
Opencv模型训练-Python
序言:分类器
正文开始之前,我先用的理解来解读一下什么是分类器。
我们给程序一张图片,问它:这是啥?
程序:我咋知道!
好吧,程序并不知道我们给它展示的是什么东西,但我们可以让它学习。我们靠眼睛靠大脑感知的事物,放到程序中不过是“0000111”之类的一堆二进制字符。但就这些字符并不尽相同,哪怕只有一位之差那也是不一样的。
靠着这些区别,程序有了自己的一本字典,每次你拿出一样东西问它这是啥的时候,程序便拿出这本字典一个一个查。试想一下,你用昆虫百科全书查询某种昆虫的样子,对!程序也在干这事儿。分类器就是给程序构建了一本字典,让它可以认识一些事物。
深层的东西我不去探究(ps:探究了也不会)。
一、前期准备
为了训练我们自己的分类器,我们需要先定一个目标,这个分类器需要达成什么样的功能。暂定一下,它只能识别我们自己!这时我们需要准备一下自己美美的照片,照片的要求取决于我们需要的识别场景,举个栗子:我们日常使用就是为了进门的时候刷脸,这时我们准备的照片场景是固定的,就是进门的那一块地方,不同的就是每天不一样的自己,所以照片的要求就是不同光线下的自己、不同发型、状态下的自己,不需要太多,单一识别的样本的识别几百张足矣。
什么?你没有那么多自己的照片?那么我们可以用opencv自带的分类器识别出一些样本。好吧,收集正脸的代码放到下面了(这只是部分代码,整体代码在最后会放出)。
收集正脸
def collect_user_infor(method=0, max_img=400):
# 获取人物脸部信息
# 获取人脸图像,method的取值-0:摄像头\路径:可以是一张图片或者一段视频的路径
# max_img:最大图像数量
collect_window = cv.VideoCapture(method)
sample_num = 0
while True:
# 逐帧处理读取人脸
flag, frame = collect_window.read()
face_ = get_face(frame)
cv.imshow('Collect-press "ESC" to exit', face_)
# 如果没有信息内容、按下ESC、训练用脸部图片到达预期退出
if not flag or cv.waitKey(1) & 0xFF == 27 or sample_num == max_img:
break
# 当截取的图片符合训练要求
if len(face_) < 400:
# 向指定文件夹中写入照片
target_path = 'data/' + str(sample_num) + '.jpg'
cv.imwrite(target_path, face_)
sample_num += 1
cv.destroyWindow('Collect-press "ESC" to exit')
collect_window.release()获取脸部
def get_face(frame):
HAAR_PATH = 'haarcascade_frontalface_alt.xml'
# 加载分类器
face_cascade = cv.CascadeClassifier(HAAR_PATH)
# 转化为灰度图片
img_gray = cv.cvtColor(frame, cv.COLOR_BGR2GRAY)
# 识别,1.3是每次搜索区域扩大的系数,代表每次扩大30%
# 5:相邻矩阵最小个数
faces = face_cascade.detectMultiScale(img_gray, 1.3, 5)
#
face_ = get_face_area(faces, frame)
return face_
def get_face_area(faces, img):
# 从一整张照片截取出人脸区域
for x, y, w, h in faces:
# img = cv.rectangle(img, (x, y), (x + w, y + h), (255, 255, 255), 1)
img = img[y:y+h, x:x+w]
return img好了,自己的照片有着落了,我们把他们放在一个文件夹中。
到此,正样本部分的前期准备就完成了,这时候你是不是要问了是不是还需要负样本,那就很聪明了。没错,负样本一定也是需要的,而且比你的正样本要多的多,多多少这取决你正样本的复杂程度。也并非越多越好。如果你的正样本从始至终都只有一个人在一种场景下,那么负样本的数量是正样本的1.1倍也是可以的。要是你的正样本场景复杂人物多变,负样本在3倍的数量也不为过。但要注意电脑配置,太多也是容易over的。
当你的正样本与负样本准备好了就可以进行下一步了。
二、训练前的准备
我们要训练一个级联分类器,并不是要用你pip install opencv后的那个opencv而是可以在windows下运行的那个,而且在某个(4.x)版本之后,我们需要的那两个文件就不再提供了,当然网上也有大神能够编译出来,你可以在某度上输入:“opencv编译traincascaded.exe 和 createsamplesd.exe”。
不想嫌麻烦?3.x版本的训练器我们也可以用,你可以使用下面我帮你整理好的(包含所有opencv3.4.1的文件,以及3个写好的bat,空的正负样本文件夹与空的训练结果文件夹):
百度网盘:https://pan.baidu.com/s/1BKt6SYsryYaGM42d_8sAoA
提 取 码:1234
当你准备好了上述的文件,我们就可以开始着手准备训练我们自己的级联分类器了:
首先,为了满足训练要求我们需要先将先前准备的正负样本文件调整到一个合适的尺寸,opencv推荐是将尺寸调整到20px*20px。这一步我们同样可以使用opencv进行:
调整尺寸
# 调整尺寸
def resize_img(IMG_PATH, new_dir, size):
# size = (20, 20),size参数需要我们传递一个元组
flag = 0 # 文件名称
# 从指定目录下读取所有的文件
image_paths = [os.path.join(IMG_PATH, file) for file in os.listdir(IMG_PATH)]
# 遍历所有文件
for image_path in image_paths:
img = cv.imread(image_path)
img = cv.resize(img, size) # 核心函数:调整尺寸到20,20
if not os.path.exists(new_dir):
# 如果文件夹不存在则新建
os.mkdir(new_dir)
# 新文件的储存路径
new_path = new_dir + '/' + str(flag) + '.jpg'
# 储存图片到新路径
cv.imwrite(new_path, img)
flag += 1正负样本我们都要调整尺寸,唯一不同的是,我们的负样本尺寸可以大一些,比如40*40。
正样本的new_dir可以设置为:posdata;负样本可以设置为:negdata(注意:这两个文件夹的位置需要在有traincascaded.exe 和 createsamplesd.exe这两个文件的文件夹中)。
如果你下载了我为你准备的train.7z,那么解压后的文件中就包含这两个文件夹,你只需把new_dir设置成他们就可以了。
![]()
首先进入到negdata文件夹中,在路径栏中输入cmd:
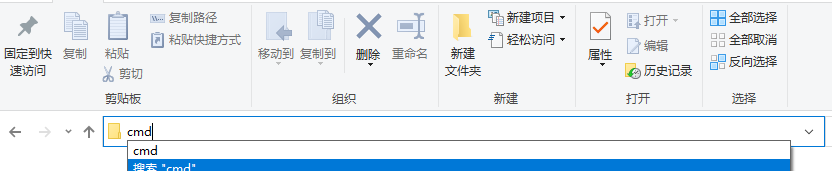
在cmd命令中输入:dir /b/s/p/w *.jpg > neg.txt
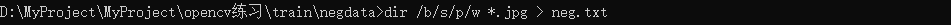
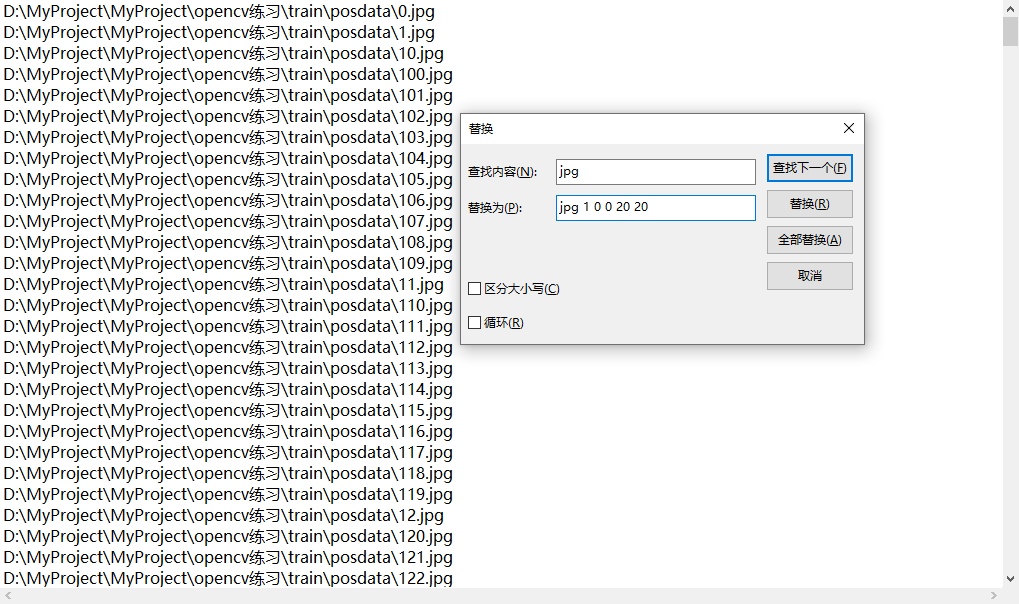
完成后我们得到了pos.txt与neg.txt两个文本文件,其中pos.txt需要我们打开,将所有jpg替换为:jpg 1 0 0 20 20,neg.txt则不需要我们这样做。
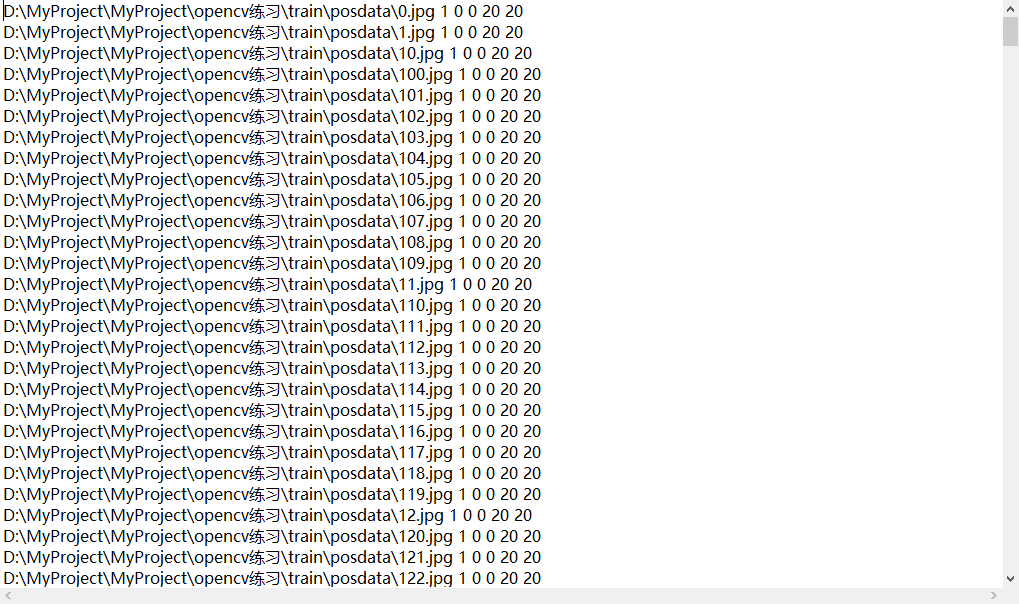
替换后:
当完成这一步,我们需要将这两个文件剪贴到上级文件夹中,现在你文件的结构应当是这样的:
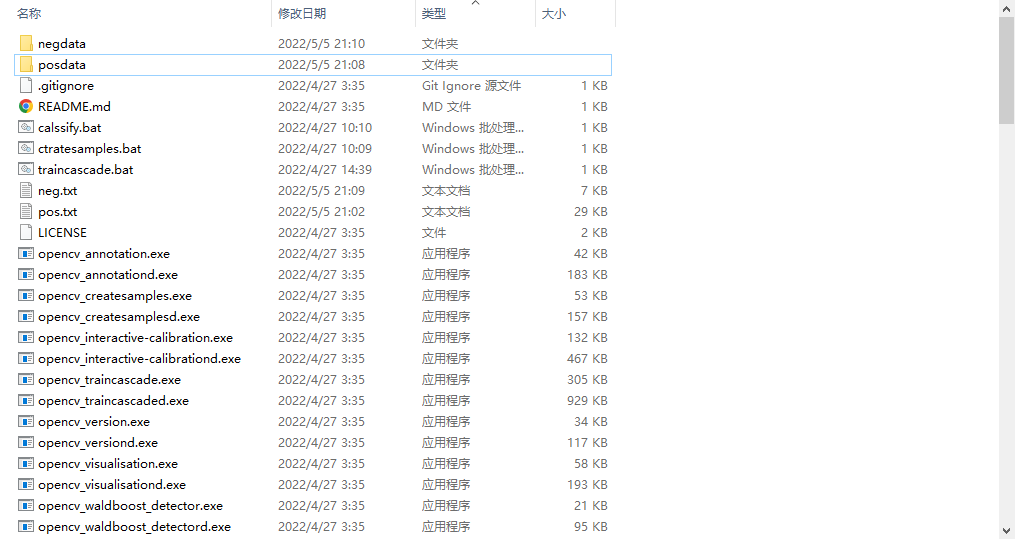
如果没有下载我的train.7z那么你只比这个文件少了三个bat文件。txt文件我们的opencv还不认识,所以我们要将他们转化为nec文件。
我们需要在当前目录下新建两个bat文件:
classify.bat
编辑:opencv_createsamples.exe -vec neg.vec -info neg.txt -num 699 -w 50 -h 50
ctratesamples.bat
编辑:opencv_createsamples.exe -vec pos.vec -info pos.txt -num 517 -w 20 -h 20
需要注意的是其他内容不用去修改,你只需要注意-num/-w/-h后的数字(说明如下文),除非你当时运行cmd时输入的名字不是pos.txt\neg.txt,又或者你不想把他们命名成跟我一样的。
-num XXX: XXX代表你的样本数,其中ctratesamples.bat是正样本数,classify.bat是负样本数。
-h XX:代表你尺寸修改后的图片高度。
-w XX:代表你尺寸修改后的图片宽度。

当你完成这些,运行他们!

当你的目录下,出现这两个文件时,那么你便可以开始最后,也是最关键的一步了:开始训练!!!
在当前目录下新建:
traincascade.bat
编辑:
opencv_traincascade.exe -data xml -vec pos.vec -bg neg.txt -numPos 500 -numNeg 690 -numStages 20 -w 20 -h 20 -precalcValBufSize 1024 -precalcIdxBufSize 1024 -minHitRate 0.999 -maxFalseAlarmRate 0.4 -mode ALL
pause
以下是参数说明:
-data:当前分类器储存的文件夹名称。
-vec:我们创建的正样本vec文件的名称。
-bg:我们创建的负样本vec文件名称。
-numPos:正样本数量,注意:填写的数量要小于实际数量,这里是需要我们根据自己的样本数量修改的。
-numNeg:负样本数量,注意:填写的数量可以大于实际数量,这里这里是需要我们根据自己的样本数量修改的。
-numStages:最大训练深度,20就是20层,但训练可能不会到最大层数,样本少且形态单一时可能6-9层就结束了。
-w,-h:是我们正样本的图像的宽与高,当你的图片大小与本文章所写的不一致时,需要修改,但是需要注意的是图像越大训练的越慢。
-precalcValBufSize、-precalcIdxBufSize:缓存大小,前者计算特征值,后者计算索引。
-minHitRate:每层检测最小期望检测率。
-maxFalseAlarmRate:每层的期望误检率。
-mode:HAAR特征的模式,有三种BASIC、CORE、ALL
还有一些其他的参数,可以自行某度一下。

当我们完成上述所有内容后,别忘了在当前目录创建一个文件夹xml,用于存放训练数据:

最后,运行traincascade.bat!!!
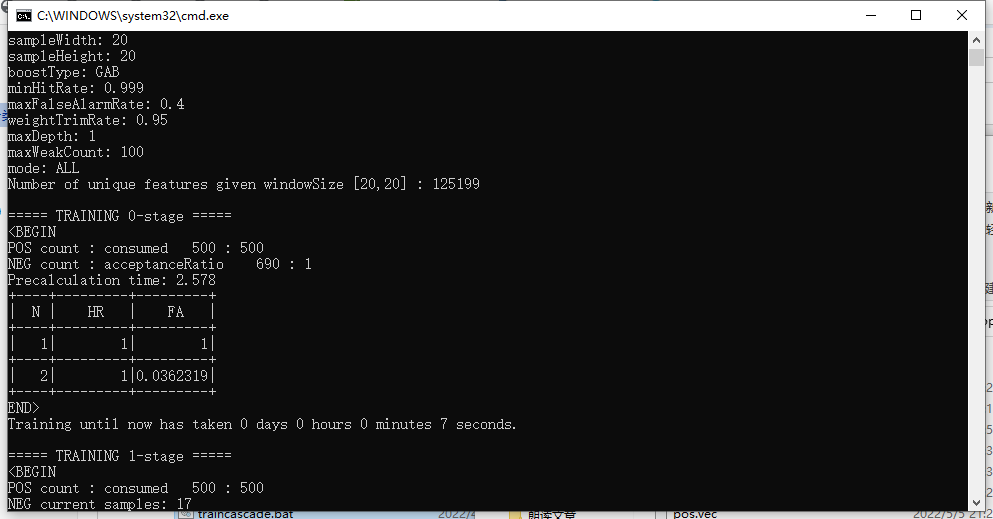
当出现如下界面时,那么静候它完成。
训练结束时,你会在xml目录中得到以下文件,其中cascade.xml便是我们最终所需要的级联分类器!
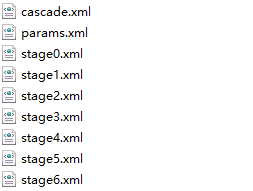
把他修改一个你喜欢的名字,去试试吧!我们可以尝试写一个函数或者写一个类去测试我们的成果:
函数
import cv2 as cv
def computer_can_know_me(haar_path, win_type):
# 读取摄像头/图片/视频
collect_window = cv.VideoCapture(win_type)
# 加载分类器
face_cascade = cv.CascadeClassifier(haar_path)
# 动态读取
while True:
# 从读取的摄像头/图片/视频实例中获取信息与画面
flag, frame = collect_window.read()
# 如果没有读取到信息或按下了ESC键,则退出循环
if not flag or cv.waitKey(1) & 0xFF == 27:
break
# 从灰度模式打开图片
frame_gray = cv.cvtColor(frame, cv.COLOR_BGR2GRAY)
# 开始识别
faces = face_cascade.detectMultiScale(frame_gray, 1.3, 5)
# 框选出脸部区域
for x, y, w, h in faces:
frame = cv.rectangle(frame, (x, y), (x + w, y + h), (255, 255, 255), 1)
# 展示在屏幕上
cv.imshow('Myself', frame)
# 循环结束销毁所有窗口与读取的摄像头/图片/视频
cv.destroyWindow('Myself')
collect_window.release()
if __name__ == '__main__':
harr = 'xml/cascade.xml'
computer_can_know_me(harr, 0)最后
自此你的程序有了一本关于你的字典,每当你运行它时,他总会认识你。
整体代码:
全部代码
import cv2 as cv
import os
def collect_user_infor(method=0, max_img=400):
# 获取人物脸部信息
# 获取人脸图像,method的取值-0:摄像头\路径:可以是一张图片或者一段视频的路径
# max_img:最大图像数量
collect_window = cv.VideoCapture(method)
sample_num = 0
if not os.path.exists('posdata'):
os.mkdir('posdata')
while True:
# 逐帧处理读取人脸
flag, frame = collect_window.read()
face_ = get_face(frame)
cv.imshow('Collect-press "ESC" to exit', face_)
# 如果没有信息内容、按下ESC、训练用脸部图片到达预期退出
if not flag or cv.waitKey(1) & 0xFF == 27 or sample_num == max_img:
break
# 当截取的图片符合训练要求
if len(face_) < 400:
# 向指定文件夹中写入照片
target_path = 'posdata/' + str(sample_num) + '.jpg'
cv.imwrite(target_path, face_)
sample_num += 1
cv.destroyWindow('Collect-press "ESC" to exit')
collect_window.release()
def get_face(frame):
HAAR_PATH = 'haarcascade_frontalface_alt.xml'
# 加载分类器
face_cascade = cv.CascadeClassifier(HAAR_PATH)
# 转化为灰度图片
img_gray = cv.cvtColor(frame, cv.COLOR_BGR2GRAY)
# 识别,1.3是每次搜索区域扩大的系数,代表每次扩大30%
# 5:相邻矩阵最小个数
faces = face_cascade.detectMultiScale(img_gray, 1.3, 5)
#
face_ = get_face_area(faces, frame)
return face_
def get_face_area(faces, img):
# 从一整张照片截取出人脸区域
for x, y, w, h in faces:
# img = cv.rectangle(img, (x, y), (x + w, y + h), (255, 255, 255), 1)
img = img[y:y + h, x:x + w]
return img
def computer_can_know_me(haar_path, win_type):
# 读取摄像头/图片/视频
collect_window = cv.VideoCapture(win_type)
# 加载分类器
face_cascade = cv.CascadeClassifier(haar_path)
# 动态读取
while True:
# 从读取的摄像头/图片/视频实例中获取信息与画面
flag, frame = collect_window.read()
# 如果没有读取到信息或按下了ESC键,则退出循环
if not flag or cv.waitKey(1) & 0xFF == 27:
break
# 从灰度模式打开图片
frame_gray = cv.cvtColor(frame, cv.COLOR_BGR2GRAY)
# 开始识别
faces = face_cascade.detectMultiScale(frame_gray, 1.3, 5)
# 框选出脸部区域
for x, y, w, h in faces:
frame = cv.rectangle(frame, (x, y), (x + w, y + h), (255, 255, 255), 1)
# 展示在屏幕上
cv.imshow('Myself', frame)
# 循环结束销毁所有窗口与读取的摄像头/图片/视频
cv.destroyWindow('Myself')
collect_window.release()
# 调整尺寸
def resize_img(IMG_PATH, new_dir, size):
# size = (20, 20),size参数需要我们传递一个元组
flag = 0 # 文件名称
# 从指定目录下读取所有的文件
image_paths = [os.path.join(IMG_PATH, file) for file in os.listdir(IMG_PATH)]
# 遍历所有文件
for image_path in image_paths:
img = cv.imread(image_path)
img = cv.resize(img, size) # 核心函数:调整尺寸到20,20
if not os.path.exists(new_dir):
# 如果文件夹不存在则新建
os.mkdir(new_dir)
# 新文件的储存路径
new_path = new_dir + '/' + str(flag) + '.jpg'
# 储存图片到新路径
cv.imwrite(new_path, img)
flag += 1
本文来自博客园,作者:梦月剑心,转载请注明原文链接:https://www.cnblogs.com/ldooo/articles/16220130.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号