多表查询
表查询分为两大类
1.联表查询
2.子查询


#建表 create table dep( id int, name varchar(20) ); create table emp1( id int primary key auto_increment, name varchar(20), sex enum('male','female') not null default 'male', age int, dep_id int ); #插入数据 insert into dep values (200,'技术'), (201,'人力资源'), (202,'销售'), (203,'运营'); insert into emp(name,sex,age,dep_id) values ('jason','male',18,200), ('egon','female',48,201), ('kevin','male',38,201), ('nick','female',28,202), ('owen','male',18,200), ('jerry','female',18,204) ; # 当初为什么我们要分表,就是为了方便管理,在硬盘上确实是多张表,但是到了内存中我们应该把他们再拼成一张表进行查询才合理
select * from emp,dep; 产生的结果是一个笛卡尔积
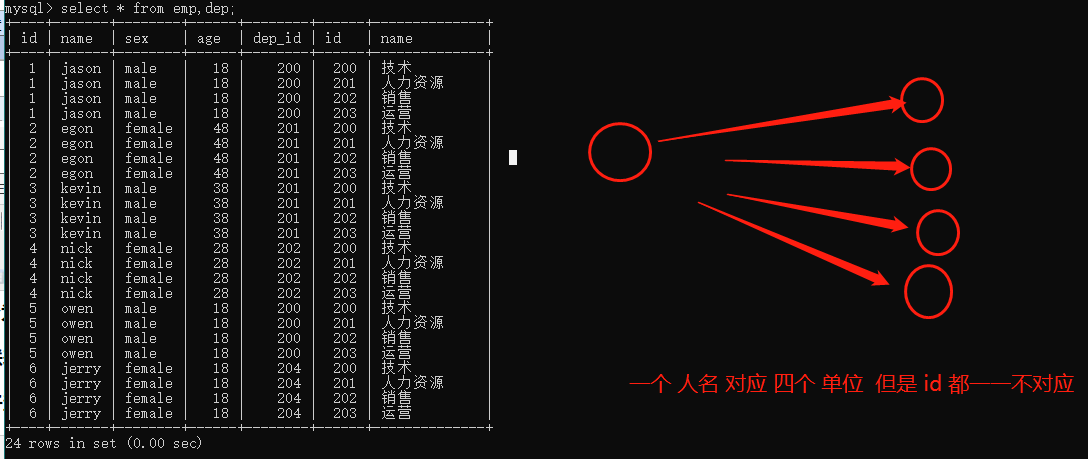
select * from emp,dep; # 左表一条记录与右表所有记录都对应一遍>>>笛卡尔积
将所有的数据都对应了一遍,虽然不合理但是其中有合理的数据,现在我们需要做的就是找出合理的数据
有专门帮你做连表的方法
内连接(inner join)
左连接(left join)
右连接(right join)
全连接(union) # 只要将左连接和右连接的sql语句 加一个union就变成全连接
# 1、内连接:只取两张表有对应关系的记录 select * from emp inner join dep on emp.dep_id = dep.id; select * from emp inner join dep on emp.dep_id = dep.id where dep.name = "技术"; # 2、左连接: 在内连接的基础上保留左表没有对应关系的记录 select * from emp left join dep on emp.dep_id = dep.id; # 3、右连接: 在内连接的基础上保留右表没有对应关系的记录 select * from emp right join dep on emp.dep_id = dep.id; # 4、全连接:在内连接的基础上保留左、右面表没有对应关系的的记录 select * from emp left join dep on emp.dep_id = dep.id union select * from emp right join dep on emp.dep_id = dep.id;
子查询
子查询 将一张表的查询结果作为另外一个sql语句的查询条件 select name from dep where id = (select dep_id from emp where name = 'jason');
# 就是将一个查询语句的结果用括号括起来当作另外一个查询语句的条件去用
# 1.查询部门是技术或者人力资源的员工信息
"""
先获取技术部和人力资源部的id号,再去员工表里面根据前面的id筛选出符合要求的员工信息
"""
select * from emp where dep_id in (select id from dep where name = "技术" or name = "人力资源");
# 2.每个部门最新入职的员工 # 思路:先查每个部门最新入职的员工,再按部门对应上联表查询 select t1.id,t1.name,t1.hire_date,t1.post,t2.* from emp as t1 inner join (select post,max(hire_date) as max_date from emp group by post) as t2 on t1.post = t2.post where t1.hire_date = t2.max_date ; # 可以给表起别名 # 可以给查询出来的虚拟表起别名 # 可以给字段起别名
趁自己还没死 多折腾折腾

 浙公网安备 33010602011771号
浙公网安备 33010602011771号