字符编码的了解以及简单的文件处理
一 计算机基础知识
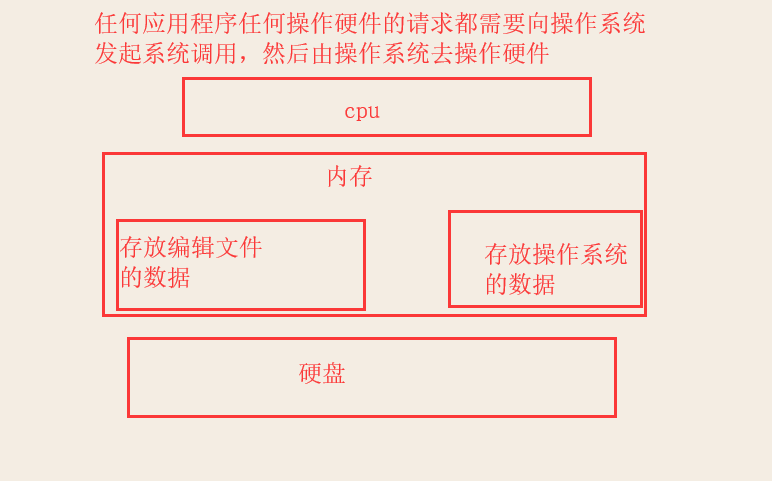
二 文本编辑器存取文件的原理
1、打开编辑器就打开了启动了一个进程,是在内存中的,所以,用编辑器编写的内容也都是存放与内存中的,断电后数据丢失 2、要想永久保存,需要点击保存按钮:编辑器把内存的数据刷到了硬盘上。 3、在我们编写一个py文件(没有执行),跟编写其他文件没有任何区别,都只是在编写一堆字符而已。
三 python解释器执行py文件的原理
第一阶段:python解释器启动,此时就相当于启动了一个文本编辑器 第二阶段:python解释器相当于文本编辑器,去打开test.py文件,从硬盘上将test.py的文件内容读入到内存中(小复习:pyhon的解释性,决定了解释器只关心文件内容,不关心文件后缀名) 第三阶段:python解释器解释执行刚刚加载到内存中test.py的代码( ps:在该阶段,即真正执行代码时,才会识别python的语法,执行文件内代码,当执行到name="egon"时,会开辟内存空间存放字符串"egon")
四 总结python解释器与文件本编辑的异同
相同点:python解释器是解释执行文件内容的,因而python解释器具备读py文件的功能,这一点与文本编辑器一样
不同点:文本编辑器将文件内容读入内存后,是为了显示或者编辑,根本不去理会python的语法,而python解释器将文件内容读入内存后,可不是为了给你瞅一眼python代码写的啥,而是为了执行python代码、会识别python语法。
字符编码
现在的计算机
内存都是unicode
硬盘都是utf-8
(需要掌握的)
unicode的两个特点
1.用户在输入的时候,无论输什么字符都能够兼容万国字符
2.其他国家编码的数据由硬盘读到内存的时候unicode与其他各个国家的编码都有对应关系
(必须掌握的)
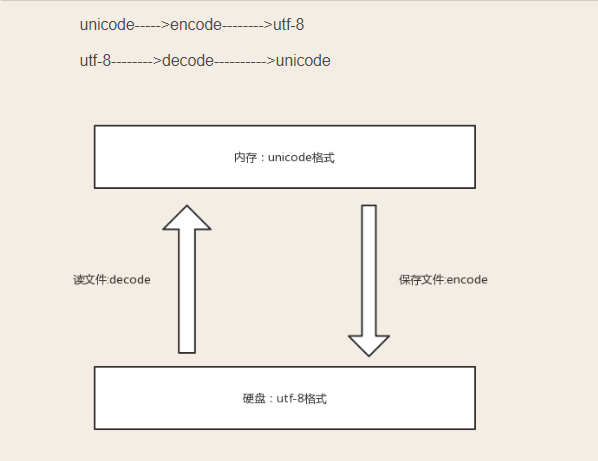
数据由内存保存到硬盘
1.内存中的unicode格式二进制数字 >>>>编码(encode)>>>>> utf-8格式的二进制数据
硬盘中的数据由硬盘读到内存
1.硬盘中的utf-8格式的二进制数据 >>>>>解码(decode)>>>>> 内存中unicode格式的二进制数据


字符编码针对的是文字 那也就意味着这里需要考虑 视频文件 音频文件等其他文件吗? 不需要 字符编码只跟文本文件有关 文本编辑器的输入和输出是两个过程 人在操作计算机的时候输入的是人能够看懂的字符 但是计算机只能识别010101这样的二进制数据,那么 输入的字符 >>>(字符编码表)>>> 二进制数字 字符编码表就是字符与数字的对应关系 a 0 b 1 a 00 b 01 c 11 d 10 ASCII码表 用八位二进制表示一个英文字符 所有的英文字符+符号最多也就在125位左右 0000 0000 1111 1111 GBK 用2Bytes表示一个中文字符 还是用1Bytes表示一个英文字符 0000 0000 0000 0000 1111 1111 1111 1111 最多能表示65535个字符 基于上面的推导步骤 任何一个国家要想让计算机支持本国语言都必须自己创建一个字符与数字的对应关系 日本人 shift 韩国人 fuck 万国码unicode 统一用2Bytes表示所有的字符 a 0000 0000 0010 1010 1.浪费存储空间 2.io次数增减,程序运行效率降低(致命) 当内存中的unicode编码格式数据存到硬盘的时候,会按照utf-8编码 unicode transformation format 会将unicode的英文字符由原来的2Bytes变成1Bytes 会将unicode中文字符由原来的2Bytes变成3Bytes
(******) 保证不乱码在于 文本文件以什么编码编的就以什么编码解 python2 将py文件按照文本文件读入解释器中默认使用ASCII码(因为在开发python2解释器的unicode还没有盛行) python3 将py文件按照文本文件读入解释器中默认使用utf-8 文件头 # coding:utf-8 1.因为所有的编码都支持英文字符,所以文件头才能够正常生效 基于Python解释器开发的软件,只要是中文,前面都需要加一个u 为了的就是讲python2(当你不指定文件头的时候,默认用ASCII存储数据,如果指定文件头那么就按照文件头的编码格式存储数据) python3中字符串默认就是unicode编码格式的二进制数 补充: 1.pycharm终端用的是utf-8格式 2.windows终端采用的是gbk
阶段一:现代计算机起源于美国,最早诞生也是基于英文考虑的ASCII ASCII:一个Bytes代表一个字符(英文字符/键盘上的所有其他字符),1Bytes=8bit,8bit可以表示0-2**8-1种变化,即可以表示256个字符 ASCII最初只用了后七位,127个数字,已经完全能够代表键盘上所有的字符了(英文字符/键盘的所有其他字符),后来为了将拉丁文也编码进了ASCII表,将最高位也占用了 #阶段二:为了满足中文和英文,中国人定制了GBK GBK:2Bytes代表一个中文字符,1Bytes表示一个英文字符 为了满足其他国家,各个国家纷纷定制了自己的编码 日本把日文编到Shift_JIS里,韩国把韩文编到Euc-kr里 #阶段三:各国有各国的标准,就会不可避免地出现冲突,结果就是,在多语言混合的文本中,显示出来会有乱码。如何解决这个问题呢??? #!!!!!!!!!!!!非常重要!!!!!!!!!!!! 说白了乱码问题的本质就是不统一,如果我们能统一全世界,规定全世界只能使用一种文字符号,然后统一使用一种编码,那么乱码问题将不复存在, ps:就像当年秦始皇统一中国一样,书同文车同轨,所有的麻烦事全部解决 很明显,上述的假设是不可能成立的。很多地方或老的系统、应用软件仍会采用各种各样的编码,这是历史遗留问题。于是我们必须找出一种解决方案或者说编码方案,需要同时满足: #1、能够兼容万国字符 #2、与全世界所有的字符编码都有映射关系,这样就可以转换成任意国家的字符编码 这就是unicode(定长), 统一用2Bytes代表一个字符, 虽然2**16-1=65535,但unicode却可以存放100w+个字符,因为unicode存放了与其他编码的映射关系,准确地说unicode并不是一种严格意义上的字符编码表,下载pdf来查看unicode的详情: 链接:https://pan.baidu.com/s/1dEV3RYp 很明显对于通篇都是英文的文本来说,unicode的式无疑是多了一倍的存储空间(二进制最终都是以电或者磁的方式存储到存储介质中的) 于是产生了UTF-8(可变长,全称Unicode Transformation Format),对英文字符只用1Bytes表示,对中文字符用3Bytes,对其他生僻字用更多的Bytes去存 #总结:内存中统一采用unicode,浪费空间来换取可以转换成任意编码(不乱码),硬盘可以采用各种编码,如utf-8,保证存放于硬盘或者基于网络传输的数据量很小,提高传输效率与稳定性。
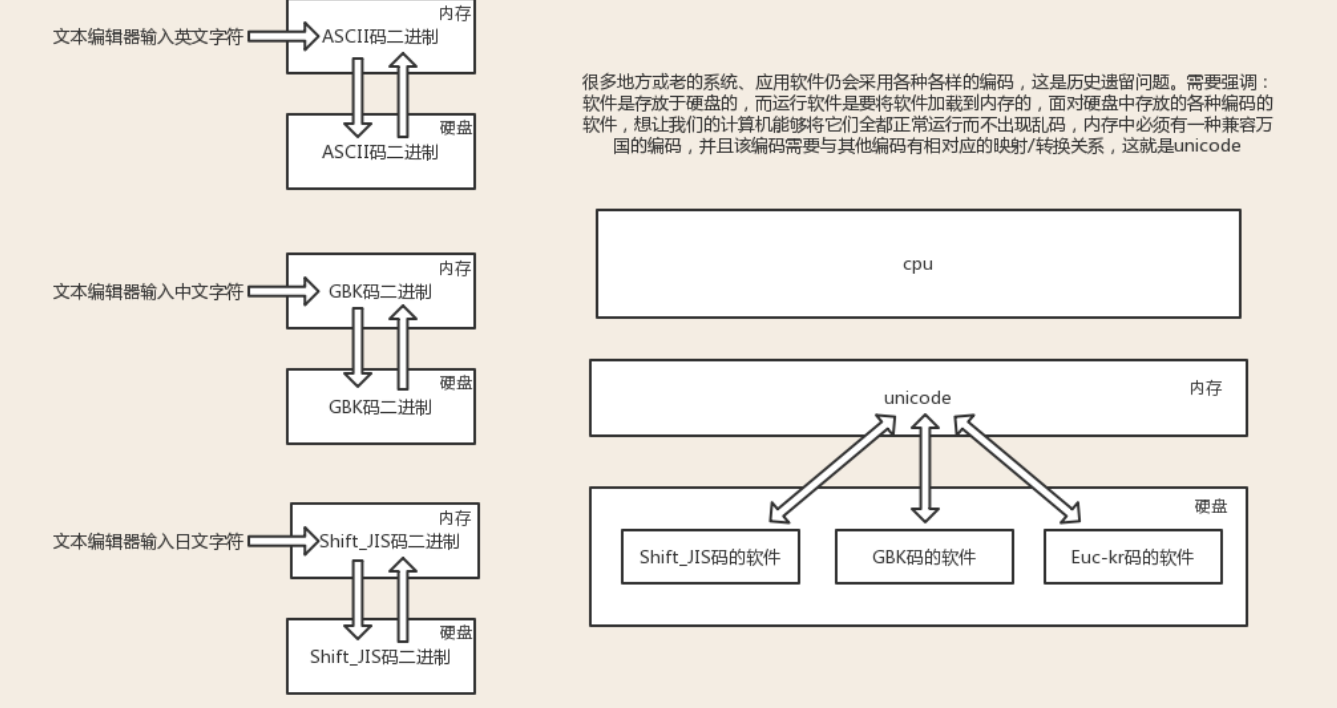
基于目前的现状,内存中的编码固定就是unicode,我们唯一可变的就是硬盘的上对应的字符编码。 此时你可能会觉得,那如果我们以后开发软时统一都用unicode编码,那么不就都统一了吗,关于统一这一点你的思路是没错的,但我们不可会使用unicode编码来编写程序的文件,因为在通篇都是英文的情况下,耗费的空间几乎会多出一倍,这样在软件读入内存或写入磁盘时,都会徒增IO次数,从而降低程序的执行效率。因而我们以后在编写程序的文件时应该统一使用一个更为精准的字符编码utf-8(用1Bytes存英文,3Bytes存中文),再次强调,内存中的编码固定使用unicode。 1、在存入磁盘时,需要将unicode转成一种更为精准的格式,utf-8:全称Unicode Transformation Format,将数据量控制到最精简 2、在读入内存时,需要将utf-8转成unicode 所以我们需要明确:内存中用unicode是为了兼容万国软件,即便是硬盘中有各国编码编写的软件,unicode也有相对应的映射关系,但在现在的开发中,程序员普遍使用utf-8编码了,估计在将来的某一天等所有老的软件都淘汰掉了情况下,就可以变成:内存utf-8<->硬盘utf-8的形式了。
!!!总结非常重要的两点!!!
1、保证不乱吗的核心法则就是,字符按照什么标准而编码的,就要按照什么标准解码,此处的标准指的就是字符编码 2、在内存中写的所有字符,一视同仁,都是unicode编码,比如我们打开编辑器,输入一个“你”,我们并不能说“你”就是一个汉字,此时它仅仅只是一个符号,该符号可能很多国家都在使用,根据我们使用的输入法不同这个字的样式可能也不太一样。只有在我们往硬盘保存或者基于网络传输时,才能确定”你“到底是一个汉字,还是一个日本字,这就是unicode转换成其他编码格式的过程了

文件的操作
""" 什么是文件? 操作系统提供给用户操作复杂硬件(硬盘)的简易的接口 为什么操作文件 人或者应用程序需要永久的保存数据 如何用 f = open() f.read() f.close() """ # 通过python代码操作文件 # r取消转义 # f = open(r'D:\Python项目\day07\a.txt',encoding='utf-8') # 向操作系统发送请求 打开某个文件 # # 应用程序要想操作计算机硬件 必须通过操作系统来简介的操作 print(f) # f是文件对象 print(f.read()) # windows操作系统默认的编码是gbk f.read() # 向操作系统发请求 读取文件内容 f.close() # 告诉操作系统 关闭打开的文件 print(f) print(f.read()) # 文件上下文操作 with open(r'D:\Python项目\day07\a.txt',encoding='utf-8') as f ,\ open(r'D:\Python项目\day07\b.txt',encoding='utf-8') as f1: #f仅仅是一个变量名 你把它看成是一个遥控器 print(f) print(f.read()) print(f1) print(f1.read())
""" 文件打开的模式 r 只读模式 w 只写模式 a 追加写模式 操作文件单位的方式 t 文本文件 t在使用的时候需要指定encoding参数 如果不知道默认是操作系统的默认编码 b 二进制 一定不能指定encoding参数 """ # mode参数 可以不写 不写的话默认是rt 只读的文本文件 这个t不写默认就是t with open(r'D:\Python项目\day07\a.txt',mode='r',encoding='utf-8') as f: print(f.readable()) # 是否可读 print(f.writable()) # 是否可写 print(f.read()) # 一次性将文件内容全部读出 with open(r'D:\Python项目\day07\1.jpeg',mode='rb') as f: print(f.readable()) # 是否可读 print(f.writable()) # 是否可写 print(f.read()) # 一次性将文件内容全部读出 # r模式在打开文件的时候 如果文件不存在 直接报错 # 文件路径可以写相对路径 但是需要注意该文件必须与执行文件在同一层文件下 with open(r'a.txt',mode='r',encoding='utf-8') as f: with open(r'a.txt','r',encoding='utf-8') as f1: mode关键字可以不写 print(f.readable()) # 是否可读 print(f.writable()) # 是否可写 print(">>>1:") print(f.read()) # 一次性将文件内容全部读出 print('>>>2:') print(f.read()) # 读完一次之后 文件的光标已经在文件末尾了,再读就没有内容了可读 print(f.readlines()) # 返回的是一个列表 列表中的一个个元素对应的就是文件的一行行内容 for line in f: # f可以被for循环 每for循环依次 读一行内容 print(i) # 这个方法 就可以解决大文件一次性读取占用内存过高的问题 print(f.readline()) # 只读取文件一行内容 print(f.readline()) print(f.readline()) print(f.readline()) # w模式:w模式一定要慎用 # 1.文件不存在的情况下 自动创建该文件 # 2.当文件存在的情况下 会先清空文件内容再写入 with open(r'xxx.txt',mode='w',encoding='utf-8') as f: print(f.readable()) # 是否可读 print(f.writable()) # 是否可写 f.write('不不不,你没有翻~\n') f.write('不不不,你没有翻~\n') f.write('不不不,你没有翻~\n') f.write('不不不,你没有翻~\r') f.write('不不不,你没有翻~') l = ['不sdffs,sdfs有翻~\n','不sdfsdf不,你sdfsf翻~\n','不sfad不,你没sa翻~\n'] f.writelines(l) # 上下等价 for i in l: f.write(i) # a模式 # 1.当文件不存在的情况下 自动创建该文件 # 2.当文件存在的情况下,不清空文件内容, 文件的光标会移动文件的最后 # with open(r'yyy.txt',mode='a',encoding='utf-8') as f: # print(f.readable()) # 是否可读 # print(f.writable()) # 是否可写 # f.write('我是小尾巴\n')
趁自己还没死 多折腾折腾

 浙公网安备 33010602011771号
浙公网安备 33010602011771号