第七篇 python基础之函数,递归,内置函数
阅读目录
一 数学定义的函数与python中的函数
初中数学函数定义:一般的,在一个变化过程中,如果有两个变量x和y,并且对于x的每一个确定的值,y都有唯一确定的值与其对应,那么我们就把x称为自变量,把y称为因变量,y是x的函数。自变量x的取值范围叫做这个函数的定义域
例如y=2*x
python中函数定义:函数是逻辑结构化和过程化的一种编程方法。

1 python中函数定义方法: 2 3 def test(x): 4 "The function definitions" 5 x+=1 6 return x 7 8 def:定义函数的关键字 9 test:函数名 10 ():内可定义形参 11 "":文档描述(非必要,但是强烈建议为你的函数添加描述信息) 12 x+=1:泛指代码块或程序处理逻辑 13 return:定义返回值
调用运行:可以带参数也可以不带
函数名()
补充:
1.编程语言中的函数与数学意义的函数是截然不同的俩个概念,编程语言中的函数是通过一个函数名封装好一串用来完成某一特定功能的逻辑,数学定义的函数就是一个等式,等式在传入因变量值x不同会得到一个结果y,这一点与编程语言中类似(也是传入一个参数,得到一个返回值),不同的是数学意义的函数,传入值相同,得到的结果必然相同且没有任何变量的修改(不修改状态),而编程语言中的函数传入的参数相同返回值可不一定相同且可以修改其他的全局变量值(因为一个函数a的执行可能依赖于另外一个函数b的结果,b可能得到不同结果,那即便是你给a传入相同的参数,那么a得到的结果也肯定不同)
2.函数式编程就是:先定义一个数学函数(数学建模),然后按照这个数学模型用编程语言去实现它。至于具体如何实现和这么做的好处,且看后续的函数式编程。
二 为何使用函数
背景提要
现在老板让你写一个监控程序,监控服务器的系统状况,当cpu\memory\disk等指标的使用量超过阀值时即发邮件报警,你掏空了所有的知识量,写出了以下代码
上面的代码实现了功能,但即使是邻居老王也看出了端倪,老王亲切的摸了下你家儿子的脸蛋,说,你这个重复代码太多了,每次报警都要重写一段发邮件的代码,太low了,这样干存在2个问题:
- 代码重复过多,一个劲的copy and paste不符合高端程序员的气质
- 如果日后需要修改发邮件的这段代码,比如加入群发功能,那你就需要在所有用到这段代码的地方都修改一遍
你觉得老王说的对,你也不想写重复代码,但又不知道怎么搞,老王好像看出了你的心思,此时他抱起你儿子,笑着说,其实很简单,只需要把重复的代码提取出来,放在一个公共的地方,起个名字,以后谁想用这段代码,就通过这个名字调用就行了,如下
def 发送邮件(内容)
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接
while True:
if cpu利用率 > 90%:
发送邮件('CPU报警')
if 硬盘使用空间 > 90%:
发送邮件('硬盘报警')
if 内存占用 > 80%:
发送邮件('内存报警')
你看着老王写的代码,气势恢宏、磅礴大气,代码里透露着一股内敛的傲气,心想,老王这个人真是不一般,突然对他的背景更感兴趣了,问老王,这些花式玩法你都是怎么知道的? 老王亲了一口你儿子,捋了捋不存在的胡子,淡淡的讲,“老夫,年少时,师从京西沙河淫魔银角大王 ”, 你一听“银角大王”这几个字,不由的娇躯一震,心想,真nb,怪不得代码写的这么6, 这“银角大王”当年在江湖上可是数得着的响当当的名字,只可惜后期纵欲过度,卒于公元2016年, 真是可惜了,只留下其哥哥孤守当年兄弟俩一起打下来的江山。 此时你看着的老王离开的身影,感觉你儿子跟他越来越像了。。。
总结使用函数的好处:
1.代码重用
2.保持一致性,易维护
3.可扩展性
三 函数和过程
过程定义:过程就是简单特殊没有返回值的函数
这么看来我们在讨论为何使用函数的的时候引入的函数,都没有返回值,没有返回值就是过程,没错,但是在python中有比较神奇的事情
1 def test01(): 2 msg='hello The little green frog' 3 print msg 4 5 def test02(): 6 msg='hello WuDaLang' 7 print msg 8 return msg 9 10 11 t1=test01() 12 13 t2=test02() 14 15 16 print 'from test01 return is [%s]' %t1 17 print 'from test02 return is [%s]' %t2
总结:当一个函数/过程没有使用return显示的定义返回值时,python解释器会隐式的返回None,
所以在python中即便是过程也可以算作函数。
1 def test01():
2 pass
3
4 def test02():
5 return 0
6
7 def test03():
8 return 0,10,'hello',['alex','lb'],{'WuDaLang':'lb'}
9
10 t1=test01()
11 t2=test02()
12 t3=test03()
13
14
15 print 'from test01 return is [%s]: ' %type(t1),t1
16 print 'from test02 return is [%s]: ' %type(t2),t2
17 print 'from test03 return is [%s]: ' %type(t3),t3
总结:
返回值数=0:返回None
返回值数=1:返回object
返回值数>1:返回tuple
四 函数参数
1.形参变量只有在被调用时才分配内存单元,在调用结束时,即刻释放所分配的内存单元。因此,形参只在函数内部有效。函数调用结束返回主调用函数后则不能再使用该形参变量
2.实参可以是常量、变量、表达式、函数等,无论实参是何种类型的量,在进行函数调用时,它们都必须有确定的值,以便把这些值传送给形参。因此应预先用赋值,输入等办法使参数获得确定值

3.位置参数和关键字(标准调用:实参与形参位置一一对应;关键字调用:位置无需固定)
4.默认参数
5.参数组
五 局部变量和全局变量
1 name='lhf'
2
3 def change_name():
4 print('我的名字',name)
5
6 change_name()
7
8
9 def change_name():
10 name='帅了一笔'
11 print('我的名字',name)
12
13 change_name()
14 print(name)
15
16
17
18 def change_name():
19 global name
20 name='帅了一笔'
21 print('我的名字',name)
22
23 change_name()
24 print(name)
六 前向引用之'函数即变量'
1 def action(): 2 print 'in the action' 3 logger() 4 action() 5 报错NameError: global name 'logger' is not defined 6 7 8 def logger(): 9 print 'in the logger' 10 def action(): 11 print 'in the action' 12 logger() 13 14 action() 15 16 17 def action(): 18 print 'in the action' 19 logger() 20 def logger(): 21 print 'in the logger' 22 23 action()
七 嵌套函数和作用域
看上面的标题的意思是,函数还能套函数?of course
1 name = "Alex"
2
3 def change_name():
4 name = "Alex2"
5
6 def change_name2():
7 name = "Alex3"
8 print("第3层打印",name)
9
10 change_name2() #调用内层函数
11 print("第2层打印",name)
12
13
14 change_name()
15 print("最外层打印",name)
此时,在最外层调用change_name2()会出现什么效果?
没错, 出错了, 为什么呢?
作用域在定义函数时就已经固定住了,不会随着调用位置的改变而改变
1 例一: 2 name='alex' 3 4 def foo(): 5 name='lhf' 6 def bar(): 7 print(name) 8 return bar 9 10 func=foo() 11 func() 12 13 14 例二: 15 name='alex' 16 17 def foo(): 18 name='lhf' 19 def bar(): 20 name='wupeiqi' 21 def tt(): 22 print(name) 23 return tt 24 return bar 25 26 func=foo() 27 func()()
八 递归调用
古之欲明明德于天下者,先治其国;欲治其国者,先齐其家;欲齐其家者,先修其身;欲修其身者,先正其心;欲正其心者,先诚其意;欲诚其意者,先致其知,致知在格物。物格而后知至,知至而后意诚,意诚而后心正,心正而后身修,身修而后家齐,家齐而后国治,国治而后天下平。
在函数内部,可以调用其他函数。如果在调用一个函数的过程中直接或间接调用自身本身

#_*_coding:utf-8_*_
__author__ = 'Linhaifeng'
import time
person_list=['alex','wupeiqi','yuanhao','linhaifeng']
def ask_way(person_list):
print('-'*60)
if len(person_list) == 0:
return '没人知道'
person=person_list.pop(0)
if person == 'linhaifeng':
return '%s说:我知道,老男孩就在沙河汇德商厦,下地铁就是' %person
print('hi 美男[%s],敢问路在何方' %person)
print('%s回答道:我不知道,但念你慧眼识猪,你等着,我帮你问问%s...' %(person,person_list))
time.sleep(3)
res=ask_way(person_list)
# print('%s问的结果是: %res' %(person,res))
return res
res=ask_way(person_list)
print(res)
递归特性:
1. 必须有一个明确的结束条件
2. 每次进入更深一层递归时,问题规模相比上次递归都应有所减少
3. 递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层栈帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
堆栈扫盲http://www.cnblogs.com/lln7777/archive/2012/03/14/2396164.html
尾递归优化:http://egon09.blog.51cto.com/9161406/1842475
data = [1, 3, 6, 7, 9, 12, 14, 16, 17, 18, 20, 21, 22, 23, 30, 32, 33, 35]
def binary_search(dataset,find_num):
print(dataset)
if len(dataset) >1:
mid = int(len(dataset)/2)
if dataset[mid] == find_num: #find it
print("找到数字",dataset[mid])
elif dataset[mid] > find_num :# 找的数在mid左面
print("\033[31;1m找的数在mid[%s]左面\033[0m" % dataset[mid])
return binary_search(dataset[0:mid], find_num)
else:# 找的数在mid右面
print("\033[32;1m找的数在mid[%s]右面\033[0m" % dataset[mid])
return binary_search(dataset[mid+1:],find_num)
else:
if dataset[0] == find_num: #find it
print("找到数字啦",dataset[0])
else:
print("没的分了,要找的数字[%s]不在列表里" % find_num)
binary_search(data,66)
九 匿名函数
匿名函数就是不需要显式的指定函数
1 #这段代码 2 def calc(n): 3 return n**n 4 print(calc(10)) 5 6 #换成匿名函数 7 calc = lambda n:n**n 8 print(calc(10))
你也许会说,用上这个东西没感觉有毛方便呀, 。。。。呵呵,如果是这么用,确实没毛线改进,不过匿名函数主要是和其它函数搭配使用的呢,如下
1 l=[3,2,100,999,213,1111,31121,333]
2 print(max(l))
3
4 dic={'k1':10,'k2':100,'k3':30}
5
6
7 print(max(dic))
8 print(dic[max(dic,key=lambda k:dic[k])])
1 res = map(lambda x:x**2,[1,5,7,4,8]) 2 for i in res: 3 print(i) 4 5 输出 6 1 7 25 8 49 9 16 10 64
十 函数式编程
峰哥原创面向过程解释:
函数的参数传入,是函数吃进去的食物,而函数return的返回值,是函数拉出来的结果,面向过程的思路就是,把程序的执行当做一串首尾相连的函数,一个函数吃,拉出的东西给另外一个函数吃,另外一个函数吃了再继续拉给下一个函数吃。。。
例如:
用户登录流程:前端接收处理用户请求-》将用户信息传给逻辑层,逻辑词处理用户信息-》将用户信息写入数据库
验证用户登录流程:数据库查询/处理用户信息-》交给逻辑层,逻辑层处理用户信息-》用户信息交给前端,前端显示用户信息
函数式编程:
http://egon09.blog.51cto.com/9161406/1842475
11 高阶函数
满足俩个特性任意一个即为高阶函数
1.函数的传入参数是一个函数名
2.函数的返回值是一个函数名
array=[1,3,4,71,2]
ret=[]
for i in array:
ret.append(i**2)
print(ret)
#如果我们有一万个列表,那么你只能把上面的逻辑定义成函数
def map_test(array):
ret=[]
for i in array:
ret.append(i**2)
return ret
print(map_test(array))
#如果我们的需求变了,不是把列表中每个元素都平方,还有加1,减一,那么可以这样
def add_num(x):
return x+1
def map_test(func,array):
ret=[]
for i in array:
ret.append(func(i))
return ret
print(map_test(add_num,array))
#可以使用匿名函数
print(map_test(lambda x:x-1,array))
#上面就是map函数的功能,map得到的结果是可迭代对象
print(map(lambda x:x-1,range(5)))
from functools import reduce
#合并,得一个合并的结果
array_test=[1,2,3,4,5,6,7]
array=range(100)
#报错啊,res没有指定初始值
def reduce_test(func,array):
l=list(array)
for i in l:
res=func(res,i)
return res
# print(reduce_test(lambda x,y:x+y,array))
#可以从列表左边弹出第一个值
def reduce_test(func,array):
l=list(array)
res=l.pop(0)
for i in l:
res=func(res,i)
return res
print(reduce_test(lambda x,y:x+y,array))
#我们应该支持用户自己传入初始值
def reduce_test(func,array,init=None):
l=list(array)
if init is None:
res=l.pop(0)
else:
res=init
for i in l:
res=func(res,i)
return res
print(reduce_test(lambda x,y:x+y,array))
print(reduce_test(lambda x,y:x+y,array,50))
#电影院聚集了一群看电影bb的傻逼,让我们找出他们
movie_people=['alex','wupeiqi','yuanhao','sb_alex','sb_wupeiqi','sb_yuanhao']
def tell_sb(x):
return x.startswith('sb')
def filter_test(func,array):
ret=[]
for i in array:
if func(i):
ret.append(i)
return ret
print(filter_test(tell_sb,movie_people))
#函数filter,返回可迭代对象
print(filter(lambda x:x.startswith('sb'),movie_people))
#当然了,map,filter,reduce,可以处理所有数据类型
name_dic=[
{'name':'alex','age':1000},
{'name':'wupeiqi','age':10000},
{'name':'yuanhao','age':9000},
{'name':'linhaifeng','age':18},
]
#利用filter过滤掉千年王八,万年龟,还有一个九千岁
def func(x):
age_list=[1000,10000,9000]
return x['age'] not in age_list
res=filter(func,name_dic)
for i in res:
print(i)
res=filter(lambda x:x['age'] == 18,name_dic)
for i in res:
print(i)
#reduce用来计算1到100的和
from functools import reduce
print(reduce(lambda x,y:x+y,range(100),100))
print(reduce(lambda x,y:x+y,range(1,101)))
#用map来处理字符串列表啊,把列表中所有人都变成sb,比方alex_sb
name=['alex','wupeiqi','yuanhao']
res=map(lambda x:x+'_sb',name)
for i in res:
print(i)
十一 内置函数

字典的运算:最小值,最大值,排序
salaries={
'egon':3000,
'alex':100000000,
'wupeiqi':10000,
'yuanhao':2000
}
迭代字典,取得是key,因而比较的是key的最大和最小值
>>> max(salaries)
'yuanhao'
>>> min(salaries)
'alex'
可以取values,来比较
>>> max(salaries.values())
100000000
>>> min(salaries.values())
2000
但通常我们都是想取出,工资最高的那个人名,即比较的是salaries的值,得到的是键
>>> max(salaries,key=lambda k:salary[k])
'alex'
>>> min(salaries,key=lambda k:salary[k])
'yuanhao'
也可以通过zip的方式实现
salaries_and_names=zip(salaries.values(),salaries.keys())
先比较值,值相同则比较键
>>> max(salaries_and_names)
(100000000, 'alex')
salaries_and_names是迭代器,因而只能访问一次
>>> min(salaries_and_names)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ValueError: min() arg is an empty sequence
sorted(iterable,key=None,reverse=False)
内置参数详解 https://docs.python.org/3/library/functions.html?highlight=built#ascii
十二 本节作业
有以下员工信息表
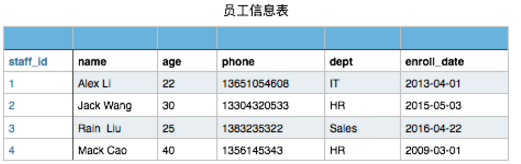
当然此表你在文件存储时可以这样表示
1 1,Alex Li,22,13651054608,IT,2013-04-01
现需要对这个员工信息文件,实现增删改查操作
- 可进行模糊查询,语法至少支持下面3种:
- select name,age from staff_table where age > 22
- select * from staff_table where dept = "IT"
- select * from staff_table where enroll_date like "2013"
- 查到的信息,打印后,最后面还要显示查到的条数
- 可创建新员工纪录,以phone做唯一键,staff_id需自增
- 可删除指定员工信息纪录,输入员工id,即可删除
- 可修改员工信息,语法如下:
- UPDATE staff_table SET dept="Market" WHERE where dept = "IT"
注意:以上需求,要充分使用函数,请尽你的最大限度来减少重复代码!
内置函数
匿名函数
递归
=====================作业一
#用map来处理字符串列表啊,把列表中所有人都变成sb,比方alex_sb
name=['alex','wupeiqi','yuanhao']
#用map来处理下述l,然后用list得到一个新的列表,列表中每个人的名字都是sb结尾
>>> l=[{'name':'alex'},{'name':'y'}]
>>> x=map(lambda i:{'name':i['name']+'sb'},l)
>>> for i in x:
... print(i)
...
{'name': 'alexsb'}
{'name': 'ysb'}
=====================作业二
#用filter来处理,得到股票价格大于20的股票名字
shares={
'IBM':36.6,
'Lenovo':23.2,
'oldboy':21.2,
'ocean':10.2,
}
>>> f=filter(lambda k:shares[k]>20,shares)
>>> list(f)
['IBM', 'Lenovo', 'oldboy']
=====================作业三
#如下,每个小字典的name对应股票名字,shares对应多少股,price对应股票的价格
portfolio = [
{'name': 'IBM', 'shares': 100, 'price': 91.1},
{'name': 'AAPL', 'shares': 50, 'price': 543.22},
{'name': 'FB', 'shares': 200, 'price': 21.09},
{'name': 'HPQ', 'shares': 35, 'price': 31.75},
{'name': 'YHOO', 'shares': 45, 'price': 16.35},
{'name': 'ACME', 'shares': 75, 'price': 115.65}
]
1:map来得出一个包含数字的迭代器,数字指的是:购买每支股票的总价格
>>> m=map(lambda item:item['shares']*item['price'],l)
2:基于1的结果,用reduce来计算,购买这些股票总共花了多少钱
>>> r=reduce(lambda x,y:x+y,m)
>>> r
51009.75
3:用filter过滤出,单价大于100的股票有哪些
>>> f=filter(lambda item:item['price'] > 100,l)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号