scrapy-基础
一、创建一个项目
1、 pip3 install scrapy
2、scrapy startproject myspider
二、生成一个爬虫
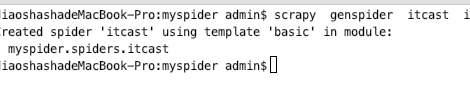
3、scrapy genspider itcast itcast.cn scrapy genspider + 爬虫名字 + 爬虫范围。
三 提取数据
5、完善 spider 使用 xpath等方法
四 保存数据
pipeline中保存数据
五、启动 scrapy
scrapy crawl itcast ##### scrapy crawl+ 项目名字
ret1 = response.xpath("//div[@class='tea_con']//h3/text()")
print(ret1)
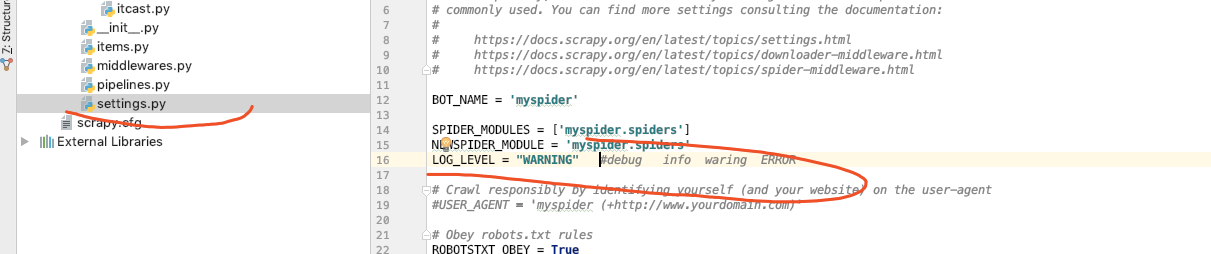
设置日志:
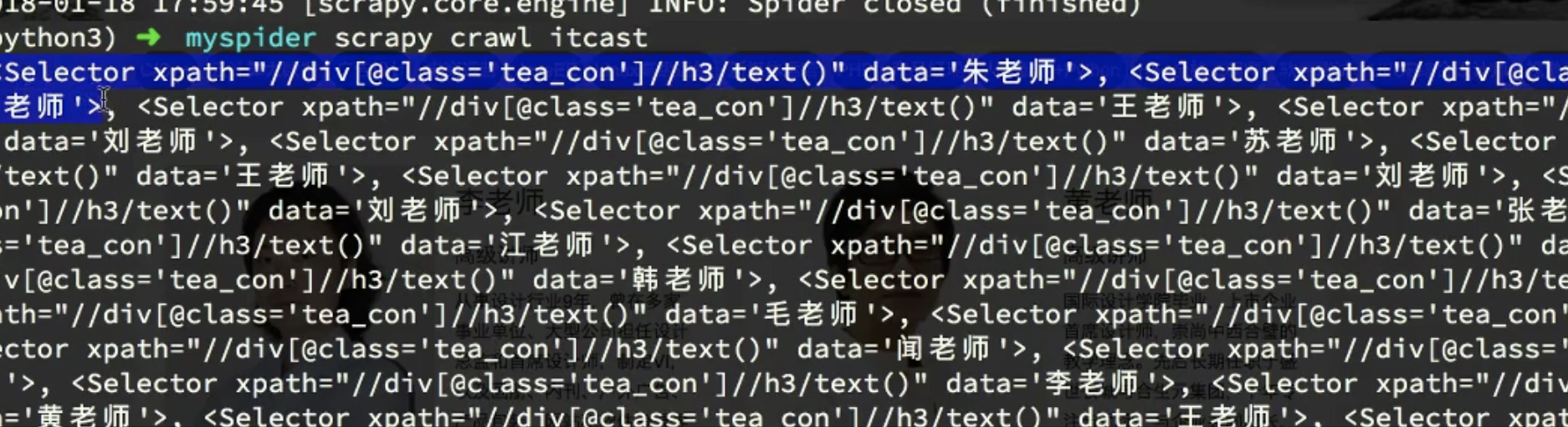
列表,列表中的每个元素是对象, 每个对象是 selector 对象 selector 有个 xpath 有个 data
9、

ret1 = response.xpath("//div[@class='tea_con']//h3/text()").extract()
print(ret1)
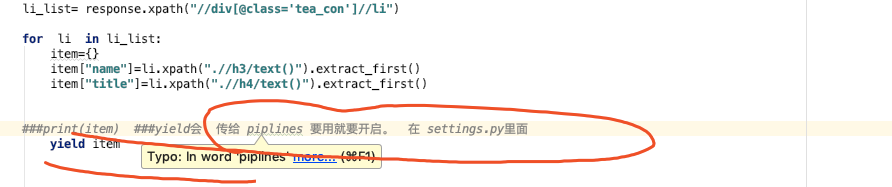

KEY代表 piplines的位置,值代表 距离引擎的远近

值 距离引擎的远近,越小 优先级 越大。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号