
一、UDP代码编写
# 服务端 import socket udp_sk=socket.socket(type=socket.SOCK_DGRAM) # UDP协议 udp_sk.bind(('127.0.0.1',9000)) # 绑定地址 msg,addr=udp_sk.recvfrom(1024) udp_sk.sendto(b'hi',addr) udp_sk.close() # 客户端 import socket ip_port=('127.0.0.1',9000) udp_sk=socket.socket(type=socket.SOCK_DGRAM) udp_sk.sendto(b'hello',ip_port) back_msg,addr=udp_sk.recvfrom(1024) print(back_msg.decode('utf-8'),addr) """ 时间服务的实现原理 1.内部小电容供电 2.远程时间同步 """
二、操作系统的发展史
1.穿孔卡片时代
CPU的利用率极低
2.联机批处理系统
将多个程序员的程序一次性录入磁带中,之后交由输入机输入并由CPU执行
3.脱机批处理系统
现代计算机的雏形(远程输入,高速磁带,主机)
·多道技术
# 前提:针对单核CPU,实现并发 切换+保存 """ CPU工作机制 1.当某个程序进入IO状态的时候,操作系统会自动剥夺该程序的CPU执行权限 2.当某个程序长时间占用CPU的时候,操作系统也会剥夺该程序的CPU执行权限 """ 并发与并行 无论是并行还是并发,在用户看来都是‘同时’运行的,不管是进程还是线程,都只是一个任务而已,真正干活的是cpu,cpu来做这些任务,而一个cpu同一时刻只能执行一个任务 并发:是伪并行,即看起来是同时运行。单个cpu+多道技术就可以实现并发,(并行也属于并发) 并行:多个程序同时运行,只有具备多个cpu才能实现并行 # 问:单核cpu能否实现并行 肯定不能,但是可以实现并发 # 问:12306可以同一时间支持几个亿的用户买票,问是并行还是并发 肯定是并发(高并发) 星轨:微博能够支持八个星轨

三、进程理论
# 进程与程序的区别 程序仅仅只是一堆代码而已,而进程指的是程序的运行过程 # 单核情况下的进程调度 进程调度算法演变 1.FCFS 先来先服务 对短作业不友好 2.短作业优先调度算法 对长作业不友好 3.时间片轮转法+多级反馈队列 先分配给新的多个进程相同的时间片,之后根据进程消耗的时间片多少分类别
# 进程三状态图 就绪态 运行态 阻塞态 进程要想进入运行态必须先经过就绪态
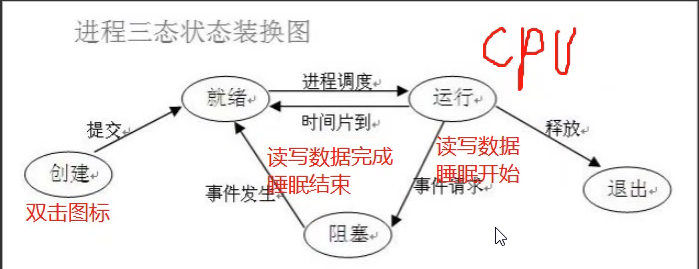
# 同步与异步 “”“用于描述任务的提交方式”“” 同步:提交完任务之后原地等待任务的返回结果,期间不做任何事 异步:提交完任务之后不原地等待任务的返回结果,直接去做其它事,结果由反馈机制自动提醒(异步回调机制)
# 阻塞与非阻塞 “”“用于描述任务的执行状态”“” 阻塞:阻塞态 非阻塞:就绪态 运行态

四、创建进程
# multiprocessing模块:用来开启子进程,并在子进程中执行我们定制的任务(比如函数) # Process类:创建进程的类,由该类实例化得到的对象,表示一个子进程中的任务(尚未启动) # args指定的为传给target函数的位置参数,是一个元祖形式,必须有逗号 ''' 参数: target表示调用对象,即子进程要执行的任务 args表示调用对象的位置参数元祖,args=('jason',) p.start():启动进程 ''' # 注意:在windows中Process()必须放到if __name__ == '__main__':下 # 开启子进程方法一 from multiprocessing import Process import time import os def test(name): print(os.getpid()) # 获取进程号 print(os.getppid()) # 获取父进程号 print('%s正在运行' % name) time.sleep(2) print('%s已经结束' % name) if __name__ == '__main__': p1=Process(target=test,args=('jason',)) # 生成一个进程对象 p2=Process(target=test,args=('alex',)) p1.start() # 启动一个进程 异步提交 p2.start() # print(os.getpid()) print('主进程') # 开启子进程方法二 from multiprocessing import Process import time class MyProcess(Process): def __init__(self,name): super().__init__() # 调用父类的方法 self.name=name def run(self): print('%s正在运行' % self.name) time.sleep(2) print('%s已经结束' % self.name) if __name__ == '__main__': p=MyProcess('jason') p.start() print('主进程')
·进程的join方法
# Process对象的join方法:主进程等,等待子进程结束 from multiprocessing import Process import time def test(name,n): print('%s is running' % name) time.sleep(n) print('%s is over' % name) if __name__ == '__main__': p_list=[] start_time=time.time() for i in range(1,4): p=Process(target=test,args=(i,i)) p.start() p_list.append(p) # p.join() # 串行 for p in p_list: p.join() print(time.time()-start_time) print('主进程') ''' join是让主线程等,而p1-p3仍然是并发执行的,p1.join的时候,其余p2,p3仍然在运行 等p1.join结束,可能p2,p3早已经结束了,这样p2.join,p3.join直接通过检查,无需等待 所以3个join花费的总时间仍然是耗费时间最长的那个进程运行的时间 '''
·进程间默认无法交互
# 进程间数据是相互隔离的 from multiprocessing import Process money=100 def test(): global money money=999 if __name__ == '__main__': p=Process(target=test) p.start() # 先确保子进程运行完毕了,再打印 p.join() print(money)
·对象方法
''' 1.current_process查看进程号 2.os.getpid()查看进程号 os.getppid()查看父进程进程号 3.进程的名字,p.name直接默认就有,也可以在实例化进程对象的时候通过关键字形式传入name=’‘ 4.p.terminate()杀死子进程 5.p.is_alive()判断进程是否存活 4,5结合看不出结果,因为操作系统需要反应时间,主进程睡0.1秒即可看出效果 ''' from multiprocessing import Process import time def test(name,n): print('%s is running' % name) time.sleep(n) print('%s is over' % name) if __name__ == '__main__': p=Process(target=test,args=('jason',3)) p.start() p.terminate() # 杀死子进程 time.sleep(0.1) print(p.is_alive()) # 判断当前进程是否存活 print('主进程') # False # 主进程

 浙公网安备 33010602011771号
浙公网安备 33010602011771号