各大中间件底层技术-分布式一致性协议 Raft 详解
前言
正式介绍 Raft 协议之前,我们先来举个职场产研团队的一个例子🌰。
方式一:
在一个技术团队内假设角色都是 均等的,会导致什么情况呢?产品提出一个需求,就可以随便去找团队中的任意一个人去发起需求。如果这个人因为请假走了,但是他没有把需求及时同步给团队其他人,因此会导致该需求存在很大的延迟。
方式二:
在技术团队中选举一个 ** Leader角色**,产品提出的需求必须优先提给 Leader,找 Leader 先沟通。Leader 自己消化完后,在将需求传达给团队其他成员。如果 Leader 请假了,会指定某一个人充当 Leader 角色负责接收产品需求,并将需求同步给其他成员。
上述很简单的案例,可以对应理解分布式系统中的数据一致性算法。
分布式系统数据一致性算法一般都应用在中间件项目中,平时你写的业务代码,一般根本不会接触到的。
SpringCloud 家族中集成了大名鼎鼎的注册中心 Eureka 就使用的上面的 方式一 的思路来完成节点之间数据同步的,称为 **Peer To Peer ** 集群架构。
Eureka 当中的每个节点的地位都是均等的,每个节点都可以接收写入请求,每个节点接收请求之后,进行请求打包处理,异步化延迟一点时间,将数据同步给 Eureka 集群当中的其他节点。任何一台节点宕机之后,理论上应该是不影响集群运行的,都可以从其他节点获取注册表信息。
另外的一些开源项目,比如 Etcd、Consul,Zookeeper,还有未来会流行的国产技术阿里开源的 Nacos 项目,其中的 CP 模式也是基于 Raft 协议 来实现分布式一致性算法的。当然 Zookeeper 在 Raft 协议基础上做了一些改良,使用的 ZAB 分布式一致性协议来实现的。
在 Raft 协议出现之前,广泛使用的一致性算法是 Paxos。Paxos 算法解决的是如何保障单一客户端操作的一致性,完成每个操作都需要至少两轮的消息交换。和 Paxos 算法不同,Raft 里有 Leader 的概念,Raft 在处理任何客户端操作之前必须要选举出来一个 leader 角色,选举一个 Leader 经过至少一轮的消息交换,但是选举了 Leader 之后,处理每个客户端的操作只需要一轮消息交换。
详解 Raft 协议
接下来,围绕如下几点展开:
1)Leader选举流程
2)节点心跳检测
3)选主超时操作
4)日志复制流程
5)日志条目结构
6)Leader崩溃恢复操作
1)Leader选举流程
如果系统中只有唯一一个节点,读写操作都由这一个节点来负责,不会存在数据不一致的问题。
但是,对于分布式系统会存在至少两个节点,需要有一个角色来充唯一的节点,我们把这个唯一节点叫做 Leader 节点,其他节点叫做 Follower 节点, leader 选举过程中才会有的状态叫做 Candidate 节点。
为了便于理解和说明,假设集群中有三个节点:节点A、节点B、节点C。
集群启动后,初始节点状态都是 Follower 状态。最开始各个节点启动之后,此时集群内还没有 Leader。
如果每次各节点都投票给自己,Leader 会始终无法选出来,这样僵持下去肯定是不行的。所以出现了 electionTimeout 的概念,称为 选举超时时间 每个节点都会有 electionTimeout。
一旦发现一轮投票没有结果,集群中各节点自身设置一个 electionTimeout,时间范围在 150ms ~ 300ms 之间的一个随机值。
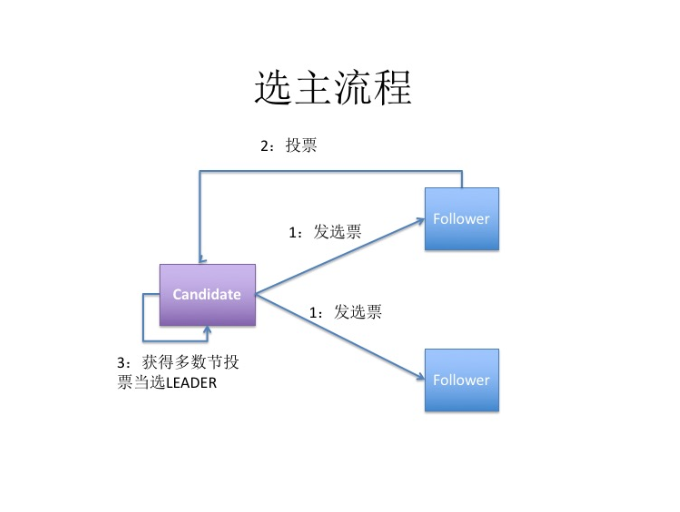
当节点 A 的 electionTimeout 时间到了,会将节点 A 状态变为 Candidate 状态,节点 A 苏醒过来,很Happy,终于可以参与竞选了,立马给自己投了一票 。然后向集群中其他两个节点发起选举投票(Http协议或者RPC协议请求都可以)。
节点B、C可以认为处于 Follower 状态,如何进行选举投票呢?
这里就出现了 term 的概念,每个节点都会有个 term,term 表示任期,跟美国总统竞选里的任期类似。term 是一个全局且连续递增的整数,每完成一次选举,term会递增 +1。
Follower 状态的节点此时收到 Candidate 选举请求,发现集群中就只有一个 Candidate 状态的节点 A,所以直接投票给 Candidate 节点。
这里就出现了 voteFor 的概念,每个节点都会有voteFor,voteFor 表示投票的数据。
节点 A 收到投票反馈之后,引出了另外的判断条件:必须是集群中过半节点都投票给自己,也包括自己。
算式:n / 2 + 1
举个🌰:
集群中有三个节点,3 / 2 + 1 = 2 必须有 2 个节点投票成功。
集群中有五个节点,5 / 2 + 1 = 3 必须有 3 个节点投票成功。
最终 Candidate 状态的节点 A 很荣幸晋升为 Leader。
2)节点心跳检测
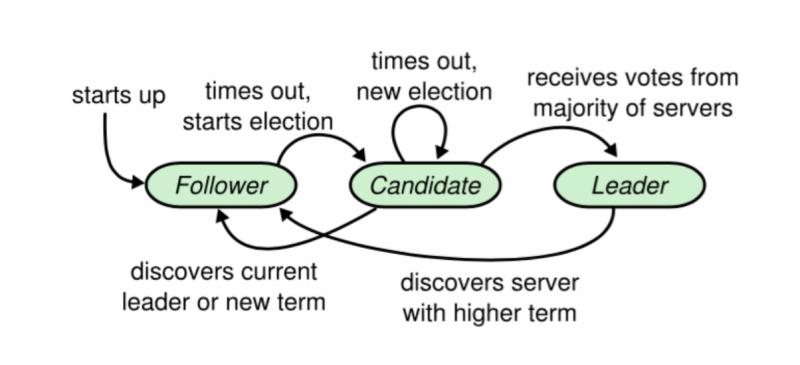
我们看到上述的状态流转图,当重新选举 Leader 时,各节点自身的状态会在 Candidate、Follower、Leader 之间不断的变换。
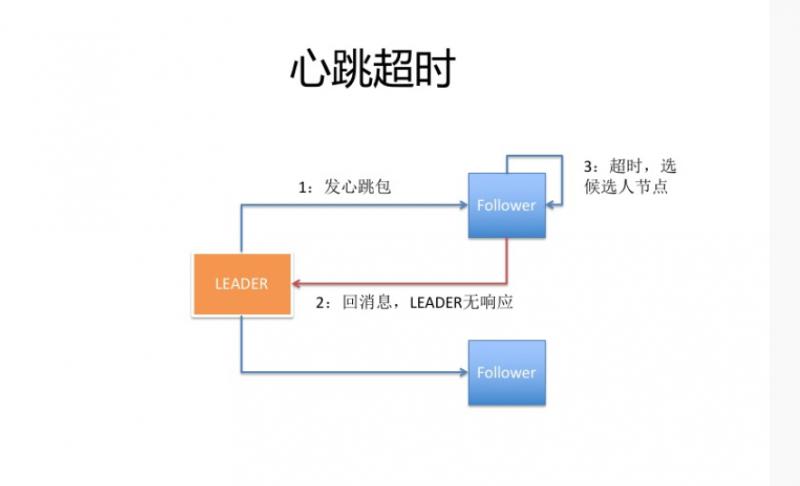
所以,被选举的节点 A 成为了 Leader ,为了保持它的『统治』地位,要不断的向其他节点发送心跳,告诉他们「我还活着,我还活着... 」。
其他节点 B、C 收到心跳请求后,会返回响应,发现原来 Leader 还在,不需要发起选举,同时要重置选举超时时间 electionTimeout。
如果作为 Leader 的节点 A 因为意外,比如网络问题无法正常发送心跳给其他节点。
此时,节点 B 的 electionTimeout 超时时间到了,变成了 Candidate 状态,term + 1,voteFor 投票给自己,并发送投票请求给节点 A、C。
之前还是 Leader 的节点 A 收到了节点 B 发来的投票请求,发现 term 任期不是最大的了,更新自身的 term 值为节点 B 的 term,从 Leader 状态切换为 Follower 状态,并重置 electionTimeout。
3)选主超时操作
如果恰巧有两个节点同时都发起了投票,但都没有获得多数节点的选票,此时就得打加时赛了,直到获得多数选票的节点成为 Leader。
如下图所示:
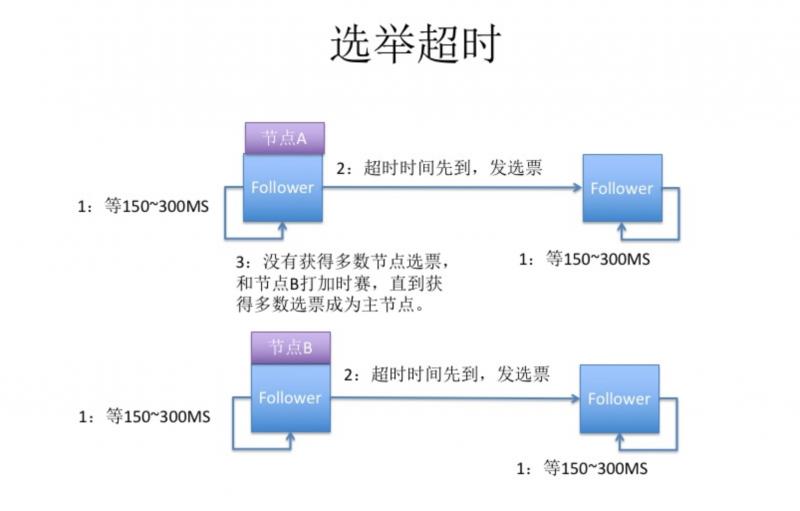
假设集群中有4个节点,A、B、C、D。出现了两个节点处于 Candidate 状态。
第一轮选举状态如下:
节点A[Candidate] <----- 节点 C 选举节点A
节点B[Candidate] <----- 节点 D 选举节点B
第一轮选举之后,节点 A 和节点 B 还是处于 Candidate 状态,都不满足集群过半数投票成功的条件,选举 Leader 失败。
下一轮就要看 Candidate 状态的节点谁的 electionTimeout 先到,谁就先发起新一轮选举操作。只要发起选举,term 任期就要递增的。
如果节点 B 的 electionTimeout 先到,先发起选举操作,那么集群中按照条件必须是有 3 个节点投票成功之后最终成为 Leader。
为了避免出现上述这种平局的情况,所以一般集群中节点部署个数都是奇数: ** 2n + 1**
4)日志复制流程
当 Leader 选出来之后,Client 客户端发起的写请求都会由 Leader 节点来处理。
即使其他的 Follower 节点收到了 Client 客户端的请求,也会将请求转交给 Leader 来处理。
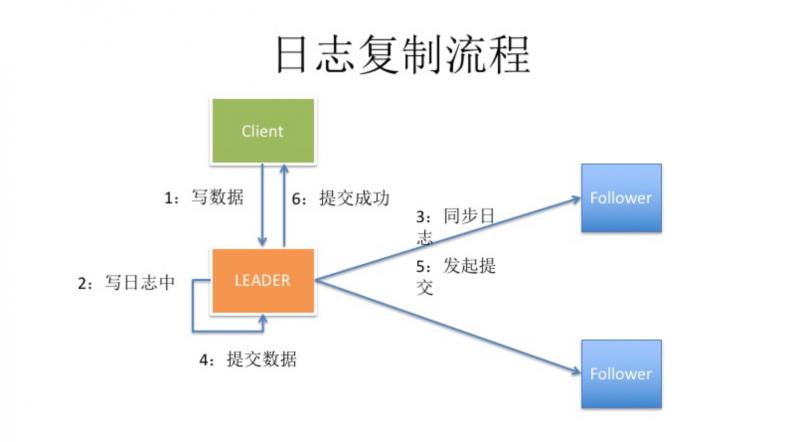
Leader 接收到 Client 的请求之后,会优先将数据写入到自身节点的 log 日志文件中。
被写入到日志文件里的日志条目,被称为 **append entries **。
Leader 将发送 append entries 消息给其他节点,这里并不是每次都将相同的日志条目,都发送给其他节点,而是根据节点的不同对应的消息也是不同的。因为集群中节点之间数据可能会有不一致的情况。
其他 Follower 节点收到 Leader 的消息后,将数据添加到本地,然后返回给 Leader 响应,确认消息已收到。
Leader 节点收到其他节点确认消息且过半数,先 Commit 提交记录,返回 Client 客户端响应。
然后,Leader 节点再次向其他 Follower 节点发送 Commit 提交数据通知。
其他 Follower 节点收到通知后,Commit 提交自身的日志条目数据,返回 Leader 更新结束的通知。
日志条目提交保证两点:
容错:
在数量少于 Raft 服务器节点总数一半的 Follower 失败的情况下 ,Raft 集群仍然可以正常处理来自客户端的请求。
确保重叠:
一旦 Leader 响应了一个客户端的请求,即使出现了 Raft 集群中少数服务器的失败,也会有一个服务器包含所有以前提交的日志条目。
5)日志条目结构
每个节点都会有两个索引,日志条目最终提交完成,提交的索引值称为 ** commitIndex,另外一个是目前最后一行索引值,称为 lastApplied**
Leader 节点除了存储上面提到的 commitIndex 和 lastApplied之外,还需要存储其他 Follower 节点的数据情况。
一个是 nextIndex 记录的是 Leader 里有,Follower 节点没有的数据索引,即需要发送 append entries 的数据索引。
另外一个是 **matchIndex **,记录的是 Leader 节点已知,已经复制给他 Follower 节点日志的最高索引值。
当数据变更时, Leader 向其他节点发送不同的 append entries 消息数据。
如果重新选举了 Leader,新的 Leader 并不知道原来 Leader 的 nextIndex 和 matchIndex 两个数据,会将自身节点的 nextIndex 重置为 commitIndex,matchIndex 则全部重置为 0。
6)选主后日志同步
当集群中的 Leader 接收到 Client 请求,发现部分节点因为网络问题无法正常通讯,所以日志不能复制给多数节点,日志无法正常提交。
如下图所示:
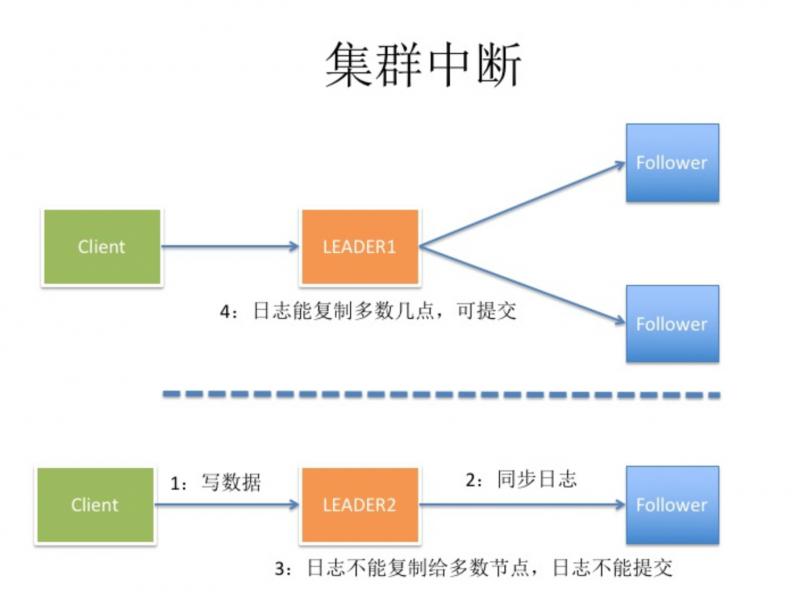
其他 Follower 节点无法正常收到 Leader 心跳检测请求,会发生重新选主操作。
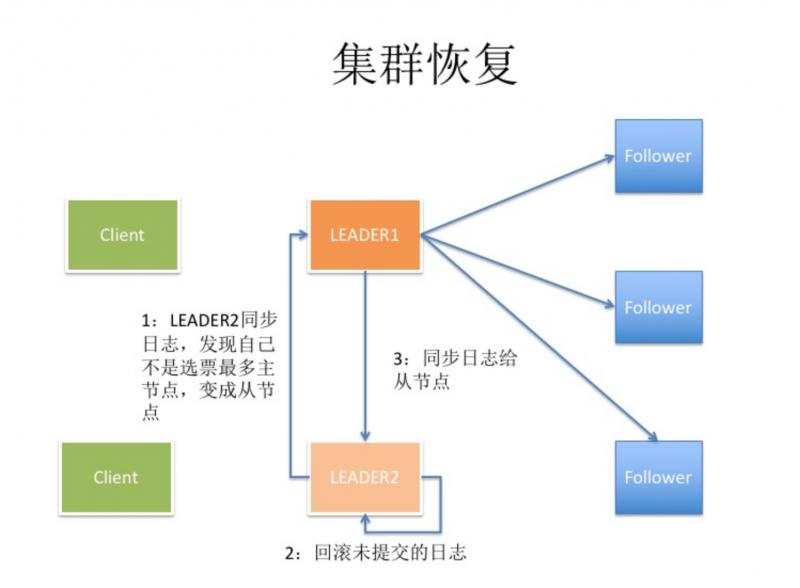
当新的 Leader1 产生,原来的 Leader2 集群恢复之后,发现自己不是选票最多的节点,即 term 不是最大的,节点状态切换到 Follower,回滚未提交的日志。
新的 Leader1 重新将同步日志重新同步给其他 Follower 节点。
如下图所示 :
总结
经过对 Raft 协议的详细分析,我们能够总结到,其实 Raft 协议就是 2PC (两阶段提交) + 集群过半节点写机制 结合实现的。
1、每个节点都有 electionTimeout 选举超时时间,用于当 Follower 节点无法收到心跳时,到期发起选举 Leader 的操作。
2、Leader 节点选举时,最终选出来的 Leader 的 term 任期一定是最大的。
3、Leader 节点给其他 Follower 节点发送 append enties 日志条目时,针对不同的节点发送不同的日志消息。
4、Leader 接收客户端的写入请求,此时处于 uncommitted 状态,Leader 将 uncommitted 消息发送给其他 Follower 节点,作为第一阶段。
5、其他 Follower 节点收到 uncommitted 请求之后,返回确认 ack 响应给 Leader,如果 Leader 收到了过半数 Follower 节点的 ack 响应,则将请求标记为 committed,同时发送 committed 请求发送给其他 Follower 节点,让其他节点对消息进行 committed。作为第二阶段 + 过半数机制。
另外刚刚文中提到阿里开源的 Nacos 注册中心,其内部自己实现了一套简化版的 Raft 协议。看了 Nacos 官方的 Roadmap 能够了解到,规划在 nacos 1.7.0 GA 中会替换掉现在的 Raft 协议实现,有可能会采用蚂蚁金服开源的SOFA-JRaft,SOFA-JRaft 基于 Raft 一致性算法的生产级高性能 Java 实现,支持 MULTI-RAFT-GROUP,适用于高负载低延迟的场景。
参考:
http://ifeve.com/raft/
http://thesecretlivesofdata.com/raft/
欢迎关注我的公众号,扫二维码关注,文章首发到公众号,与你一同成长~


 浙公网安备 33010602011771号
浙公网安备 33010602011771号