【Java集合学习】HashMap源码之“拉链法”散列冲突的解决
【Java集合学习】HashMap源码之“拉链法”散列冲突的解决
1.HashMap的概念
HashMap 是一个散列表,它存储的内容是键值对(key-value)映射。
HashMap 继承于AbstractMap,实现了Map、Cloneable、java.io.Serializable接口。
HashMap 的实现不是同步的,这意味着它是线程不安全的。它的key、value都可以为null。此外,HashMap中的映射是无序的。
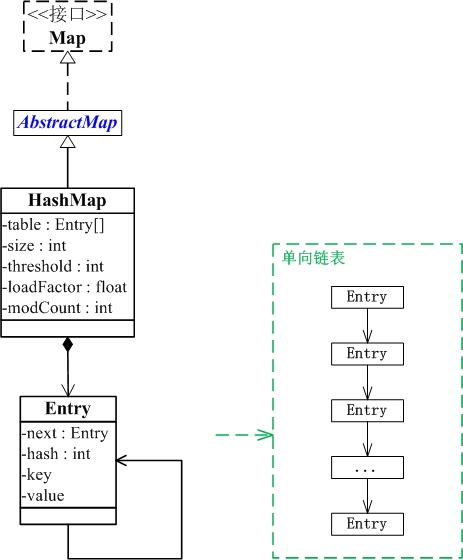
本文重点是介绍HashMap中的“拉链法”解决散列冲突。如果想了解其他方面的知识可参考http://www.cnblogs.com/skywang12345/p/3310835.html。
下面先介绍一下散列表及散列冲突的基本概念。
2.Hash表的概念
我们知道,有一种数据结构能够快速地查找所需的对象(O(1)时间复杂度),这就是散列表(hash table)。散列码(hash code)是由对象的实例产生的一个整数。
更准确的说,具有不同的数据域的对象将产生不同的散列码。如下图(这里顺带提一下散列表的概念,即哈希表的概念):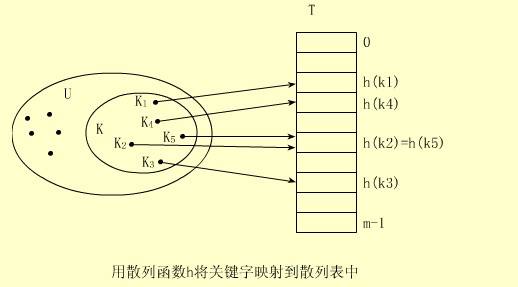
设所有可能出现的关键字集合记为U(简称全集)。实际发生(即实际存储)的关键字集合记为K(|K|比|U|小得多)。
散列方法是使用函数h将U映射到表T[0..m-1]的下标上(m=O(|U|))。这样以U中关键字为自变量,以h为函数的运算结果就是相应结点的存储地址。从而达到在O(1)时间内就可完成查找。
其中:
① h:U→{0,1,2,…,m-1} ,通常称h为散列函数(Hash Function)。散列函数h的作用是压缩待处理的下标范围,使待处理的|U|个值减少到m个值,从而降低空间开销。
② T为散列表(Hash Table)。
③ h(Ki)(Ki∈U)是关键字为Ki结点存储地址(亦称散列值或散列地址)。
④ 将结点按其关键字的散列地址存储到散列表中的过程称为散列(Hashing)
3.散列冲突
两个不同的关键字,由于散列函数值相同,因而被映射到同一表位置上。该现象称为冲突(Collision)或碰撞。发生冲突的两个关键字称为该散列函数的同义词(Synonym)。
上图中的k2≠k5,但h(k2)=h(k5),故k2和K5所在的结点的存储地址相同。
有了冲突,那自然要尽可能地去同时还需要确定解决冲突的方法,使发生冲突的同义词能够存储到表中。
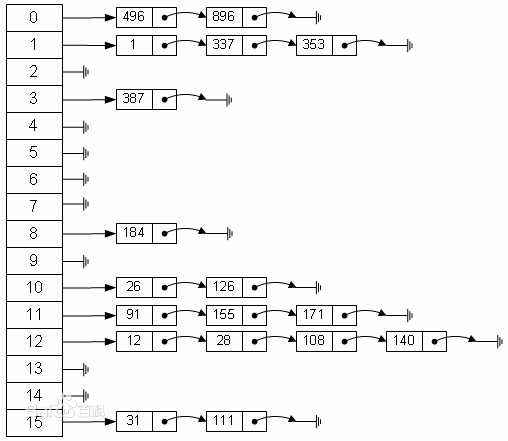
HashMap中采用的“拉链法”就是一种冲突解决的方式(hash函数的设计才是冲突避免,但不是一种完全的冲突解决方法),如下图所示为“拉链法”结构。
但是HashMap中的节点是Map.Entry类型的,而不是简单的value,如下图所示,左边是一个Node<K,V>[] table数组(在jdk6中是Entry<K,V>数组),Node是Map.Entry的实现类。
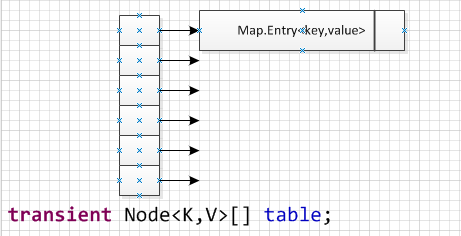
那么它是如何解决冲突的呢?即key值不同的两个或多个Map.Entry<K,V>可能会插在同一个桶下面,但是当查找到某个特定的hash值的时候,下面挂了很多个<K,V>映射,怎么确定哪个是我要找的那个<K,V>呢?这就是HashMap底层结构的一个亮点,在它的Entry中不仅仅只是插入value的,他是插入整个Entry 的,里面包含key和value的,所以能识别同一个hash值下的不同Map.Entry,想要了解更多,建议查看源码。
作者: 一点点征服
出处:http://www.cnblogs.com/ldq2016/
本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接,否则保留追究法律责任的权利

 浙公网安备 33010602011771号
浙公网安备 33010602011771号