,但争议也较多,一般不推荐使用。
Redis 2.6.12 之前的版本中采用 setnx + expire 方式实现分布式锁,示例代码如下所示:
public static boolean lock(Jedis jedis, String lockKey, String requestId, int expireTime) {
Long result = jedis.setnx(lockKey, requestId);
//设置锁
if (result == 1) {
//获取锁成功
//若在这里程序突然崩溃,则无法设置过期时间,将发生死锁
//通过过期时间删除锁
jedis.expire(lockKey, expireTime);
return true;
}
return false;
}
如果 lockKey 存在,则返回失败,否则返回成功。设置成功之后,为了能在完成同步代码之后成功释放锁,方法中使用 expire() 方法给 lockKey 设置一个过期时间,确认 key 值删除,避免出现锁无法释放,导致下一个线程无法获取到锁,即死锁问题。
但是 setnx + expire 两个命令放在程序里执行,不是原子操作,容易出事。
如果程序设置锁之后,此时,在设置过期时间之前,程序崩溃了,如果 lockKey 没有设置上过期时间,将会出现死锁问题。
解决以上问题 ,有两个办法:
1)方式一:lua脚本
我们也可以通过 Lua 脚本来实现锁的设置和过期时间的原子性,再通过 jedis.eval() 方法运行该脚本:
// 加锁脚本,KEYS[1] 要加锁的key,ARGV[1]是UUID随机值,ARGV[2]是过期时间
private static final String SCRIPT_LOCK = "if redis.call('setnx', KEYS[1], ARGV[1]) == 1 then redis.call('pexpire', KEYS[1], ARGV[2]) return 1 else return 0 end";
// 解锁脚本,KEYS[1]要解锁的key,ARGV[1]是UUID随机值
private static final String SCRIPT_UNLOCK = "if redis.call('get', KEYS[1]) == ARGV[1] then return redis.call('del', KEYS[1]) else return 0 end";
2)方式二:set原生命令
在 Redis 2.6.12 版本后 SETNX 增加了过期时间参数:
SET lockKey anystring NX PX max-lock-time
程序实现代码如下:
public static boolean lock(Jedis jedis, String lockKey, String requestId, int expireTime) {
String result = jedis.set(lockKey, requestId, "NX", "PX", expireTime);
if ("OK".equals(result)) {
return true;
}
return false;
}
虽然 SETNX 方式能够保证设置锁和过期时间的原子性,但是如果我们设置的过期时间比较短,而执行业务时间比较长,就会存在锁代码块失效的问题,失效后其他客户端也能获取到同样的锁,执行同样的业务,此时可能就会出现一些问题。
我们需要将过期时间设置得足够长,来保证以上问题不会出现,但是设置多长时间合理,也需要依具体业务来权衡。如果其他客户端必须要阻塞拿到锁,需要设计循环超时等待机制等问题,感觉还挺麻烦的是吧。
Spring企业集成模式实现分布式锁
除了使用Jedis客户端之外,完全可以直接用Spring官方提供的企业集成模式框架,里面提供了很多分布式锁的方式,Spring提供了一个统一的分布式锁抽象,具体实现目前支持:
- Gemfire
- Jdbc
- Zookeeper
- Redis
早期,分布式锁的相关代码存在于Spring Cloud的子项目Spring Cloud Cluster中,后来被迁到Spring Integration中。
Spring Integration 项目地址 :https://github.com/spring-projects/spring-integration
Spring强大之处在于此,对Lock分布式锁做了全局抽象。
抽象结构如下所示:
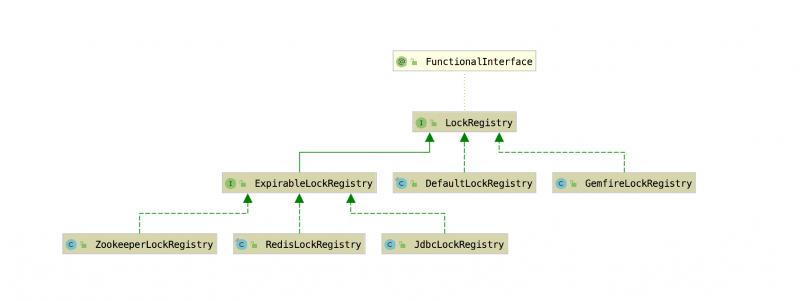
LockRegistry 作为顶层抽象接口:
/**
* Strategy for maintaining a registry of shared locks
*
* @author Oleg Zhurakousky
* @author Gary Russell
* @since 2.1.1
*/
@FunctionalInterface
public interface LockRegistry {
/**
* Obtains the lock associated with the parameter object.
* @param lockKey The object with which the lock is associated.
* @return The associated lock.
*/
Lock obtain(Object lockKey);
}
定义的 obtain() 方法获得具体的 Lock 实现类,分别在对应的 XxxLockRegitry 实现类来创建。
RedisLockRegistry 里obtain()方法实现类为 RedisLock,RedisLock内部,在Springboot2.x(Spring5)版本中是通过SET + PEXIPRE 命令结合lua脚本实现的,在Springboot1.x(Spring4)版本中,是通过SETNX命令实现的。
ZookeeperLockRegistry 里obtain()方法实现类为 ZkLock,ZkLock内部基于 Apache Curator 框架实现的。
JdbcLockRegistry 里obtain()方法实现类为 JdbcLock,JdbcLock内部基于一张INT_LOCK数据库锁表实现的,通过JdbcTemplate来操作。
客户端使用方法:
private final String registryKey = "sb2";
RedisLockRegistry lockRegistry = new RedisLockRegistry(getConnectionFactory(), this.registryKey);
Lock lock = lockRegistry.obtain("foo");
lock.lock();
try {
// doSth...
}
finally {
lock.unlock();
}
}
下面以目前最新版本的实现,说明加锁和解锁的具体过程。
RedisLockRegistry$RedisLock类lock()加锁流程:
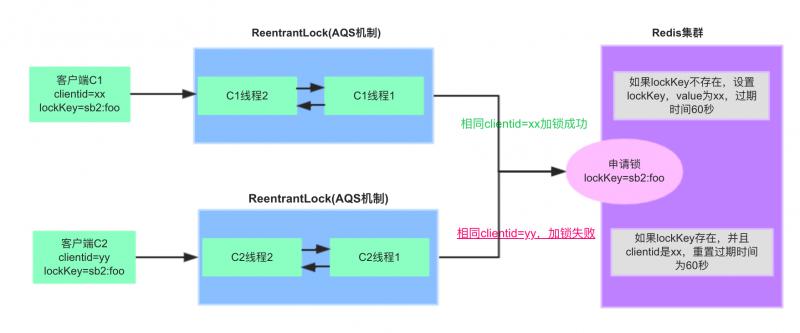
加锁步骤:
1)lockKey为registryKey:path,本例中为sb2:foo,客户端C1优先申请加锁。
2)执行lua脚本,get lockKey不存在,则set lockKey成功,值为clientid(UUID),过期时间默认60秒。
3)客户端C1同一个线程重复加锁,pexpire lockKey,重置过期时间为60秒。
4)客户端C2申请加锁,执行lua脚本,get lockKey已存在,并且跟已加锁的clientid不同,加锁失败
5)客户端C2挂起,每隔100ms再次尝试加锁。
RedisLock#lock()加锁源码实现:
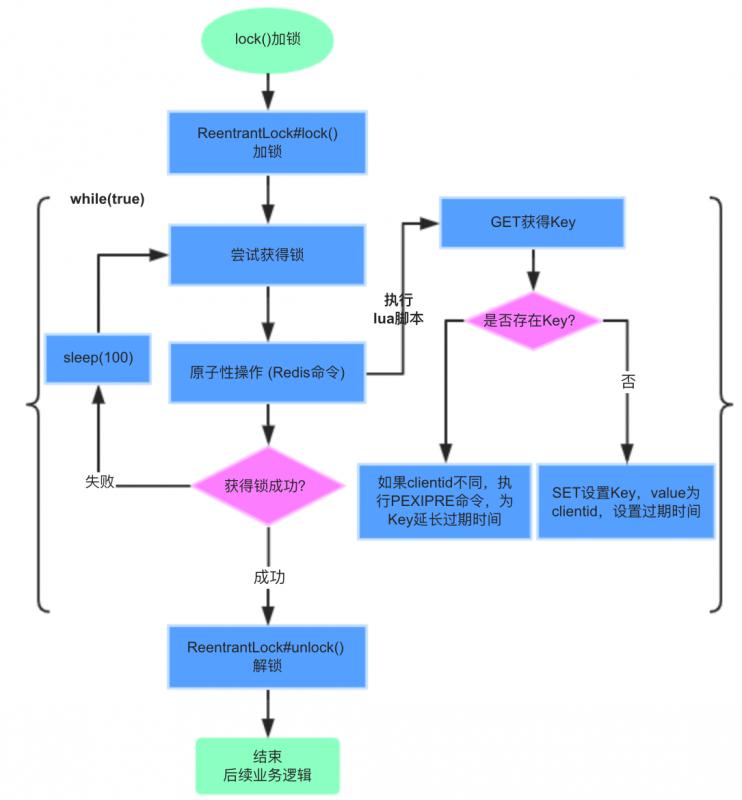
大家可以对照上面的流程图配合你理解。
@Override
public void lock() {
this.localLock.lock();
while (true) {
try {
while (!obtainLock()) {
Thread.sleep(100); //NOSONAR
}
break;
}
catch (InterruptedException e) {
/*
* This method must be uninterruptible so catch and ignore
* interrupts and only break out of the while loop when
* we get the lock.
*/
}
catch (Exception e) {
this.localLock.unlock();
rethrowAsLockException(e);
}
}
}
// 基于Spring封装的RedisTemplate来操作的
private boolean obtainLock() {
Boolean success =
RedisLockRegistry.this.redisTemplate.execute(RedisLockRegistry.this.obtainLockScript,
Collections.singletonList(this.lockKey), RedisLockRegistry.this.clientId,
String.valueOf(RedisLockRegistry.this.expireAfter));
boolean result = Boolean.TRUE.equals(success);
if (result) {
this.lockedAt = System.currentTimeMillis();
}
return result;
}
执行的lua脚本代码:
private static final String OBTAIN_LOCK_SCRIPT =
"local lockClientId = redis.call('GET', KEYS[1])\n" +
"if lockClientId == ARGV[1] then\n" +
" redis.call('PEXPIRE', KEYS[1], ARGV[2])\n" +
" return true\n" +
"elseif not lockClientId then\n" +
" redis.call('SET', KEYS[1], ARGV[1], 'PX', ARGV[2])\n" +
" return true\n" +
"end\n" +
"return false";
RedisLockRegistry$RedisLock类unlock()解锁流程:
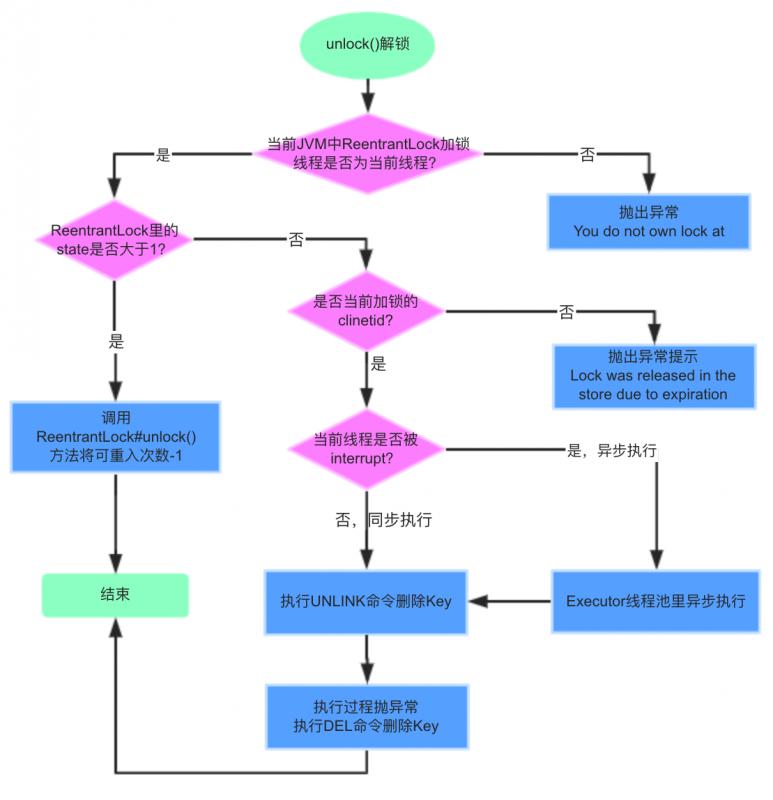
RedisLock#unlock()源码实现:
@Override
public void unlock() {
if (!this.localLock.isHeldByCurrentThread()) {
throw new IllegalStateException("You do not own lock at " + this.lockKey);
}
if (this.localLock.getHoldCount() > 1) {
this.localLock.unlock();
return;
}
try {
if (!isAcquiredInThisProcess()) {
throw new IllegalStateException("Lock was released in the store due to expiration. " +
"The integrity of data protected by this lock may have been compromised.");
}
if (Thread.currentThread().isInterrupted()) {
RedisLockRegistry.this.executor.execute(this::removeLockKey);
}
else {
removeLockKey();
}
if (LOGGER.isDebugEnabled()) {
LOGGER.debug("Released lock; " + this);
}
}
catch (Exception e) {
ReflectionUtils.rethrowRuntimeException(e);
}
finally {
this.localLock.unlock();
}
}
// 删除缓存Key
private void removeLockKey() {
if (this.unlinkAvailable) {
try {
RedisLockRegistry.this.redisTemplate.unlink(this.lockKey);
}
catch (Exception ex) {
LOGGER.warn("The UNLINK command has failed (not supported on the Redis server?); " +
"falling back to the regular DELETE command", ex);
this.unlinkAvailable = false;
RedisLockRegistry.this.redisTemplate.delete(this.lockKey);
}
}
else {
RedisLockRegistry.this.redisTemplate.delete(this.lockKey);
}
}
unlock()解锁方法里发现,并不是直接就调用Redis的DEL命令删除Key,这也是在Springboot2.x版本中做的一个优化,Redis4.0版本以上提供了UNLINK命令。
换句话说,最新版本分布式锁实现,要求是Redis4.0以上版本才能使用。
看下Redis官网给出的一段解释:
This command is very similar to DEL: it removes the specified keys.
Just like DEL a key is ignored if it does not exist. However the
command performs the actual memory reclaiming in a different thread,
so it is not blocking, while DEL is. This is where the command name
comes from: the command just unlinks the keys from the keyspace. The
actual removal will happen later asynchronously.
DEL始终在阻止模式下释放值部分。但如果该值太大,如对于大型LIST或HASH的分配太多,它会长时间阻止Redis,为了解决这个问题,Redis实现了UNLINK命令,即「非阻塞」删除。如果值很小,则DEL一般与UNLINK效率上差不多。
本质上,这种加锁方式还是使用的SETNX实现的,而且Spring只是做了一层薄薄的封装,支持可重入加锁,超时等待,可中断加锁。
但是有个问题,锁的过期时间不能灵活设置,客户端初始化时,创建RedisLockRegistry时允许设置,但是是全局的。
/**
* Constructs a lock registry with the supplied lock expiration.
* @param connectionFactory The connection factory.
* @param registryKey The key prefix for locks.
* @param expireAfter The expiration in milliseconds.
*/
public RedisLockRegistry(RedisConnectionFactory connectionFactory, String registryKey, long expireAfter) {
Assert.notNull(connectionFactory, "'connectionFactory' cannot be null");
Assert.notNull(registryKey, "'registryKey' cannot be null");
this.redisTemplate = new StringRedisTemplate(connectionFactory);
this.obtainLockScript = new DefaultRedisScript<>(OBTAIN_LOCK_SCRIPT, Boolean.class);
this.registryKey = registryKey;
this.expireAfter = expireAfter;
}
expireAfter参数是全局的,同样会存在问题,可能是锁过期时间到了,但是业务还没有处理完,这把锁又被另外的客户端获得,进而会导致一些其他问题。
经过对源码的分析,其实我们也可以借鉴RedisLockRegistry实现的基础上,自行封装实现分布式锁,比如:
1、允许支持按照不同的Key设置过期时间,而不是全局的?
2、当业务没有处理完成,当前客户端启动个定时任务探测,自动延长过期时间?
自己实现?嫌麻烦?别急别急!业界已经有现成的实现方案了,那就是 Redisson 框架!
站在Redis集群角度看问题
从Redis主从架构上来考虑,依然存在问题。因为 Redis 集群数据同步到各个节点时是异步的,如果在 Master 节点获取到锁后,在没有同步到其它节点时,Master 节点崩溃了,此时新的 Master 节点依然可以获取锁,所以多个应用服务可以同时获取到锁。
基于以上的考虑,Redis之父Antirez提出了一个RedLock算法。
RedLock算法实现过程分析:
假设Redis部署模式是Redis Cluster,总共有5个master节点,通过以下步骤获取一把锁:
1)获取当前时间戳,单位是毫秒
2)轮流尝试在每个master节点上创建锁,过期时间设置较短,一般就几十毫秒
3)尝试在大多数节点上建立一个锁,比如5个节点就要求是3个节点(n / 2 +1)
4)客户端计算建立好锁的时间,如果建立锁的时间小于超时时间,就算建立成功了
5)要是锁建立失败了,那么就依次删除这个锁
6)只要有客户端创建成功了分布式锁,其他客户端就得不断轮询去尝试获取锁
以上过程前文也提到了,进一步分析RedLock算法的实现依然可能存在问题,也是Martain和Antirez两位大佬争论的焦点。
问题1:节点崩溃重启
节点崩溃重启,会出现多个客户端持有锁。
假设一共有5个Redis节点:A、B、 C、 D、 E。设想发生了如下的事件序列:
1)客户端C1成功对Redis集群中A、B、C三个节点加锁成功(但D和E没有锁住)。
2)节点C Duang的一下,崩溃重启了,但客户端C1在节点C加锁未持久化完,丢了。
3)节点C重启后,客户端C2成功对Redis集群中C、D、 E尝试加锁成功了。
这样,悲剧了吧!客户端C1和C2同时获得了同一把分布式锁。
为了应对节点重启引发的锁失效问题,Antirez提出了延迟重启的概念,即一个节点崩溃后,先不立即重启它,而是等待一段时间再重启,等待的时间大于锁的有效时间。
采用这种方式,这个节点在重启前所参与的锁都会过期,它在重启后就不会对现有的锁造成影响。
这其实也是通过人为补偿措施,降低不一致发生的概率。
问题2:时钟跳跃
假设一共有5个Redis节点:A、B、 C、 D、 E。设想发生了如下的事件序列:
1)客户端C1成功对Redis集群中A、B、 C三个节点成功加锁。但因网络问题,与D和E通信失败。
2)节点C上的时钟发生了向前跳跃,导致它上面维护的锁快速过期。
3)客户端C2对Redis集群中节点C、 D、 E成功加了同一把锁。
此时,又悲剧了吧!客户端C1和C2同时都持有着同一把分布式锁。
为了应对时钟跳跃引发的锁失效问题,Antirez提出了应该禁止人为修改系统时间,使用一个不会进行「跳跃式」调整系统时钟的ntpd程序。这也是通过人为补偿措施,降低不一致发生的概率。
但是...,RedLock算法并没有解决,操作共享资源超时,导致锁失效的问题。
存在这么大争议的算法实现,还是不推荐使用的。
一般情况下,本文锁介绍的框架提供的分布式锁实现已经能满足大部分需求了。
小结:
上述,我们对spring-integration-redis实现原理进行了深入分析,还对RedLock存在争议的问题做了分析。
除此以外,我们还提到了spring-integration中集成了 Jdbc、Zookeeper、Gemfire实现的分布式锁,Gemfire和Jdbc大家感兴趣可以自行去看下。
为啥还要提供个Jdbc分布式锁实现?
猜测一下,当你的应用并发量也不高,比如是个后台业务,而且还没依赖Zookeeper、Redis等额外的组件,只依赖了数据库。
但你还想用分布式锁搞点事儿,那好办,直接用spring-integration-jdbc即可,内部也是基于数据库行锁来实现的,需要你提前建好锁表,创建表的SQL长这样:
CREATE TABLE INT_LOCK (
LOCK_KEY CHAR(36) NOT NULL,
REGION VARCHAR(100) NOT NULL,
CLIENT_ID CHAR(36),
CREATED_DATE DATETIME(6) NOT NULL,
constraint INT_LOCK_PK primary key (LOCK_KEY, REGION)
) ENGINE=InnoDB;
具体实现逻辑也非常简单,大家自己去看吧。
集成的Zookeeper实现的分布式锁,因为是基于Curator框架实现的,不在本节展开,后续会有分析。
基于Redisson实现分布式锁
Redisson 是 Redis 的 Java 实现的客户端,其 API 提供了比较全面的 Redis 命令的支持。
Jedis 简单使用阻塞的 I/O 和 Redis 交互,Redission 通过 Netty 支持非阻塞 I/O。
Redisson 封装了锁的实现,让我们像操作我们的本地 Lock 一样去使用,除此之外还有对集合、对象、常用缓存框架等做了友好的封装,易于使用。
截止目前,Github上 Star 数量为 11.8k,说明该开源项目值得关注和使用。
Redisson分布式锁Github:
https://github.com/redisson/redisson/wiki/8.-Distributed-locks-and-synchronizers
Redisson 可以便捷的支持多种Redis部署架构:
-
Redis 单机
-
Master-Slave + Sentinel 哨兵
-
Redis-Cluster集群
// Master-Slave配置
Config config = new Config();
MasterSlaveServersConfig serverConfig = config.useMasterSlaveServers()
.setMasterAddress("")
.addSlaveAddress("")
.setReadMode(ReadMode.SLAVE)
.setMasterConnectionPoolSize(maxActiveSize)
.setMasterConnectionMinimumIdleSize(maxIdleSize)
.setSlaveConnectionPoolSize(maxActiveSize)
.setSlaveConnectionMinimumIdleSize(maxIdleSize)
.setConnectTimeout(CONNECTION_TIMEOUT_MS) // 默认10秒
.setTimeout(socketTimeout)
;
RedissonClient redisson = Redisson.create(config);
RLock lock = redisson.getLock("myLock");
// 获得锁
lock.lock();
// 等待10秒未获得锁,自动释放
lock.lock(10, TimeUnit.SECONDS);
// 等待锁定时间不超过100秒
// 10秒后自动释放锁
boolean res = lock.tryLock(100, 10, TimeUnit.SECONDS);
if (res) {
try {
...
} finally {
lock.unlock();
}
}
使用上非常简单,RedissonClient客户端提供了众多的接口实现,支持可重入锁、、公平锁、读写锁、锁超时、RedLock等都提供了完整实现。
lock()加锁流程:
为了兼容老的版本,Redisson里都是通过lua脚本执行Redis命令的,同时保证了原子性操作。
加锁执行的lua脚本:
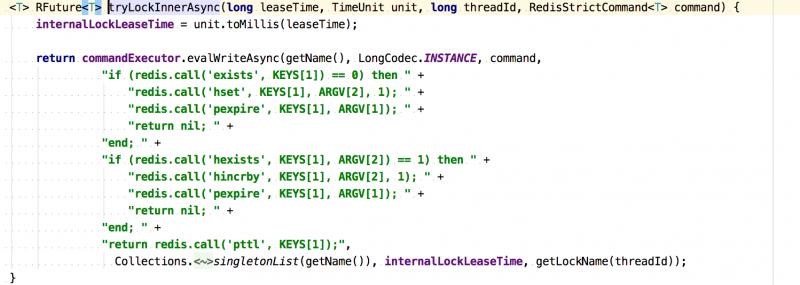
Redis里的Hash散列结构存储的。
参数解释:
KEY[1]:要加锁的Key名称,比如示例中的myLock。
ARGV[1]:针对加锁的Key设置的过期时间
ARGV[2]:Hash结构中Key名称,lockName为UUID:线程ID
protected String getLockName(long threadId) {
return id + ":" + threadId;
}
1)客户端C1申请加锁,key为myLock。
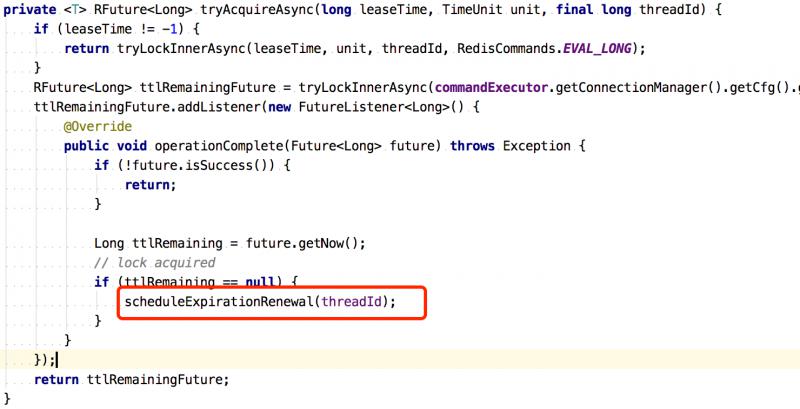
2)如果key不存在,通过hset设置值,通过pexpire设置过期时间。同时开启Watchdog任务,默认每隔10秒中判断一下,如果key还在,重置过期时间到30秒。
开启WatchDog源码:
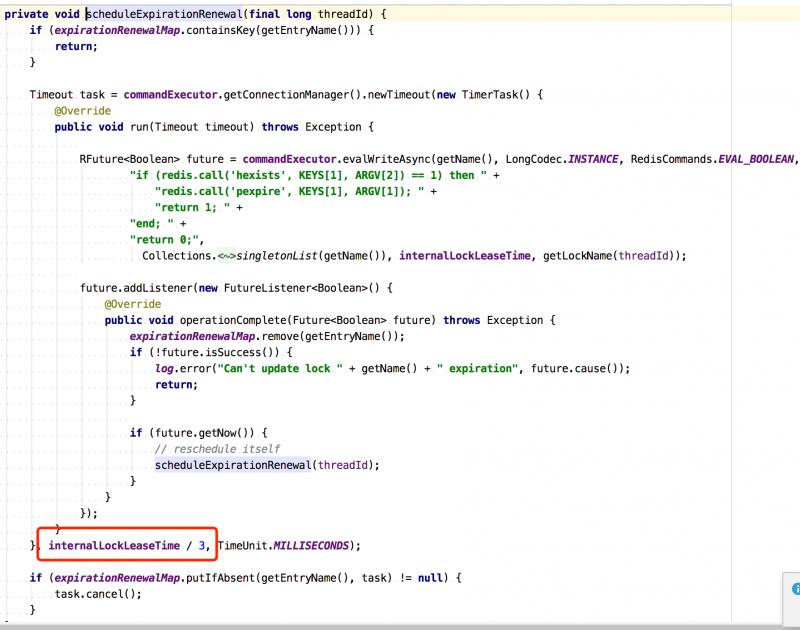
3)客户端C1相同线程再次加锁,如果key存在,判断Redis里Hash中的lockName跟当前线程lockName相同,则将Hash中的lockName的值加1,代表支持可重入加锁。
4)客户单C2申请加锁,如果key存在,判断Redis里Hash中的lockName跟当前线程lockName不同,则执行pttl返回剩余过期时间。
5)客户端C2线程内不断尝试pttl时间,此处是基于Semaphore信号量实现的,有许可立即返回,否则等到pttl时间还是没有得到许可,继续重试。
重试源码:
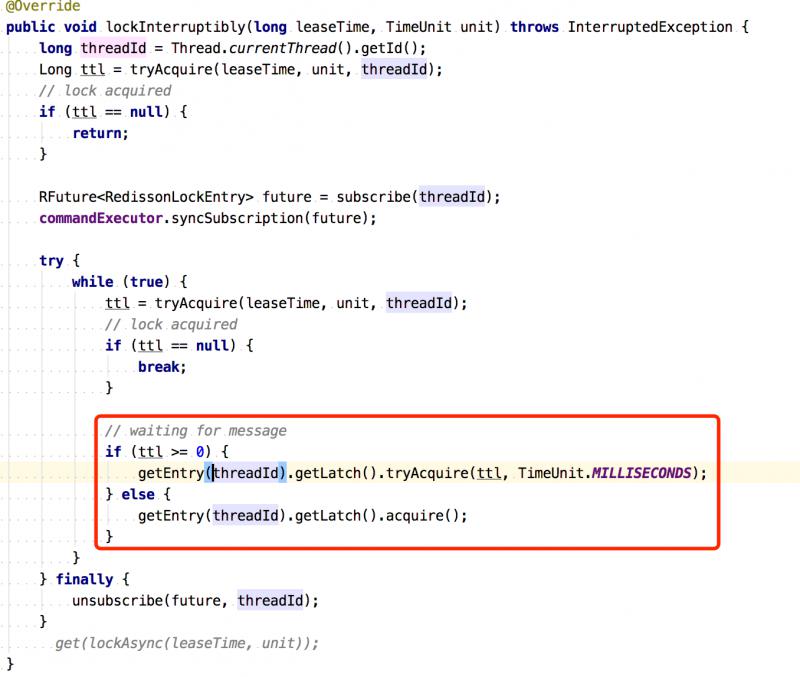
Redisson这样的实现就解决了,当业务处理时间比过期时间长的问题。
同时,Redisson 还自己扩展 Lock 接口,叫做 RLock 接口,扩展了很多的锁接口,比如给 Key 设定过期时间,非阻塞+超时时间等。
void lock(long leaseTime, TimeUnit unit);
boolean tryLock(long waitTime, long leaseTime, TimeUnit unit) throws InterruptedException;
redisson里的WatchDog(看门狗)逻辑保证了没有死锁发生。
如果客户端宕机了,WatchDog任务也就跟着停掉了。此时,不会对Key重置过期时间了,等挂掉的客户端持有的Key过期时间到了,锁自动释放,其他客户端尝试获得这把锁。
可以进一步看官网的关于WatchDog描述:
If Redisson instance which acquired lock crashes then such lock could hang forever in acquired state. To avoid this Redisson maintains lock watchdog, it prolongs lock expiration while lock holder Redisson instance is alive. By default lock watchdog timeout is 30 seconds and can be changed through Config.lockWatchdogTimeout setting.
unlock()解锁过程也是同样的,通过lua脚本执行一大坨指令的。
解锁lua脚本:
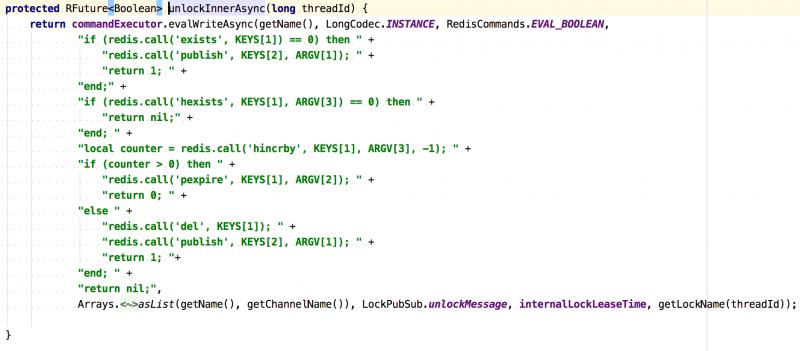
根据刚刚对加锁过程的分析,大家可以自行看下脚本分析下。
基于Zookeeper实现分布式锁
Zookeeper 是一种提供「分布式服务协调」的中心化服务,是以 Paxos 算法为基础实现的。Zookeeper数据节点和文件目录类似,同时具有Watch机制,基于这两个特性,得以实现分布式锁功能。
数据节点:
顺序临时节点:Zookeeper 提供一个多层级的节点命名空间(节点称为 Znode),每个节点都用一个以斜杠(/)分隔的路径来表示,而且每个节点都有父节点(根节点除外),非常类似于文件系统。
节点类型可以分为持久节点(PERSISTENT )、临时节点(EPHEMERAL),每个节点还能被标记为有序性(SEQUENTIAL),一旦节点被标记为有序性,那么整个节点就具有顺序自增的特点。
一般我们可以组合这几类节点来创建我们所需要的节点,例如,创建一个持久节点作为父节点,在父节点下面创建临时节点,并标记该临时节点为有序性。
Watch 机制:
Zookeeper 还提供了另外一个重要的特性,Watcher(事件监听器)。
ZooKeeper 允许用户在指定节点上注册一些 Watcher,并且在一些特定事件触发的时候,ZooKeeper 服务端会将事件通知给用户。
图解Zookeeper实现分布式锁:
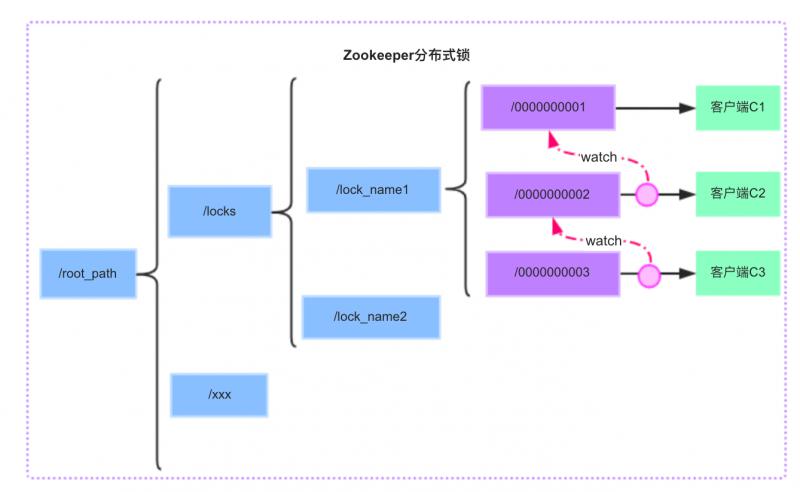
首先,我们需要建立一个父节点,节点类型为持久节点(PERSISTENT)如图中的 /locks/lock_name1 节点 ,每当需要访问共享资源时,就会在父节点下建立相应的顺序子节点,节点类型为临时节点(EPHEMERAL),且标记为有序性(SEQUENTIAL),并且以临时节点名称 + 父节点名称 + 顺序号组成特定的名字,如图中的 /0000000001 /0000000002 /0000000003 作为临时有序节点。
在建立子节点后,对父节点下面的所有以临时节点名称 name 开头的子节点进行排序,判断刚刚建立的子节点顺序号是否是最小的节点,如果是最小节点,则获得锁。
如果不是最小节点,则阻塞等待锁,并且获得该节点的上一顺序节点,为其注册监听事件,等待节点对应的操作获得锁。当调用完共享资源后,删除该节点,关闭 zk,进而可以触发监听事件,释放该锁。
// 加锁
InterProcessMutex lock = new InterProcessMutex(client, lockPath);
if ( lock.acquire(maxWait, waitUnit) )
{
try
{
// do some work inside of the critical section here
}
finally
{
lock.release();
}
}
public void acquire() throws Exception
{
if ( !internalLock(-1, null) )
{
throw new IOException("Lost connection while trying to acquire lock: " + basePath);
}
}
private boolean internalLock(long time, TimeUnit unit) throws Exception
{
/*
Note on concurrency: a given lockData instance
can be only acted on by a single thread so locking isn't necessary
*/
Thread currentThread = Thread.currentThread();
LockData lockData = threadData.get(currentThread);
if ( lockData != null )
{
// re-entering
lockData.lockCount.incrementAndGet();
return true;
}
String lockPath = internals.attemptLock(time, unit, getLockNodeBytes());
if ( lockPath != null )
{
LockData newLockData = new LockData(currentThread, lockPath);
threadData.put(currentThread, newLockData);
return true;
}
return false;
}
// ... 其他代码略
InterProcessMutex 是 Curator 实现的可重入锁,可重入锁源码过程分析:
加锁流程:
1)可重入锁记录在 ConcurrentMap<Thread, LockData> threadData 这个 Map 里面。
2)如果 threadData.get(currentThread) 是有值的那么就证明是可重入锁,然后记录就会加 1。
3)资源目录下创建一个节点:比如这里创建一个 /0000000002 这个节点,这个节点需要设置为 EPHEMERAL_SEQUENTIAL 也就是临时节点并且有序。
4)获取当前目录下所有子节点,判断自己的节点是否是最小的节点。
5)如果是最小的节点,则获取到锁。如果不是最小的节点,则证明前面已经有人获取到锁了,那么需要获取自己节点的前一个节点。
6)节点 /0000000002 的前一个节点是 /0000000001,我们获取到这个节点之后,再上面注册 Watcher,Watcher 调用的是 object.notifyAll(),用来解除阻塞。
7)object.wait(timeout) 或 object.wait() 进行阻塞等待
解锁流程:
1)如果可重入锁次数减1后,加锁次数不为 0 直接返回,减1后加锁次数为0,继续。
2)删除当前节点。
3)删除 threadDataMap 里面的可重入锁的数据。
最后的总结
上面介绍的诸如Apache Curator、Redisson、Spring框架集成的分布式锁,既然是框架实现,会考虑用户需求,尽量设计和实现通用的分布式锁接口。
基本都涵盖了如下的方式实现:
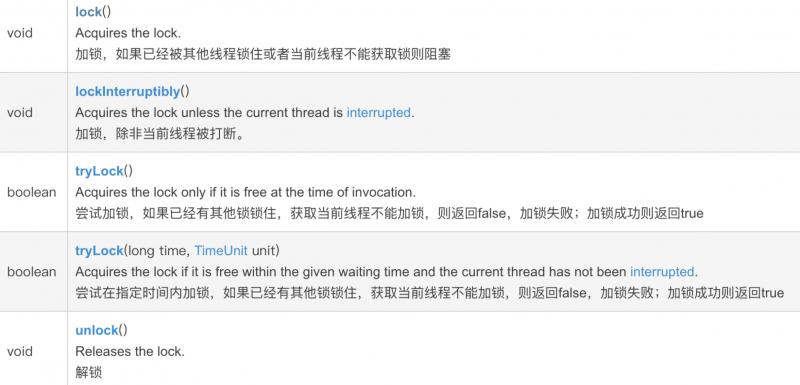
当然,Redisson和Curator都是自己定义的分布式锁接口实现的,易于扩展。
Curator里自定义了InterProcessLock接口,Redisson里自定义RLock接口,继承了 java.util.concurrent.locks.Lock接口。
对于Redis实现的分布式锁:
大部分需求下,不会遇到「极端复杂场景」,基于Redis实现分布式锁很常用,性能也高。
它获取锁的方式简单粗暴,获取不到锁直接不断尝试获取锁,比较消耗性能。
另外来说的话,redis的设计定位决定了它的数据并不是强一致性的,没有一致性算法,在某些极端情况下,可能会出现问题,锁的模型不够健壮。
即便有了Redlock算法的实现,但存在争议,某些复杂场景下,也无法保证其实现完全没有问题,并且也是比较消耗性能的。
对于Zookeeper实现的分布式锁:
Zookeeper优点:
天生设计定位是分布式协调,强一致性。锁的模型健壮、简单易用、适合做分布式锁。
如果获取不到锁,只需要添加一个监听器就可以了,不用一直轮询,性能消耗较小。
如果客户端宕机,也没关系,临时节点会自动删除,触发监听器通知下一个节点。
Zookeeper缺点:
若有大量的客户端频繁的申请加锁、释放锁,对于ZK集群的压力会比较大。
另外,本文对spring-integration集成redis做了详细分析,推荐可以直接使用,更推荐直接使用 Redisson,实现了非常多的分布式锁各种机制,有单独开放Springboot集成的jar包,使用上也是非常方便的。
文章开头部分提到的几个业务场景,经过对分布式锁家族的介绍和原理分析,可以自行选择技术方案了。
以上,一定有一款能满足你的需求,希望大家有所收获!
码字不易,文章不妥之处,欢迎留言斧正。
欢迎关注我的公众号,扫二维码关注获得更多精彩文章,与你一同成长~


 浙公网安备 33010602011771号
浙公网安备 33010602011771号