
图片检索原理以及改进尝试
2. Image Retrieval
主要提出了一种从粗糙到细致的检索方案(coarse-to-fine)。H层首先被二值化:
粗糙检索是用H层的二分哈希码,相似性用hamming距离衡量。待检索图像设为I,将I和所有的图像的对应H层编码进行比对后,选择出hamming距离小于一个阈值的m个构成一个池,其中包含了这m个比较相似的图像。

细致检索则用到的是fc7层的特征,相似性用欧氏距离衡量。距离越小,则越相似。从粗糙检索得到的m个图像池中选出最相似的前k个图像作为最后的检索结果。每两张图128维的H层哈希码距离计算速度是0.113ms,4096维的fc7层特征的距离计算需要109.767ms,因此可见二值化哈希码检索的速度优势。
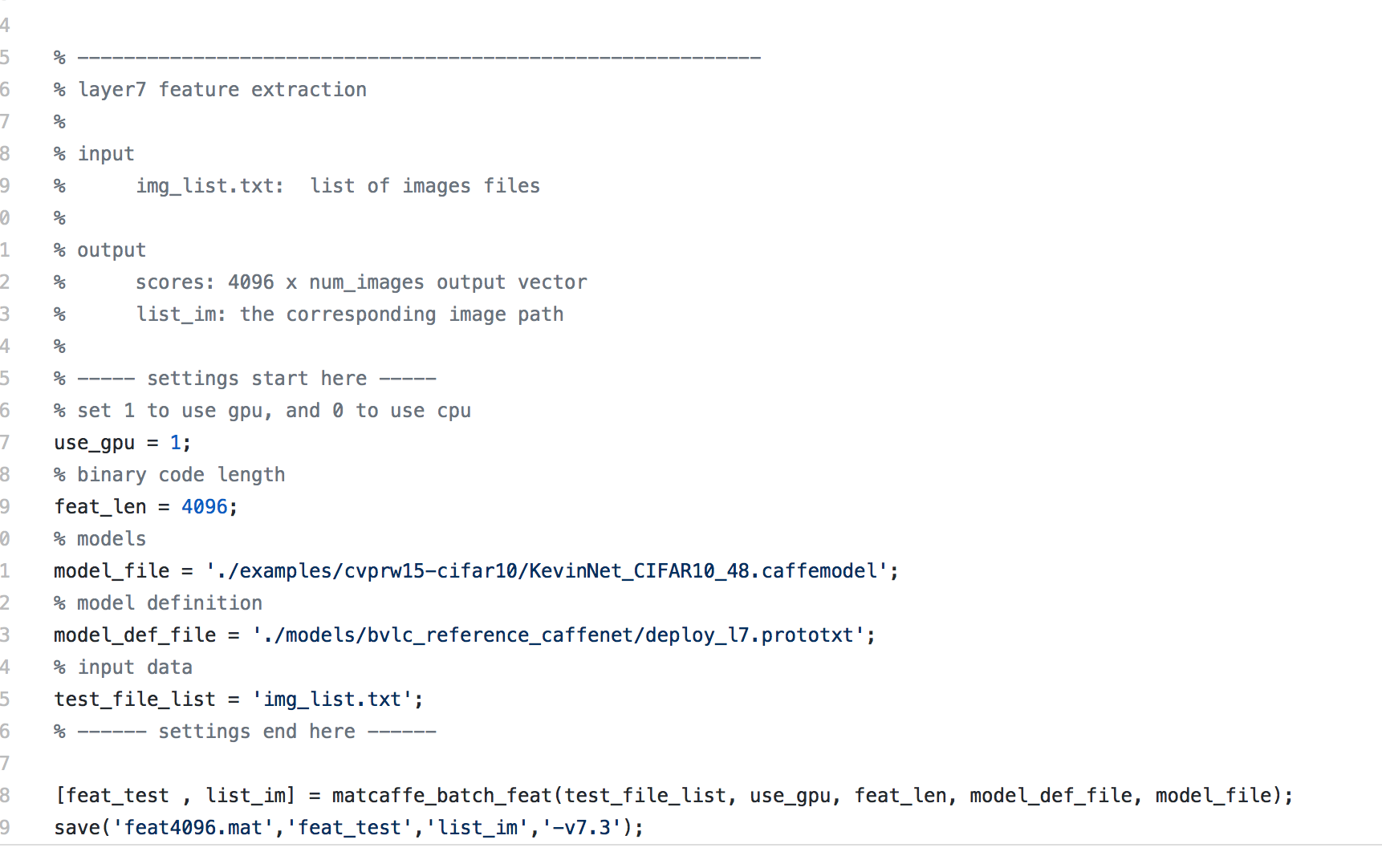
首先说图像特征的表达能力,这一直是基于内容的图像检索最核心却又困难的点之一,计算机所『看到』的图片像素层面表达的低层次信息与人所理解的图像多维度高层次信息内容之间有很大的差距,因此我们需要一个尽可能丰富地表达图像层次信息的特征。我们前面的博客也提到了,deep learning是一个对于图像这种层次信息非常丰富的数据,有更好表达能力的框架,其中每一层的中间数据都能表达图像某些维度的信息,相对于传统的Hist,Sift和Gist,表达的信息可能会丰富一下,因此这里我们用deep learning产出的特征来替代传统图像特征,希望能对图像有更精准的描绘程度。
基于内容的图像检索系统最大的难点在上节已经说过了,其一为大部分神经网络产出的中间层特征维度非常高,比如Krizhevsky等的在2012的ImageNet比赛中用到的AlexNet神经网,第7层的输出包含丰富的图像信息,但是维度高达4096维。4096维的浮点数向量与4096维的浮点数向量之间求相似度,运算量较大,因此Babenko等人在论文Neural codes for image retrieval中提出用PCA对4096维的特征进行PCA降维压缩,然后用于基于内容的图像检索,此场景中效果优于大部分传统图像特征。同时因为高维度的特征之间相似度运算会消耗一定的时间,因此线性地逐个比对数据库中特征向量是显然不可取的。大部分的ANN技术都是将高维特征向量压缩到低维度空间,并且以01二值的方式表达,因为在低维空间中计算两个二值向量的汉明距离速度非常快,因此可以在一定程度上缓解时效问题。ANN的这部分hash映射是在拿到特征之外做的,本系统框架试图让卷积神经网在训练过程中学习出对应的『二值检索向量』,或者我们可以理解成对全部图先做了一个分桶操作,每次检索的时候只取本桶和临近桶的图片作比对,而不是在全域做比对,以提高检索速度。
再说『近似最近邻』,ANN(Approximate Nearest Neighbor)/近似最近邻一直是一个很热的研究领域。因为在海量样本的情况下,遍历所有样本,计算距离,精确地找出最接近的Top K个样本是一个非常耗时的过程,尤其有时候样本向量的维度也相当高,因此有时候我们会牺牲掉一小部分精度,来完成在很短的时间内找到近似的top K个最近邻,也就是ANN,最常见的ANN算法包括局部敏感度哈希/locality-sensitive hashing,最优节点优先/best bin first和Balanced box-decomposition tree等,我们系统中将采用LSH/局部敏感度哈希来完成这个过程。有一些非常专业的ANN库,比如FLANN,有兴趣的同学可以了解一下。
检索过程简单说来就是对图片数据库的每张图片抽取特征(一般形式为特征向量),存储于数据库中,对于待检索图片,抽取同样的特征向量,然后并对该向量和数据库中向量的距离,找出最接近的一些特征向量,其对应的图片即为检索结果
论文是这样实现『二值检索向量』的:在Krizhevsky等2012年用于ImageNet中的卷积神经网络结构基础上,在第7层(4096个神经元)和output层之间多加了一个隐层(全连接层)。隐层的神经元激励函数,可以选用sigmoid,这样输出值在0-1之间值,可以设定阈值(比如说0.5)之后,将这一层输出变换为01二值向量作为『二值检索向量』,这样在使用卷积神经网做图像分类训练的过程中,会『学到』和结果类别最接近的01二值串,也可以理解成,我们把第7层4096维的输出特征向量,通过神经元关联压缩成一个低维度的01向量,但不同于其他的降维和二值操作,这是在一个神经网络里完成的,每对图片做一次完整的前向运算拿到类别,就产出了表征图像丰富信息的第7层output(4096维)和代表图片分桶的第8层output(神经元个数自己指定,一般都不会很多,因此维度不会很高)。引用论文中的图例解释就是如下的结构:
3.使用模型对新的图像进行分类
在对一个新的图片进行分类之前,我们还需要一个deploy.prototxt文件,这个文件和之前模型层次文件类似,只不过首尾不太一样,没有第一层数据输入层,也没有最后的Accuracy层,但最后需要添加一个Softmax层,用于计算分类概率。
这里我们将caffenet的solver.prototxt复制过来使用即可,如果之后自己的设计model的train_val时,记得要将solver.prototxt与其保持一致。
cd ~/caffe/
sudo cp models/bvlc_reference_caffenet/deploy.prototxt examples/myfile/- 1
- 2
接着,还需要一个类别映射文件,我们可以将类别数字代码转换成对应的类别名称,例如之前3-汽车,4-恐龙,5-大象,6-花,7-马。主要注意的是这个文件往往是根据索引来的,最好的时类别数字代码从0开始,即可对应,但如果没有从0开始,像博主一样,就需要添加一个来凑齐索引对应,我的映射文件命名为labels.txt,内容如下:
接着,还需要一个类别映射文件,我们可以将类别数字代码转换成对应的类别名称,例如之前3-汽车,4-恐龙,5-大象,6-花,7-马。主
要注意的是这个文件往往是根据索引来的,最好的时类别数字代码从0开始,即可对应,但如果没有从0开始,像博主一样,就需要添加一个来凑齐索引对应,我的映射文件命名为labels.txt,内容如下
sys.path.insert
注:sys.path模块是动态的修改系统路径
模块要处于Python搜索路径中的目录里才能被导入,但我们不喜欢维护一个永久性的大目录,因为其他所有的Python脚本和应用程序导入模块的时候性能都会被拖累。本节代码动态地在该路径中添加了一个"目录",当然前提是此目录存在而且此前不在sys.path中。
sys.path是个列表,所以在末尾添加目录是很容易的,用sys.path.append就行了。当这个append执行完之后,新目录即时起效,以后的每次import操作都可能会检查这个目录。如同解决方案所示,可以选择用sys.path.insert(0,…,这样新添加的目录会优先于其他目录被import检查。
即使sys.path中存在重复,或者一个不存在的目录被不小心添加进来,也没什么大不了,Python的import语句非常聪明,它会自己应付这类问题。但是,如果每次import时都发生这种错误(比如,重复的不成功搜索,操作系统提示的需要进一步处理的错误),我们会被迫付出一点小小的性能代价。为了避免这种无谓的开销,本节代码在向sys.path添加内容时非常谨慎,绝不加入不存在的目录或者重复的目录。程序向sys.path添加的目录只会在此程序的生命周期之内有效,其他所有的对sys.path的动态操作也是如此

 浙公网安备 33010602011771号
浙公网安备 33010602011771号