8_波士顿房价(93预测率)
之前做过一期房价预测的机器学习,但当时不知道如何处理字符串数据,同时对数据预处理理解不深,导致最后不了了之。现在学习了哑变量以及数据清洗,再次做这个
题目时发现挺简单的,同时我也总结一套预测套路。
导入数据集
import pandas as pd train=pd.read_csv('train.csv',index_col=0) test=pd.read_csv('test.csv',index_col=0) sub=pd.read_csv('sub.csv',index_col=0) test['SalePrice']=sub['SalePrice']
首先导入三个数据集,index_col=0表示将数据集第一列作为索引,如果数据集自带索引可以使用此属性。测试集中的data和target是分开的,这里我们将测试集里特征和结果放在一个表里。
接下来查看缺失率
# %% # Numeric features train_number_tz = train.iloc[:,0:-1].dtypes[train.dtypes != "object"].index # Categorical features train_str_tz = train.iloc[:,0:-1].dtypes[train.iloc[:,0:-1].dtypes == "object"].index # 这里的data只包含特征数据 miss = 100 * train.loc[:, train_number_tz].isnull().mean() train_num_rank=miss[miss.values > 0].sort_values(ascending=False) miss = 100 * train.loc[:, train_str_tz].isnull().mean() train_str_rank=miss[miss.values > 0].sort_values(ascending=False)
# Numeric features test_number_tz = test.iloc[:,0:-1].dtypes[test.dtypes != "object"].index # Categorical features test_str_tz = test.iloc[:,0:-1].dtypes[test.iloc[:,0:-1].dtypes == "object"].index # 这里的test只包含特征数据 miss = 100 * test.loc[:, test_number_tz].isnull().mean() test_num_rank=miss[miss.values > 0].sort_values(ascending=False) miss = 100 * test.loc[:, test_str_tz].isnull().mean() test_str_rank=miss[miss.values > 0].sort_values(ascending=False)
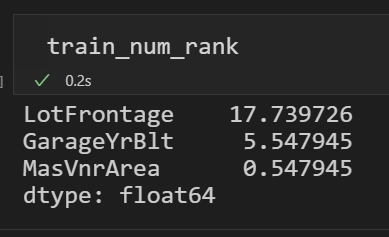
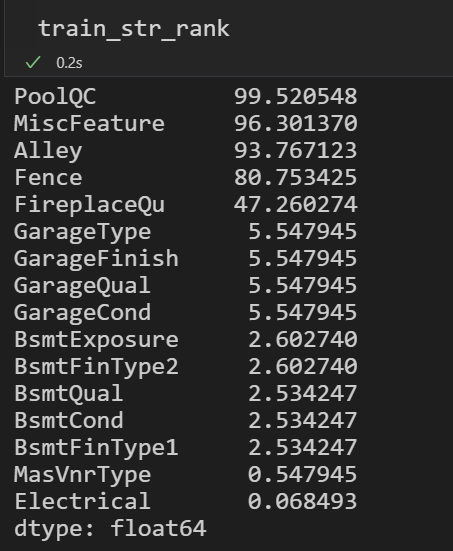
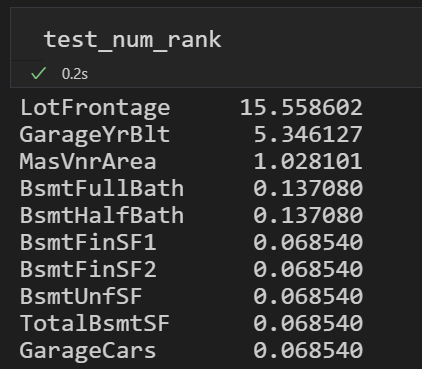

 浙公网安备 33010602011771号
浙公网安备 33010602011771号