


浅谈Java多线程之内存可见性
目录
学习目标:

可见性介绍:







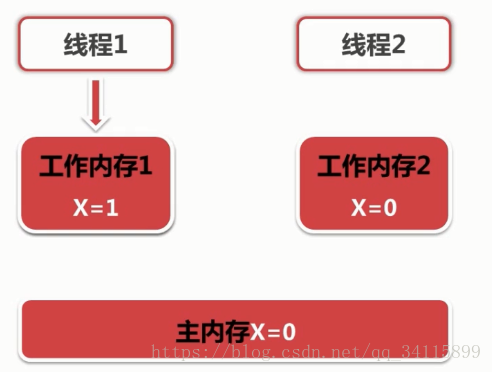


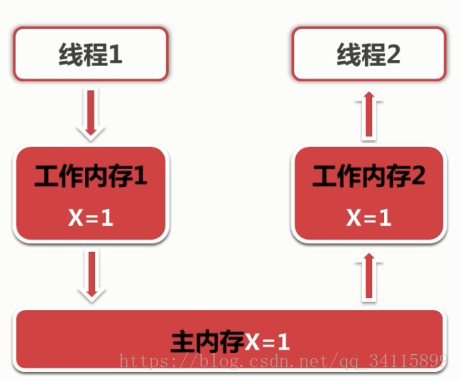
synchronized实现可见性原理:






优化之后更加符合处理器的特点


synchronized实现可见性代码:
先附上代码:
public class SynchronizedDemo {
//共享变量
private boolean ready = false;
private int result = 0;
private int number = 1;
//写操作
public void write(){
ready = true; //1.1
number = 2; //1.2
}
//读操作
public void read(){
if(ready){ //2.1
result = number*3; //2.2
}
System.out.println("result的值为:" + result);
}
//内部线程类
private class ReadWriteThread extends Thread {
//根据构造方法中传入的flag参数,确定线程执行读操作还是写操作
private boolean flag;
public ReadWriteThread(boolean flag){
this.flag = flag;
}
@Override
public void run() {
if(flag){
//构造方法中传入true,执行写操作
write();
}else{
//构造方法中传入false,执行读操作
read();
}
}
}
public static void main(String[] args) {
SynchronizedDemo synDemo = new SynchronizedDemo();
//启动线程执行写操作
synDemo .new ReadWriteThread(true).start();
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
//启动线程执行读操作
synDemo.new ReadWriteThread(false).start();
}
}
为什么共享变量可以不加static?
只要是对同一个对象的操作,多线程访问共享变量是不需要加static的。
这里是同一个外部类对象,然后外部类对象里面有2个内部类对象,相当于main里面的操作导致异步调用了read和write方法,这2个方法是都可以直接获取成员变量的。
同理:如果实现了runnable接口的对象,new了多个Thread,但是传入的是同一个实现了runnable接口的对象,那么共享变量是不需要加static的。
如果class piao extends Thread{
private static int count = 10; // 如果这里不加static,那么这个变量就是各个线程独有的,不会共享
public void run() {
.........
if (count > 0) {
count--;
System.out.println(Thread.currentThread().getName() + "卖出一张票,票还剩" + count);
}
}
...}
main方法里面{
// 这里不是同一个对象,是多个对象
Thread t1 = new piao();
Thread t2 = new piao();
Thread t3 = new piao();
t1.start();
t2.start();
t3.start();
}



2.1和2.2也是可以重排序的,虽然存在控制依赖关系,但是不存在数据依赖关系,只有存在数据依赖关系才不能重排序。这样执行结果有多种,就不一一列举了。


内存可见了,怎么还会执行结果不一致呢?保证了内存可见性并不能保证执行结果一致。这里read()操作和write()操作加了synchronized是原子性的,但是又不保证read()和write()哪个先执行,所以会出现2个结果,如果是先read()执行,那么result就是0,如果write()先执行,那么result就是6。最后通过延时保证write()先执行,结果就是只有6。

加了synchronized,能够保证在主内存和工作内存及时的更新,保证了内存的可见性,但是不加synchronized,也可能内存可见,即工作内存和主内存的值能够更新,但是不能够保证,只是可能,因为编译器采取了优化,可能导致更新不及时。
volatile实现可见性:




volatile不能保证原子性:




使用ReentrantLock同步
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
public class VolatileDemo {
private Lock lock = new ReentrantLock();
private int number = 0;
public int getNumber(){
return this.number;
}
public void increase(){
try {
Thread.sleep(100);
} catch (InterruptedException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
lock.lock();
try {
this.number++;
} finally {
lock.unlock();
}
}
/**
* @param args
*/
public static void main(String[] args) {
// TODO Auto-generated method stub
final VolatileDemo volDemo = new VolatileDemo();
for(int i = 0 ; i < 500 ; i++){
new Thread(new Runnable() {
@Override
public void run() {
volDemo.increase();
}
}).start();
}
//如果还有子线程在运行,主线程就让出CPU资源,
//直到所有的子线程都运行完了,主线程再继续往下执行
while(Thread.activeCount() > 1){
Thread.yield();
}
System.out.println("number : " + volDemo.getNumber());
}
}



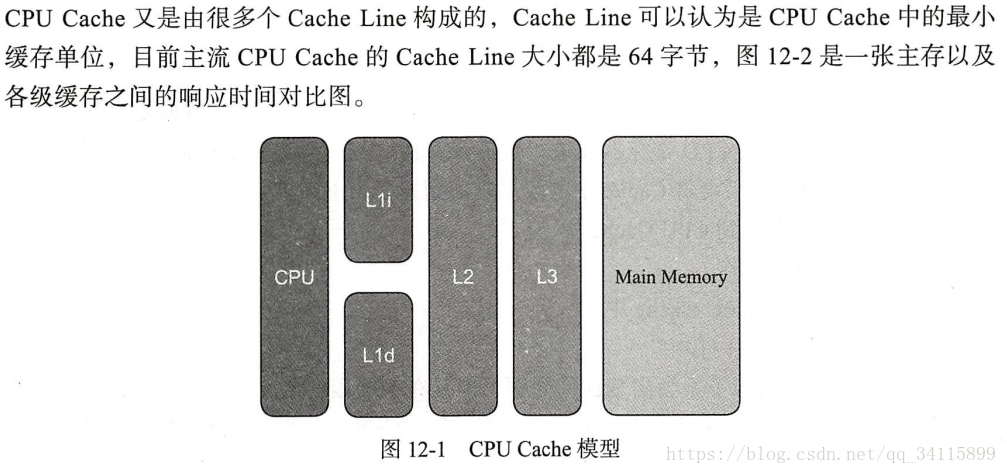
再谈谈CPU:
CPU的Cache模型:



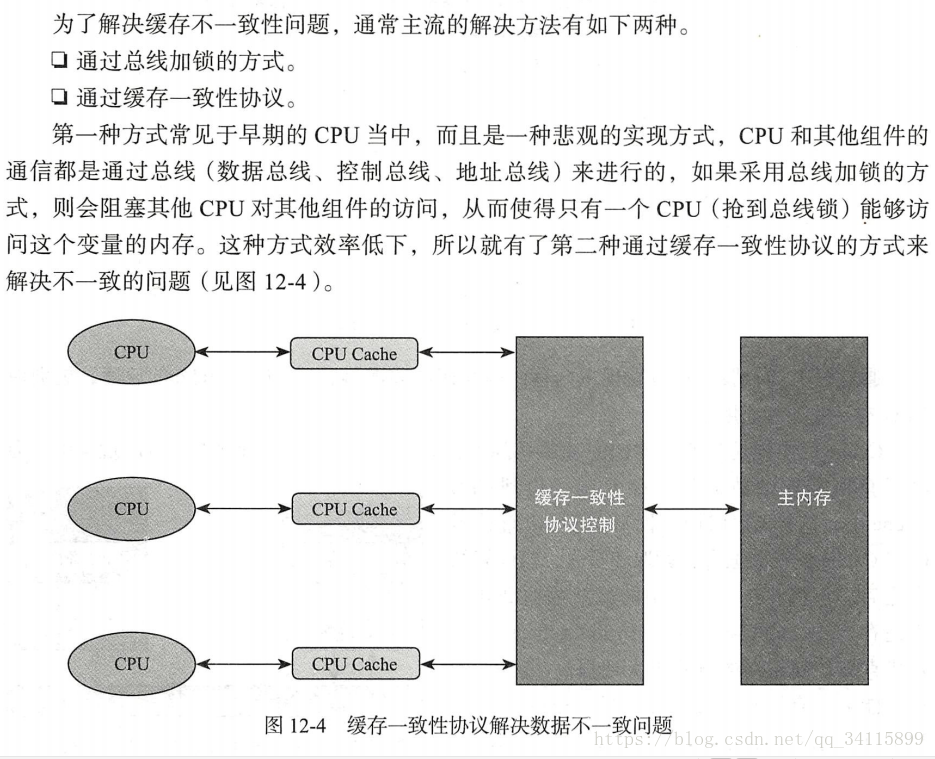
CPU缓存一致性问题:


关于内存屏障:
为了实现volatile内存语义,JMM会分别限制编译器重排序和处理器重排序

1.当第一个操作为普通的读或写时,如果第二个操作为volatile写,则编译器不能重排序这两个操作(1,3)
2.当第一个操作是volatile读时,不管第二个操作是什么,都不能重排序。这个规则确保volatile读之后的操作不会被编译器重排序到volatile读之前(第二行)
3.当第一个操作是volatile写,第二个操作是volatile读时,不能重排序(3,2)
4.当第二个操作是volatile写时,不管第一个操作是什么,都不能重排序(第三列)
内存屏障(Memory Barrier,或有时叫做内存栅栏,Memory Fence)是一种CPU指令,用于控制特定条件下的重排序和内存可见性问题。Java编译器也会根据内存屏障的规则禁止重排序。
内存屏障可以被分为以下几种类型
LoadLoad屏障:对于这样的语句Load1; LoadLoad; Load2,在Load2及后续读取操作要读取的数据被访问前,保证Load1要读取的数据被读取完毕。
StoreStore屏障:对于这样的语句Store1; StoreStore; Store2,在Store2及后续写入操作执行前,保证Store1的写入操作对其它处理器可见。
LoadStore屏障:对于这样的语句Load1; LoadStore; Store2,在Store2及后续写入操作被刷出前,保证Load1要读取的数据被读取完毕。
StoreLoad屏障:对于这样的语句Store1; StoreLoad; Load2,在Load2及后续所有读取操作执行前,保证Store1的写入对所有处理器可见。它的开销是四种屏障中最大的。 在大多数处理器的实现中,这个屏障是个万能屏障,兼具其它三种内存屏障的功能。
有的处理器的重排序规则较严,无需内存屏障也能很好的工作,Java编译器会在这种情况下不放置内存屏障。
为了实现JSR-133的规定,Java编译器会这样使用内存屏障。

为了保证final字段的特殊语义,也会在下面的语句加入内存屏障。
x.finalField = v; StoreStore; sharedRef = x;
那么什么才是volatile读,volatile写呢?什么是普通读写呢?
比如int a = 10; // 普通写
int b = a; // 先把a从工作内存读取出来(普通读),接着再写到b里去(普通写)
volatile int c = 20; // 属于volatile写
volatile int d = c; // volatile读去主存中去读取c的值,同时更新工作内存中的c值,接着再volatile写,写到d中,再将d的值刷到主存
int e = d; // volatile读去主存读取d的值,同时更新工作内存的d值,然后接着普通写,写到e中
volatile int f = e; // 先普通读e的值,接着再volatile写,写到f中,再将f的值立即刷到主存
注意:赋值是写操作,普通读就是从工作内存读,volatile读就是从主存读。
从上面例子看出,因为第一步普通读写和第二步volatile读不冲突(不会发生在一行赋值语句),所以可以重排序,也不需要屏障。
比如if (e == f){...} e是普通读,f是volatile读,可以重排序,最后判断值是否相等。
第一步volatile写(比如volatile int a = 10)和第二步普通读写不冲突,所以可以重排序,不需要屏障。
==================================================
为了实现volatile的内存语义,编译器在生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。
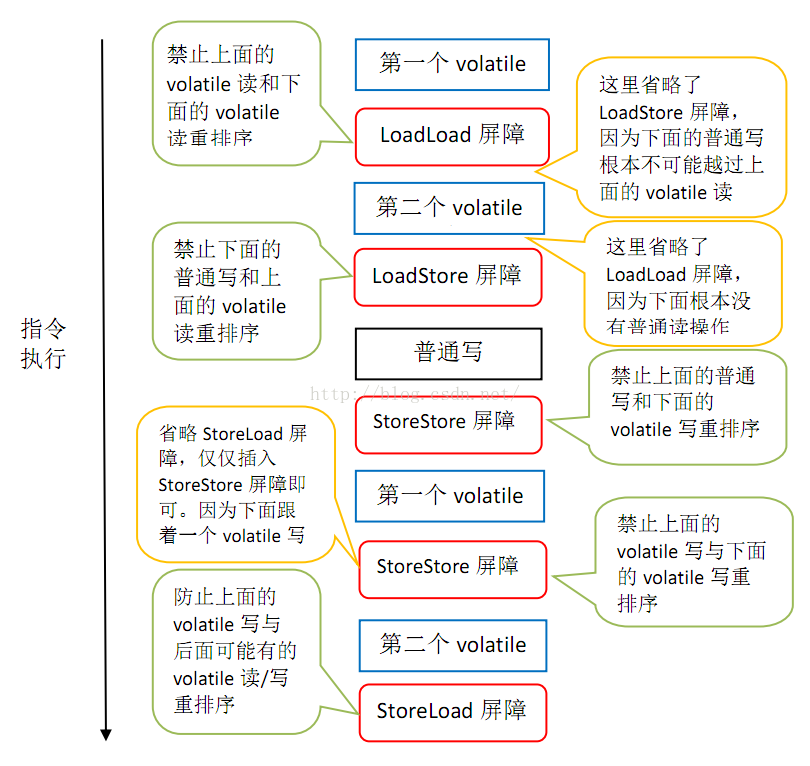
JMM基于保守策略的JMM内存屏障插入策略:
1.在每个volatile写操作的前面插入一个StoreStore屏障
2.在每个volatile写操作的后面插入一个SotreLoad屏障
3.在每个volatile读操作的后面插入一个LoadLoad屏障
4.在每个volatile读操作的后面插入一个LoadStore屏障

上图的StoreStore屏障可以保证在volatile写之前,其前面的所有普通写操作已经对任意处理器可见了
因为StoreStore屏障将保障上面所有的普通写在volatile写之前刷新到主内存

x86处理器仅仅会对写-读操作做重排序
因此会省略掉读-读、读-写和写-写操作做重排序的内存屏障
在x86中,JMM仅需在volatile后面插入一个StoreLoad屏障即可正确实现volatile写-读的内存语义
这意味着在x86处理器中,volatile写的开销比volatile读的大,因为StoreLoad屏障开销比较大


========================Talk is cheap, show me the code=======================

