四月面试总结
面试总结
标签(空格分隔): 面试
今天面试不会内容:
- IO模型
- 读取操作文件
- 线程进程协程
- mysql的索引触发器存储过程
- TCP/IP协议
- 把字符串转化成数字
IO模型
- 阻塞IO
- 非阻塞IO
- IO多路复用
- 信号驱动
- 异步IO
--IO多路复用
文件读取操作
读取一个大文件比如500M,计算出每一个字的频率,分别把前十频率的求出来。
def str_count(filename):
f = open(filename,'r',encoding='utf-8')
dic = {}
while True:
line = f.readline()
if line:
for s in line:
if s in dic:
dic[s]+=1
else:
dic[s]=1
else:
break
result = sorted(dic.items(), key=lambda k: k[1], reverse=True)
print(dic)
print(result)
str_count(r'C:\Users\Administrator\Desktop\text.txt')
英文单词的频率
'''英文单词出现的频率'''
def word_count(filename):
f = open(filename,'r')
dic = {}
while True:
line = f.readline()
if line:
line = line.replace(',','')
line = line.replace('.','')
line = line.replace('!','')
line = line.replace(';','')
line = line.replace('-','')
str_list = line.split()
for s in str_list:
if s.lower() in dic:
dic[s.lower()]+=1
else:
dic[s.lower()] = 1
else:
break
result = sorted(dic.items(), key=lambda k: k[1], reverse=True)
print(result)
word_count(r'C:\Users\Administrator\Desktop\abc'
r'.txt')
IBM面试总结
- 什么是定长变量?sizeof是什么意思?
- Setuptools包的作用是什么,和它类似功能的包是什么?
- 深拷贝与浅拷贝的原理
- 是否了解pyobject,说说你的理解?
下面代码的输出
列表做参数
def f(x,l=[]):
for i in range(x):
l.append(i*i)
print(l)
if __name__ == '__main__':
f(3)
f(2,[3,2,1])
f(4)
f(2)
f(2,[1,1])
'''输出结果
[0, 1, 4]
[3, 2, 1, 0, 1]
[0, 1, 4, 0, 1, 4, 9]
[0, 1, 4, 0, 1, 4, 9, 0, 1]
[1, 1, 0, 1]'''
指定文件夹下的所有文件和文件夹
import os
def traverse(f):
fs = os.listdir(f)
for f1 in fs:
tmp_path = os.path.join(f, f1)
if not os.path.isdir(tmp_path):
print('文件: %s' % tmp_path)
else:
print('文件夹:%s' % tmp_path)
traverse(tmp_path)
path = r'C:\Users\Administrator\Desktop'
traverse(path)
给定一个升序列表和一个数字n在列表中查找两个数,使它们的和为n,并满足时间复杂度为O(n).
def two_num(sort_list,n):
i = 0
j = -1
start = sort_list[i]
end = sort_list[j]
while start < end:
start = sort_list[i]
end = sort_list[j]
result = start+end
if result < n:
i+=1
elif result > n:
j-=1
else:
return (start,end)
w = two_num([1,3,4,5,6,9,11],4)
print(w)
有一个3G大小的文件,文件每行一个string,内容为酒店的id和一个图片的名字,使用“\t”分割
示例:ht_1023134 + "\t" + hidfadsfadsfdfadsf2r234523,jpg
表示的是一个酒店包含的一张图片,统计含有图片数量为[20,无穷大]的酒店id,含有图片数量为[10,20]的酒店id、含有图片数量为[10,5]的酒店id,含有图片数量为[0,5]的酒店id,并将结果输出到文件中
0-5 + “\t” + id1 + “\t” + id2 + .....
5-10 + “\t” + id1 + “\t” + id2 + .....
10-20 + “\t” + id1 + “\t” + id2 + .....
20-无穷大 + “\t” + id1 + “\t” + id2 + .....
from collections import Counter
count_dict = {}
cou = Counter()
with open('a.txt', encoding='utf-8') as f:
for line in f:
hotel, image = line.split()
hotel_id = hotel.split('_')[1]
cou.update({hotel_id,1})
if hotel_id in count_dict:
count_dict[hotel_id] += 1
else:
count_dict[hotel_id] = 1
del cou[1]
zero_five = ['0-5']
five_ten = ['5-10']
ten_twenty = ['10-20']
twenty_infinite = ['10-去穷大']
for hotel_id,count in count_dict.items():
if count < 5 :
zero_five.append(hotel_id)
elif count < 10 :
five_ten.append(hotel_id)
elif count < 20:
ten_twenty.append(hotel_id)
else:
twenty_infinite.append(hotel_id)
with open('b.txt','w',encoding='utf-8') as b:
b.write('\t'.join(zero_five))
b.write('\n')
b.write('\t'.join(five_ten))
b.write('\n')
b.write('\t'.join(ten_twenty))
b.write('\n')
b.write('\t'.join(twenty_infinite))
找到一个目录下,所有以'我'开头的。文件名包含今天的日期文件(yyyy--mm--dd)。文件编码均为utf-8。
不用内置方法求最大值
def max_num(li):
max_n = False
for i in range(len(li)-1):
if li[i]>li[i+1]:
max_n = li[i]
else:
max_n = li[i+1]
return max_n
n = max_num([1,5,4,7,2])
print(n)
字符串的编辑距离
def minDistance(word1, word2):
"""
:type word1: str
:type word2: str
:rtype: int
"""
M = len(word1)
N = len(word2)
output = [[0] * (N + 1) for i in range(M + 1)]
for i in range(M + 1):
for j in range(N + 1):
if i == 0 and j == 0:
output[i][j] = 0
elif i == 0 and j != 0:
output[i][j] = j
elif i != 0 and j == 0:
output[i][j] = i
elif word1[i - 1] == word2[j - 1]:
output[i][j] = min(output[i - 1][j - 1], output[i - 1][j] + 1, output[i][j - 1] + 1)
else:
output[i][j] = min(output[i - 1][j - 1] + 1, output[i - 1][j] + 1, output[i][j - 1] + 1)
return output[M][N]
if __name__ == "__main__":
l = minDistance('asd', 'asdf')
print(l)
二叉树遍历获取某值的所有对象集合
# Definition for a binary tree node.
class TreeNode(object):
def __init__(self, x):
self.val = x
self.left = None
self.right = None
class Solution(object):
note_obj_list = []
def note_list(self, root):
"""
:type root: TreeNode
:type sum: int
:rtype: int
"""
if not root:
return None
else:
if root.val == 'root':
self.note_obj_list.append(root)
self.note_list(root.left)
self.note_list(root.right)
root = TreeNode('root')
root.left = TreeNode('root')
s = Solution()
s.note_list(root)
print(s.note_obj_list)
ASCII码、utf-8与unicode之间的关系
因为计算机只能处理数字,如果处理文本必须把文本转化成数字才行。最早的计算机设计时采用8个比特位(bit)作为一个字节(byte)
由于计算技术美国人发明的,因此最早只有127个字母被编码到计算机中,也就是大小写的英文字母、数字、符号,这个编码表被称之为ASCII码表:
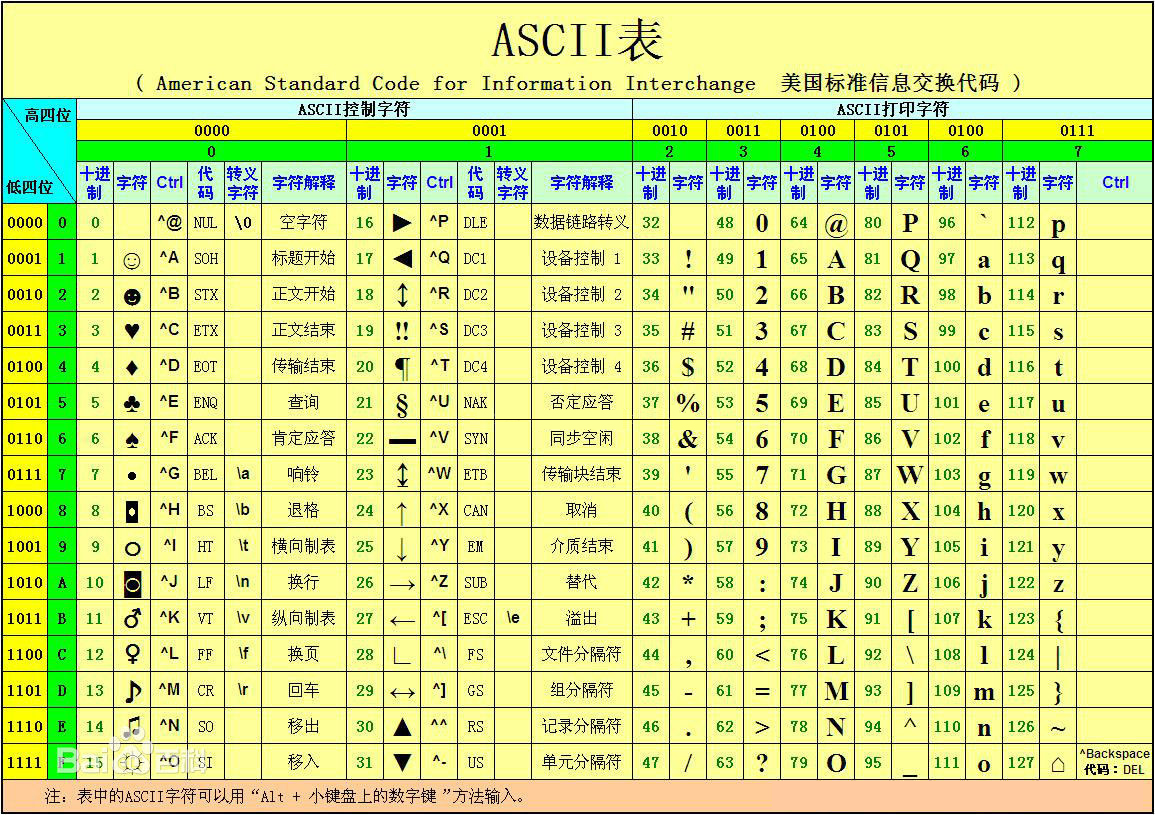
但要处理中文显然是不够的,至少需要2个字节(byte),而且不能和ASCII码冲突,所以中国制定了GB2312
但是全世界有成百上千种语言,各国之间都有各自的标准,不可避免的会造成冲突,结果是相互转码的都是乱码
Unicode应运而生,Unicode把所有语言都统一到一套编码里,这样就不会有乱码的问题了。
Unicode通常用两个字节表示一个字符(生僻字符,就需要4个字节)
现代大多数操作系统和编程语言都直接支持Unicode。
新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全部是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以又出现了把Unicode编码转化为可变长编码的utf-8编码。UTF-8编码把一个Unicode字符根据不同的字符大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间:
| 字符 | ASCII | Unicode | UTF-8 |
|---|---|---|---|
| A | 01000001 | 00000000 01000001 | 01000001 |
| 中 | x | 01001110 00101101 | 11100100 10111000 10101101 |
从上面的表格还可以发现,UTF-8编码有一个额外的好处,就是ASCII编码实际上可以被看成是UTF-8编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。
搞清楚了ASCII、Unicode、和utf-8的关系,我们就可以总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中统一使用使用Unicode编码,当需要保存到硬盘或者传输时,就转换成UTF-8编码。
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件。
将字符转化成数字
#ASCII码转换为相应字符
chr(97)
#字符转换为响应ASCII码
ord('a')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号