初步学习深度学习基础
在正式开始学习之前,要先搭建好所需要的环境。
代码练习需要使用谷歌的 Colab,它是一个 Jupyter 笔记本环境,已经默认安装好 pytorch,不需要进行任何设置就可以使用,并且完全云端运行。现在国内无法直接访问 Colab,可以用自己的梯子,或者安装 Ghelper 来访问 Colab。
当安装好 Ghelper,若仍无法访问 Colab, 那么就需要你开通 Ghelper 的 VIP 来使用完整版的 Ghelper 了。
Colab 的使用方法可以参考博客:Google Colab免费GPU使用教程
1. 安装Pytorch
若你想在本地运行代码,Pytorch 的安装可以直接访问官网,如下所示,按照官网的教程来进行安装:https://pytorch.org/get-started/locally/

根据自己的电脑系统以及所使用的编程语言选择不同的安装方式 ( Conda、Pip、LibTorch 或者下载源码自行安装),如果是 GPU 版本,就需要选择 CUDA 的 版本,之后直接在终端运行命令便可完成安装。若不喜欢官网的英文,你也可以上网自行搜索详细的安装步骤,这里推荐一个快速入门的 Pytorch 教程,里面也有详细的安装教程:快速入门Pytorch。
2. Pytorch基础练习
练习使用 Pytorch 的基础代码可以参看官网文档:https://pytorch.org/docs/stable/index.html,也可以参考上方推荐的 快速入门Pytorch
2.1. Pytorch基本操作
首先介绍一下张量(Tensors),张量相当于 Numpy 的多维数组,二者的区别就是 Tensors 可以应用到 GPU 上加快计算速度。
首先导入 torch 库:
# 导入 torch 库
import torch 2.1.1. 定义数据
一般定义数据使用 torch.Tensor , tensor 的意思是张量,是数字各种形式的总称。
torch.tensor() 直接传递 tensor 数值来创建:
# 输出一个数
x = torch.tensor(123)
print(x)输出结果为:
tensor(123)也可以用其来创建数组:
# 输出一个一维数组
x = torch.tensor([6, 6, 6, 6, 6, 6])
print(x)输出结果为:
tensor([6, 6, 6, 6, 6, 6]) torch.ones() 创建任意维度的数组(张量),以二维数组为例:
# 输出一个二维数组
x = torch.ones(5, 3)
print(x)输出结果为:
tensor([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]])torch.zeros() 创建数值皆为 0 的张量:
# 创建一个全0的张量
zero_x = torch.zeros(5, 3)
print(zero_x)输出结果为:
tensor([[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.],
[0., 0., 0.]])torch.empty() 声明一个未初始化的张量:
# 创建一个空张量, 未初始化
empty_x = torch.empty(5, 3)
print(empty_x)输出结果为:
tensor([[6.5907e-35, 0.0000e+00, 3.5032e-44],
[0.0000e+00, nan, 6.4460e-44],
[1.1578e+27, 7.1463e+22, 4.6241e+30],
[1.0552e+24, 5.5757e-02, 1.8728e+31],
[5.9571e-02, 7.0374e+22, 0.0000e+00]])torch.rand() 随机初始化一个均匀分布的张量:
# 创建一个随机初始化的张量
rand_x = torch.rand(5, 3)
print(rand_x)输出结果为:
tensor([[0.0397, 0.2020, 0.5801],
[0.0032, 0.5829, 0.8154],
[0.4831, 0.0545, 0.8530],
[0.0574, 0.2495, 0.7098],
[0.4618, 0.2584, 0.9779]])torch.randn()是随机初始化一个正态分布的张量,这里需要与上一个 torch.rand() 区分开。
torch.arange 与 torch.range 获得一个排列的序列
# 创建一个从 1 到 5 排列的数组
# 这里列出的元素是 1~5,不包括5
v = torch.arange(1, 5)
print(v)
# 这里列出的元素是1~8,包括8
w = torch.range(1, 8)
print(w)输出结果为:
tensor([1, 2, 3, 4])
tensor([1., 2., 3., 4., 5., 6., 7., 8.])
torch 的相关操作还有很多,想要了解更多可以查看官方文档:https://pytorch.org/docs/stable/torch.html
2.2.2 定义操作
凡是用Tensor进行各种运算的,都是Function
最终,还是需要用Tensor来进行计算的,计算无非是:
- 基本运算,加减乘除,求幂求余
- 布尔运算,大于小于,最大最小
- 线性运算,矩阵乘法,求模,求行列式
基本运算包括: abs/sqrt/div/exp/fmod/pow ,及一些三角函数 cos/ sin/ asin/ atan2/ cosh,及 ceil/round/floor/trunc 等
布尔运算包括: gt/lt/ge/le/eq/ne,topk, sort, max/min
线性计算包括: trace, diag, mm/bmm,t,dot/cross,inverse,svd 等
下面简单列举几个实例
#创建一个初始化的数组
m = torch.tensor([[2, 5, 3, 7],
[4, 2, 1, 9]])
print(m)
# 返回每一行第一个元素
print(m.size(), m.size(0), m.size(1), sep = ' , ')
# 输出数组元素个数
print("元素个数共", m.numel(), "个")输出结果为:
tensor([[2, 5, 3, 7],
[4, 2, 1, 9]])
torch.Size([2, 4]) , 2 , 4
元素个数共 8 个遍历数组的某一行或者某一列:
print(m)
# 返回第1行,第3列的元素,从第0行、第0列开始算起
print(m[1][3])
# 返回第0行全部元素
print(m[0, :])
# 返回第2列全部元素
print(m[:, 2])输出结果为:
tensor([[2, 5, 3, 7],
[4, 2, 1, 9]])
tensor(9)
tensor([2, 5, 3, 7])
tensor([3, 1])# 输出一个长度为20,均匀排列的从 3 到 8 的数
print(torch.linspace(3, 8, 20)) # (8-3+1)/20=0.2632
print(torch.linspace(10, 21, 11)) # (21-10+1)/11=1.1
print(torch.linspace(5, 14, 10)) # (14-5+1)/10=1输出结果为:
tensor([3.0000, 3.2632, 3.5263, 3.7895, 4.0526, 4.3158, 4.5789, 4.8421, 5.1053,
5.3684, 5.6316, 5.8947, 6.1579, 6.4211, 6.6842, 6.9474, 7.2105, 7.4737,
7.7368, 8.0000])
tensor([10.0000, 11.1000, 12.2000, 13.3000, 14.4000, 15.5000, 16.6000, 17.7000,
18.8000, 19.9000, 21.0000])
tensor([ 5., 6., 7., 8., 9., 10., 11., 12., 13., 14.])通过使用 randn 来生成正态分布的统计图:
from matplotlib import pyplot as plt
# 注意 randn 是生成均值为 0, 方差为 1 的随机数
# 下面是生成 1000 个随机数,并按照 100 个 bin 统计直方图
plt.hist(torch.randn(1000).numpy(), 100)输出的结果以及生成的图形为:
(array([ 1., 3., 0., 0., 0., 0., 1., 1., 0., 2., 2., 0., 5.,
4., 2., 3., 2., 7., 3., 6., 5., 5., 8., 8., 3., 8.,
7., 12., 13., 14., 12., 18., 10., 15., 13., 15., 22., 27., 18.,
26., 25., 26., 24., 17., 20., 26., 21., 24., 32., 29., 26., 30.,
23., 19., 24., 22., 21., 22., 25., 21., 19., 20., 14., 14., 18.,
6., 19., 19., 11., 11., 5., 7., 7., 7., 6., 4., 4., 3.,
3., 3., 4., 4., 2., 2., 0., 0., 2., 0., 1., 1., 2.,
0., 1., 0., 0., 1., 0., 0., 0., 2.]),
array([-2.8958085 , -2.8350244 , -2.7742405 , -2.7134564 , -2.6526723 ,
-2.5918884 , -2.5311043 , -2.4703202 , -2.4095364 , -2.3487523 ,
-2.2879682 , -2.2271843 , -2.1664002 , -2.105616 , -2.044832 ,
-1.9840481 , -1.923264 , -1.86248 , -1.8016961 , -1.740912 ,
-1.680128 , -1.6193439 , -1.5585599 , -1.4977759 , -1.4369918 ,
-1.3762078 , -1.3154238 , -1.2546397 , -1.1938558 , -1.1330718 ,
-1.0722877 , -1.0115037 , -0.95071965, -0.8899356 , -0.82915163,
-0.7683676 , -0.70758355, -0.6467995 , -0.5860155 , -0.5252315 ,
-0.46444744, -0.40366343, -0.3428794 , -0.28209537, -0.22131135,
-0.16052732, -0.0997433 , -0.03895928, 0.02182475, 0.08260877,
0.1433928 , 0.20417683, 0.26496086, 0.32574487, 0.3865289 ,
0.44731292, 0.50809693, 0.568881 , 0.629665 , 0.690449 ,
0.75123304, 0.8120171 , 0.8728011 , 0.9335851 , 0.99436915,
1.0551531 , 1.1159372 , 1.1767212 , 1.2375052 , 1.2982893 ,
1.3590733 , 1.4198574 , 1.4806414 , 1.5414253 , 1.6022094 ,
1.6629934 , 1.7237774 , 1.7845615 , 1.8453455 , 1.9061295 ,
1.9669136 , 2.0276976 , 2.0884817 , 2.1492655 , 2.2100496 ,
2.2708337 , 2.3316176 , 2.3924017 , 2.4531858 , 2.51397 ,
2.5747538 , 2.6355379 , 2.696322 , 2.7571058 , 2.81789 ,
2.878674 , 2.939458 , 3.000242 , 3.061026 , 3.12181 ,
3.182594 ], dtype=float32),
<a list of 100 Patch objects>)
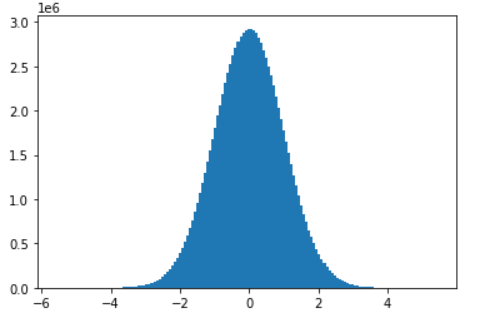
下面进一步生成更多随机数,会发现图像越来越接近正态分布:
plt.hist(torch.randn(10**8).numpy(), 150)生成图像如下:
3. 螺旋数据分类
!wget https://raw.githubusercontent.com/Atcold/pytorch-Deep-Learning/master/res/plot_lib.pyimport random
import torch
from torch import nn, optim
import math
from IPython import display
from plot_lib import plot_data, plot_model, set_default
# 因为colab是支持GPU的,torch 将在 GPU 上运行
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
print('device: ', device)
# 初始化随机数种子。神经网络的参数都是随机初始化的,
# 不同的初始化参数往往会导致不同的结果,当得到比较好的结果时我们通常希望这个结果是可以复现的,
# 因此,在pytorch中,通过设置随机数种子也可以达到这个目的
seed = 12345
random.seed(seed)
torch.manual_seed(seed)
N = 1000 # 每类样本的数量
D = 2 # 每个样本的特征维度
C = 3 # 样本的类别
H = 100 # 神经网络里隐层单元的数量device: cpudevice: cuda:0初始化 X 和 Y。 X 可以理解为特征矩阵,Y可以理解为样本标签。 结合代码可以看到,X的为一个 NxC 行, D 列的矩阵。C 类样本,每类样本是 N个,所以是 N*C 行。每个样本的特征维度是2,所以是 2列。
在 python 中,调用 zeros 类似的函数,第一个参数是 y方向的,即矩阵的行;第二个参数是 x方向的,即矩阵的列,大家得注意下,不要搞反了。下面结合代码看看 3000个样本的特征是如何初始化的。
X = torch.zeros(N * C, D).to(device)
Y = torch.zeros(N * C, dtype=torch.long).to(device)
for c in range(C): # 生成从 1 到 C 的数,即1 ~ 3,对每个类别进行一次循环
index = 0
t = torch.linspace(0, 1, N) # 在[0,1]间均匀的取10000个数,赋给t
# 下面的代码不用理解太多,总之是根据公式计算出三类样本(可以构成螺旋形)
# torch.randn(N) 是得到 N 个均值为0,方差为 1 的一组随机数,注意要和 rand 区分开, torch.rand是均匀分布;torch.randn是正态分布
inner_var = torch.linspace( (2*math.pi/C)*c, (2*math.pi/C)*(2+c), N) + torch.randn(N) * 0.2
# 每个样本的(x,y)坐标都保存在 X 里
# Y 里存储的是样本的类别,分别为 [0, 1, 2]
for ix in range(N * c, N * (c + 1)): # 1~1000;1001~2000;2001~3000
X[ix] = t[index] * torch.FloatTensor((math.sin(inner_var[index]), math.cos(inner_var[index])))
Y[ix] = c
index += 1
print("Shapes:")
print("X:", X.size()) # 3000行,2列
print("Y:", Y.size()) # 3000行Shapes:
X: torch.Size([3000, 2])
Y: torch.Size([3000])plot_data()打印图像,结果如下:# visualise the data
plot_data(X, Y) # 3个类别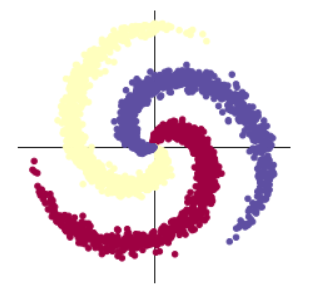
learning_rate = 1e-3 # 0.001
lambda_l2 = 1e-5 # 0.00001
# nn 包用来创建线性模型
# 每一个线性模型都包含 weight 和 bias
model = nn.Sequential(
nn.Linear(D, H), # 2维,每一维度100个隐层单元
nn.Linear(H, C) # 每一个维度有3个类别
)
model.to(device) # 把模型放到GPU上
# nn 包含多种不同的损失函数,这里使用的是交叉熵(cross entropy loss)损失函数
# 损失函数:网络输出和真实标签对的数据,然后返回一个数值表示网络输出和真实标签的差距。
criterion = torch.nn.CrossEntropyLoss()
# 这里使用 optim 包进行随机梯度下降(stochastic gradient descent)优化
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate, weight_decay=lambda_l2)
# 开始训练
for t in range(1000):
# 把数据输入模型,得到预测结果
y_pred = model(X)
# 计算损失和准确率
loss = criterion(y_pred, Y)
score, predicted = torch.max(y_pred, 1)
acc = (Y == predicted).sum().float() / len(Y)
print('[EPOCH]: %i, [LOSS]: %.6f, [ACCURACY]: %.3f' % (t, loss.item(), acc))
display.clear_output(wait=True)
# 反向传播前把梯度置 0
optimizer.zero_grad()
# 反向传播优化
loss.backward()
# 更新全部参数, 不断进行优化
optimizer.step()输出结果为:
[EPOCH]: 999, [LOSS]: 0.864019, [ACCURACY]: 0.500通过损失函数的输出值我们不难看出本次预测结果与真实标签的差距很大,本次预测的精确度只有 0.5。
为了更进一步解释代码,下面将第 10 行的情况输出,供解释说明:
print(y_pred.shape)
print(y_pred[10, :])
print(score[10])
print(predicted[10])输出结果为:
torch.Size([3000, 3])
tensor([-0.1566, -0.1720, -0.1466], device='cuda:0', grad_fn=<SliceBackward0>)
tensor(-0.1466, device='cuda:0', grad_fn=<SelectBackward0>)
tensor(2, device='cuda:0')使用 print(y_pred.shape) 可以看到模型的预测结果,为 [3000, 3] 的矩阵。每个样本的预测结果为 3 个,保存在 y_pred 的一行里。值最大的一个,即为预测该样本属于的类别。
score, predicted = torch.max(y_pred, 1) 是沿着第二个方向(即 X 方向)提取最大值。最大的那个值存在 score 中,所在的位置(即第几列的最大)保存在 predicted 中。
打印构建的线性模型分类:
# Plot trained model
print(model)
plot_model(X, Y, model)输出结果及生成图像如下:
Sequential(
(0): Linear(in_features=2, out_features=100, bias=True)
(1): Linear(in_features=100, out_features=3, bias=True)
)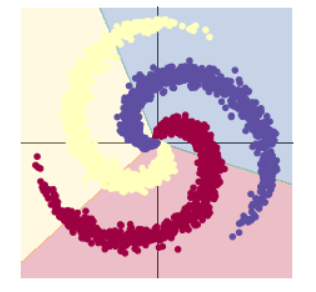
上面的 print(model)输出了两层模型:
- 第一层输入为 2(因为特征维度为主2),输出为 100;
- 第二层输入为 100 (上一层的输出),输出为 3(类别数);
通过上面输出图形我们可以得出:对一个不规则分布的模型使用线性模型来预测,很难实现准确分类。
下面将样本的类别修改为 5 再看线性模型分类预测的输出结果:
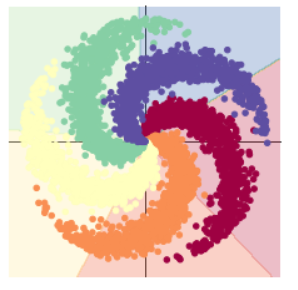
可以看到准确率不升反而降低了一点,这是因为图形变得更复杂,线性分类变得更难,更难以用直线去划分不同类别的区域。
使用带激活函数的两层神经网络分类
learning_rate = 1e-3
lambda_l2 = 1e-5
# 这里可以看到,和上面模型不同的是,在两层之间加入了一个 ReLU 激活函数
model = nn.Sequential(
nn.Linear(D, H),
# 只要不带激活函数,都只能解决线性可分的问题。解决不了我们的线性不可分问题。
# 不带激活函数的单层感知机是一个线性分类器,不能解决线性不可分的问题。
# 激活函数是用来加入非线性因素的,提高神经网络对模型的表达能力,解决线性模型所不能解决的问题。
nn.ReLU(),
nn.Linear(H, C)
)
model.to(device) # 把模型放到GPU上
# 下面的代码和之前是完全一样的,这里不过多叙述
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate, weight_decay=lambda_l2) # built-in L2
# 训练模型,和之前的代码是完全一样的
for t in range(1000):
y_pred = model(X)
loss = criterion(y_pred, Y)
score, predicted = torch.max(y_pred, 1)
acc = ((Y == predicted).sum().float() / len(Y))
print("[EPOCH]: %i, [LOSS]: %.6f, [ACCURACY]: %.3f" % (t, loss.item(), acc))
display.clear_output(wait=True)
# zero the gradients before running the backward pass.
optimizer.zero_grad()
# Backward pass to compute the gradient
loss.backward()
# Update params
optimizer.step()输出结果为:
[EPOCH]: 999, [LOSS]: 0.170588, [ACCURACY]: 0.953可以看到,通过加入一个激活函数,预测的准确率便直接上升到 0.953,这是一次巨大的飞跃。
将结果和图形输出:
# Plot trained model
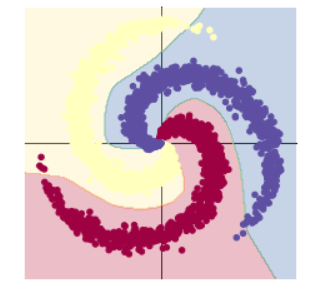
print(model)
plot_model(X, Y, model)Sequential(
(0): Linear(in_features=2, out_features=100, bias=True)
(1): ReLU()
(2): Linear(in_features=100, out_features=3, bias=True)
)
修改类别数为 5 后的输出结果以及生成的图像为:
[EPOCH]: 999, [LOSS]: 0.283555, [ACCURACY]: 0.933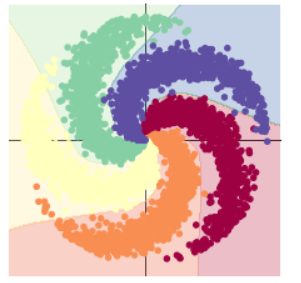
通过输出的两层模型,我们可以很直观地看出带激活函数的两层神经网络分类的准确率显著提升了。
对于上方的模型,使用线性分类我们不可能得到很高的准确率,但是通过使用激活函数,加入非线性的因素,提高神经网络对模型的表达能力,就可以很好地解决线性模型不能解决的问题。
4. 总结
1、AlexNet有哪些特点?为什么可以比LeNet取得更好的性能?
AlexNet 特点:
(1)AlexNet 没有摆脱 LetNet 的卷积、池化的一系列过程,Alex net在大结构上还是传承了 LetNet 的基本结构。
(2)AlexNet 采用了 ReLu 激活函数。
(3)AlexNet 在全链层采用了 DropOut 技术。
AlexNet 与 LeNet 相比的优点:
(1)AlexNet 网络包含 8 层,相比较于 LeNet 具有更多的层数,使得 AlexNet 可以处理较大批量数据。
(2)传统的 LeNet 网络使用的是 Sigmoid 激活函数,而 AlexNet 使用的是 ReLu 函数。
-
- ReLu代替了Sigmod函数对输入的非线性进行了优化,相比较Sigmod函数,Relu的计算成本更低。
- Tanh或者Sigmod在饱和区域容易产生梯度消失而减慢收敛速度,而ReLu不会。
- 由于ReLu函数的构造,可以把不明显的信号替换为0,增加矩阵的稀疏性,从而防止过拟合。
(3)AlexNet 在全链层采用了 DropOut 技术,在前向传播时,让某个神经元的激活值以一定的概率 p(0.5) 停止工作,使模型泛化性更强,不会太依赖于某些局部的特征。保证了在训练数据和测试数据的准确性。
2、激活函数有哪些作用?
3、梯度消失现象是什么?
在神经网络中,当前面隐藏层的学习速率低于后面隐藏层的学习速率,即随着隐藏层数目的增加,分类准确率反而下降了。
4、神经网络是更宽好还是更深好?
神经网络不是越深越好,也不是越宽越好。
(1)提升同样效果需要增加的宽度远远超过需要增加的深度;宽而浅的网络可能比较擅长记忆,却不擅长概括,即泛化能力差。
(2)多层的优势在于可以在不同的抽象层次上学习特征,并且随着层数的增加,每个神经元相对前一层的感受也变得越来越大,因而深层可以提供全局语义和抽象细节的信息,这是宽层很难做到的。
(3)深层网络相比于浅层网络在实际应用中体现出来的表达能力,从某个角度来看,平均意义上只随神经元数目线性增长,而和网络深度无关,有些研究指出,GPU 的并行处理使得加宽网络比加深网络更容易训练。
5、为什么要使用Softmax?
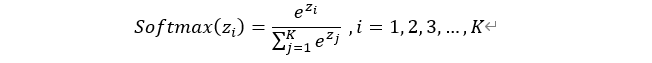
其中 zi 为第 i 个节点的输出值;K 为输出节点的个数,即分类的类别数,过 Softmax 函数就可以将多分类的输出值转换为范围在
[0, 1] 之间的并且和为 1 的概率分布。
Softmax 的含义在于不再唯一确定某一个最大值,而是为每个输出分类的结果都赋予一个概率值,表示属于每个类别的可能性。
使用递增的指数的形式,表示在 x 变化很小时,可以在 y 轴上有很明显的变化,可以将差距的数值距离拉的更大。
6、SGD 和 Adam 哪个更有效?
Adam 更有效:
经典的 SGD 没有用到动量的概念,这种优化函数收敛速度慢,可能会在鞍点处震荡。
Adam 集成了 SGD-M 的一阶动量以及 RMSprop 的二阶动量,做到了计算不同参数的自适应学习,可以说 Adam 是 SGD 升级。
Adam 适用于训练深层网络模型快速收敛或所构建神经网络较为复杂。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号