Java 容器在实际项目中的应用
前言:在java开发中我们离不开集合数组等,在java中有个专有名词:“容器” ,下面会结合Thinking in Java的知识和实际开发中业务场景讲述一下容器在Web项目中的用法。可结合图片代码了解Java中的容器
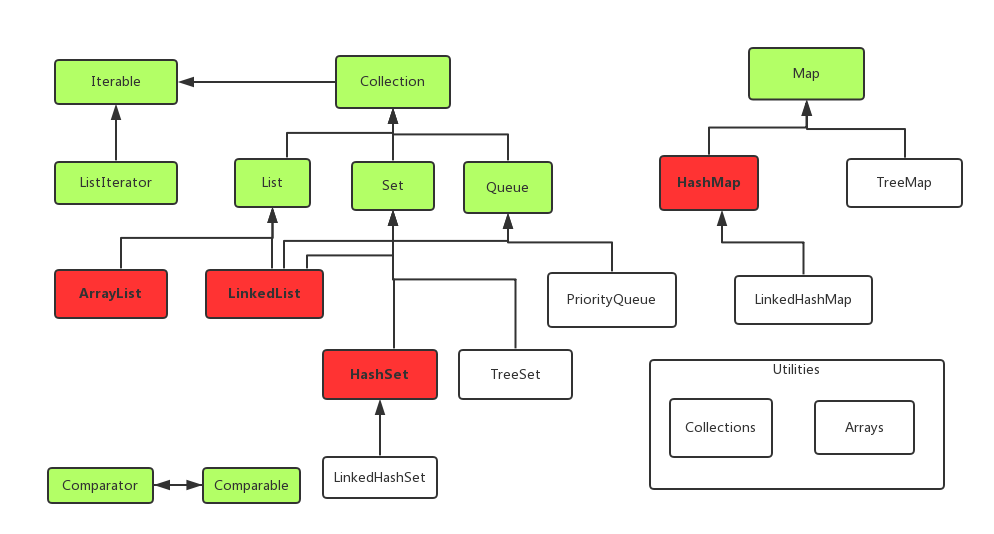
备注 :这个地方 ,参考于朝向远方的博客Java容器详解 ,既然前人总结的这么好,我就直接拿来用,在这里更注重在实际开发中的例子,感谢那些总结的前辈们,辛苦了。
简单的数组例子
Thinking in Java 中并没有把数组归为Java的容器,实际上数组的确不是Java独有的c++ ,c都有数组。但是,在web开发时我还是把数组归类到容器中,因为他们说白了都是在做相同的事情
另外还有一个细节点就是:我翻遍了我开发过的项目,但是很惊讶的发现,这么多项目里直接用数组存储对象极为少见。想想也是,java是面向对象的,而数组对java总归是有点偏底层。
珍惜这来之不易的demo吧:
public Map<String, String> getDimValue() {
if (this.dimValue != null)
return dimValue;
this.dimValue = new HashMap<String, String>();
if (this.dim != null && this.dim.length() != 0) {
String[] strDims = this.dim.split(",");//可以用截取的方式,得到String[]
for (String s : strDims) {
String[] dims = s.split("\\:");
this.dimValue.put(dims[0], dims[1]);//数组访问通过下标,但是注意 最多到array[array.length-1],越界直接抛出异常,和c++不一样
}
}
return this.dimValue;
}
数组(array)是最常见的数据结构。数组是相同类型元素的有序集合,并有固定的大小(可容纳固定数目的元素)。数组可以根据下标(index)来随机存取(random access)元素。在内存中,数组通常是一段连续的存储单元。
Java支持数组这一数据结构。我们需要说明每个数组的类型和大小,java利用byte[] 可以表示blob字段,存放图片,xml,json等。String[]则可以用来存一些字符串,id, code等。
//web项目中倒是常用 byte[]来存放blob字段等
@Type(type = "org.springframework.orm.hibernate3.support.BlobByteArrayType") private byte[] globals;
在说明类型时,在类型说明(String)后面增加一个[],来说明是一个数组。使用new创建容器时,需要说明数组的大小;或者是 直接 int a = {1,2,3} 这样直接用{}同时初始化。
数组可以通过遍历的形式转为其他容器类型,但是其他类型可以通过 toArray()快速转为数组(下文中会说到Arrays这个工具类可以把数组转为List)
第一个分支:Collection
在开发中,Collection最常用的就是两个类: Set和List。因为同属于一个Collection下,相互转化方便,调用的方法也类似。(collection Api)
Java中常用方法接口:
* boolean add(Object obj): 添加对象,集合发生变化则返回true
* Iterator iterator():返回Iterator接口的对象
* int size()
* boolean isEmpty()
* boolean contains(Object obj)
* void clear()
* <T> T[] toArray(T[] a)
上述接口参照于:wishyouhappy的博客:java容器总结。
1:List集合
具体可以查看list中文文档,文档中清楚的描述到List<E>是一个实现了 Collection的接口,而我们可以直接用List 声明对象(接口可以直接声明一个对象)。容器的引用为List类型,但容器的实现为ArrayList类。这里是将接口与实现类分离。事实上,同一种抽象数据结构(ADT)都可以有多种实施方法(比如栈可以实施为数组和链表)。这样的分离允许我们更自由的选择ADT的实施方式(参考于Java容器详解)
java中较为常用的 ArrayList,LinkedList, 集合中的元素可以相等,是有顺序的
1 public class Test {
2 public static void main(String[] args) {
3 List<String> list = new ArrayList<String>();
4 //添加单个元素
5 for(String s1:"hehe wo shi lao da".split(" ")){
6 list.add(s1);
7 }
8 //添加多个元素
9 list.addAll(Arrays.asList("nan dao ni bu xin?".split(" ")));//Arrays是一个工具类,可以帮助我们少些遍历代码
10 System.out.println(list.toString());//list重写了toString方法,输出list中每一个元素
11 //修改位置为i的元素
12 for(int i = 0; i<list.size();i++){
13 list.set(i, "u");
14 }
15 System.out.println(list.toString());
16 list.removeAll(Arrays.asList(new String[]{"u"}));//这个地方为了测试 我初始化了一个字符数组 new String[]{"u"}
17 System.out.println(list.toString());18
19 }
20 }
上边的代码只是为了说明 list的主要用途,实际上开发中可能用不到这么多,比较常用的也就
- add()方法加入新的元素
- get()方法可以获取容器中的元素,传递一个整数下标作为参数
- remove()方法可以删除容器中的元素,传递一个整数下标作为参数。(有另一个remove(),传递元素自身作为参数)
- size()方法用来返回容器中元素的总数。
- toString() 多用于调试代码是,查看list中的内容
- addAll() 添加一个相同类型的list
List中 还有一个实习类 LinkedList 比较常用,它可以用来做队列 的实现,也可以变相完成栈的工作。
主要方法有:
- get(int index):返回此列表中指定位置处的元素。
- getFirst():返回此列表的第一个元素。
- getLast():返回此列表的最后一个元素。
- indexOf(Object o):返回此列表中首次出现的指定元素的索引,如果此列表中不包含该元素,则返回 -1。
- lastIndexOf(Object o):返回此列表中最后出现的指定元素的索引,如果此列表中不包含该元素,则返回 -1。
- remove():获取并移除此列表的头(第一个元素)
- removeFirst():移除并返回此列表的第一个元素
- removeLast():移除并返回此列表的最后一个元素
ListedList采用的是链式存储。链式存储就会定一个节点Node。包括三部分前驱节点、后继节点以及data值。所以存储存储的时候他的物理地址不一定是连续的
具体内容可参照java提高篇(二二)---LinkedList 下面列出了linkedList的部分源码(不建议一开始就看)
 View Code
View Code2:Set集合
集合(set)也是元素的集合。集合中不允许有等值的元素,集合的元素没有顺序:
我们用Set多数时候是利用它的特性,没有重复的元素,例如:
2.1 HashSet:HashSet查询速度比较快,但是存储的元素是随机的并没有排序
public class Test
{
public static void main(String[] args)
{
Set<Integer> s1 = new HashSet<Integer>();
s1.add(4);
s1.add(5);
s1.add(4);
s1.remove(5);
System.out.println(s1);
System.out.println(s1.size());
}
}
我们可以用它去过滤重复数据,Set 可以轻松的转为List,因为构造方法传入参数是Collection<? extends E> c
1 Set<String> set = new HashSet<String>();
2 set.add("h");
3 set.add("h");
4 List<String> fromSets = new ArrayList<String>(set);
5 System.out.println(fromSets.toString());
6 Set<String> s1 = new HashSet<String>(fromSets);
7 System.out.println(s1.toString());
这个地方,非常有意思的是,HashSet中竟然持有的是HashMap,利用HashMap存取数据
public HashSet(Collection<? extends E> c) {
map = new HashMap<E,Object>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
HashSet只有add方法,没有get方法(这和list稍微不同)。但是HashSet 实现了Iterator<E> iterator()。可以通过Iterator遍历,具体可以查看Set中文文档
2.2:TreeSet
TreeSet是将元素存储红-黑树结构中,所以存储的结果是有顺序的
public static void main(String[] args){
Random random=new Random(47);
Set<Integer> intset=new TreeSet<Integer>();
for (int i=0;i<10000;i++){
intset.add(random.nextInt(30));
}
System.out.print(intset);
}
3:collection中的Iterator
Iterator的官方文档,一般Set想要取元素只能通过迭代器,而list也可以用迭代器(一般都是用get)
public class Test
{
public static void main(String[] args)
{
List<Integer> l1 = new ArrayList<Integer>();
l1.add(4);
l1.add(5);
l1.add(2);
Iterator i = l1.iterator();
while(i.hasNext()) {
System.out.println(i.next());
}
}
}
Collection可以用foreach,因为其实现了Iterator接口
public class IteratorClass {
public Iterator<String> iterator(){
return new Itr();
}
private class Itr implements Iterator<String>{
protected String[] words=("Hello Java").split(" ");
private int index=0;
public boolean hasNext() {
return index<words.length;
}
public String next() {
return words[index++];
}
public void remove() {
}
}
}
foreach循环最终也会转化为Iterator遍历 (Iterator it=iterator;iterators.hasNext();)
Iterator iterators=new IteratorClass().iterator();
for (Iterator it=iterator;iterators.hasNext();) {
System.out.println(iterators.next());
}
while (iterators.hasNext()){
System.out.println(iterators.next());
}
下面说一下Java中极容易出错的点:
for 循环查找集合中某个元素并删除:极容易出现java.util.ConcurrentModificationException
List<String> list = new ArrayList<String>();
list.addAll(Arrays.asList("nan dao ni bu xin?".split(" ")));
for(String st:list){
System.out.println(st);
if(st.equals("ni")){
list.remove(st);
}
}
解决方式是将数组转化为Iterator,然后利用it.remove();删除数组中的元素
public static void main(String[] args) {
List<String> list=new ArrayList<String>();
list.add("a");
list.add("bb");
list.add("a22");
Iterator<String> it=list.iterator();
//去除数组中"a"的元素
while(it.hasNext()){
String st=it.next();
if(st.equals("a")){
it.remove();
}
}
}
第二个分支:Map
在web项目中,Map是非常常用的,当然在很多时候,Map会被一些包装类给替代掉(这实际上是敏捷开发中提到用vo替换map).但是Map还是无法阻挡的容器一哥。
Java中常用的方法接口
* Object get(Object key)
* Object put(Object key, Object value)
* Set keySet() : returns the keys set Set<K> keySet()
* Set entrySet(): returns mappings set Set<Map.Entry<K,V>> entrySet()
* containsKey()
* containsValue()
Map是键值对的集合。Map中的每个元素是一个键值对,即一个键(key)和它对应的对象值(value)。对于Map容器,我们可以通过键来找到对应的对象。
哈希表是Map常见的一种实现方式,也是实际开发中用的最广泛的 (HashMap),想要具体了解HashMap的原理,可以参考 hashmap实现原理浅析
public class Test
{
public static void main(String[] args)
{
Map<String, Integer> m1 = new HashMap<String, Integer>();
m1.put("Vamei", 12);
m1.put("Jerry", 5);
m1.put("Tom", 18);
System.out.println(m1.get("Vamei"));
}
}
在Map中,我们使用put()方法来添加元素,用get()方法来获得元素。
Map还提供了下面的方法,来返回一个Collection:
- keySet() 将所有的键转换为Set
- values() 将所有的值转换为List
- containsKey验证主要是否存在、containsValue验证值是否存在
- entrySet获取键值对。
总结:
java中有一些工具类来帮助我们处理容器相关的内容。比如Arrays,java中的一些类都有用到这些工具类
ArrayList源码中的clone方法
/**
* Returns a shallow copy of this <tt>ArrayList</tt> instance. (The
* elements themselves are not copied.)
*
* @return a clone of this <tt>ArrayList</tt> instance
*/
public Object clone() {
try {
ArrayList<E> v = (ArrayList<E>) super.clone();
v.elementData = Arrays.copyOf(elementData, size);
v.modCount = 0;
return v;
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError();
}
}
ArrayList源码中的 toArray()方法
public Object[] toArray() {
return Arrays.copyOf(elementData, size);
}
如果你对Arrays这个工具类有兴趣,可以看一下源码,它最终调用到了本地方法(折叠起来,是不希望给读者带来困惑)
View CodeArrays的一些其他方法:
- sort(): 对传入的集合排序 (具体算法可以参考Java Arrays.sort源代码解析)
- aslist(): 把数组转为List
- binarySearch():二分查找数组
- deepToString():把二维数组转为String
- fill():快速填充数组
再比如Collections:
可以参考thinking in java之Collections工具类的使用
View Codemax():取集合的最大元素
subList():截取list
addAll():添加集合
有兴趣的可以去看一下源码,我觉得非常有帮助
作者:leader_Hoo
出处:http://www.cnblogs.com/ldh-better/
本文版权归作者和博客园共有,欢迎转载,唯一要求的就是请注明转载,此外,如果博客有帮助,希望可以帮忙点击推荐和分享,谢谢

 浙公网安备 33010602011771号
浙公网安备 33010602011771号