统计学习方法之决策树
声明:原创内容,如需转载请注明出处
今天主要了解什么是决策树和如何计算信息增益
决策树是一个基于分类问题的方法。根据不同的特征做出决策进行分类。
下面举个例子,为母亲要给女儿找对象的例子。
女儿:多大年纪了?
母亲:26。
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员不?
母亲:是,在税务局上班呢。
女儿:那好,我去见见。
在这里的特征有“年纪”,“长相”,“收入”,“公务员”。做出的决策(分类)就是“见面”,“不见面”
下面画一下这颗树:

也就是说,决策树的简单策略就是,好比公司招聘面试过程中筛选一个人的简历,如果你的条件相当好比如说某985/211重点大学博士毕业,那么二话不说,直接叫过来面试,不用有接下来的判断了,如果非重点大学毕业,但实际项目经验丰富,那么也要考虑叫过来面试一下,即所谓具体情况具体分析、决策。
在这里红色的结点就是叶结点代表分类的结果。绿色的就是内结点代表特征或者说是属性。
在这个树里我们首先是根据年龄(根节点)来进行划分的,如果年龄>30那么直接就不见。就不用有接下来的判断了。
当然,在这里的我们是根据母女对话的先后顺序来进行构造这颗树的。
很多时候,只是给定了一些特征,并不知道哪一个是对输出的结果影响最大的,哪一个具有很好的分类能力,在此就需要进行特征选择。
下面再说一个例子:

在这里有一些已知数据,15个申请者的具体贷款请款情况,特征有“年龄”“工作”'房子"“贷款信用”,分类输出的结果”同意贷款“”拒绝贷款“
在这里,我们要学习一个决策树,不仅仅进行对已知数据进行很好的分类,而且要对将来新到的申请者给出一个很好的输出结果,即是否允许贷款。
那么问题来了,要选什么样的特征作为树的根节点比较好呢?哪一个特征对分类的影响强呢?
我们要进行特征选择:特征选择可以提高决策树的分类效率,如果选取的特征对输出没有很大的影响,那么这个特征是没有分类能力的,扔掉这样的特征,选取分类能力强的特征。
那么我们如何知道哪个特征的分类能力强呢?引入:信息增益,和信息增益比
我们用信息增益大来表示特征能力强(表示使得分类结果更明确)。
看这个图,蓝色区域代表X的信息熵,红色代表Y的信息熵,交叉部分就是互信息。代表知道了X后Y的不确定减少了多少。

什么是信息增益呢?
信息增益等价于互信息。如果没有任何特征,那么来一个人无法判断他属于哪一类,这样的不确定度就非常大,如果添加了一个特征(信息增加了),就会使这种不确定度减小。那么减少的这部分不确定度就是互信息。当然了,这种不确定度减少的越多越好。
还可以用字面意思理解,所谓信息增益,就是信息增加了,就有益处了。就更容易做出决策了。
先说下经验熵和条件熵
下面说经验熵,指的是训练数据分到不同类别的熵
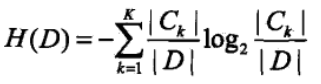
训练数据15个,9个分到同意贷款概率为9/15,6个不同意概率为6/15。那么训练数据的经验熵是。这个算出的是没有引入特征时的熵。
如果引入不同的特征特征后那么训练数据的熵是多少呢?
这就是条件熵
引入年龄这个特征后,就需要算出每个年龄段也就是这个特征的每一个划分的条件熵之后求和。
青年的概率是5/15,中年的概率恰好也是5/15,老年的概率恰好也是5/15
那么青年这个划分(用D1表示)的经验熵是H(D1),所以青年的条件熵是5/15*H(D1)
接下来算中年D2的熵和老年D3的熵

H(D1)是在D1区域的经验熵,D1区域里“是”有2个,概率2/5,“否”有3个,概率3/5。
公式:

信息增益的公式就是在没引入特征时的熵减去引入特征时的熵
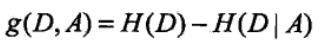
通过选择信息增益大的作为首选的特征进行分类。
下面给出计算具体:
-
按照年龄属性(记为A1)划分:青年(D1表示),中年(D2表示),老年(D3表示)
-
按照是否有工作(记为A2)划分:有工作(D1表示),无工作(D2表示)
-
按照是否有自己房子(记为A3)划分:有自己房子(D1表示),无自己房子(D2表示)
-
同理,根据最后一个属性:信贷情况算出其信息增益:
由于A3有房子的信息熵益最大,引入它可以使得分类的效果更好,所以选择它为最优特征。
您可以查找公众号:hlju_nlp 或扫描如下二维码,即可关注“黑龙江大学自然语言处理实验室”:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号