
MongoDB的安装与基本使用
一.MongoDB的安装
在Linux的Ubuntu上安装:
1. 第一步,使用命令自动安装:
sudo apt-get install -y mongodb-org=”版本号“
#其中 -y 是只默认 yes2. 第二步,查看配置文件:
先查看配置文件 /etc/mongood.conf
其中描述了mongodb的数据存储路径、日志存储路径、以及mongod服务的端口号
可以使用Ubuntu命令查询:
cat /etc//mongodb.conf
mongod -version #查看mongodb的版本号3. 第三步,创建相应的目录:
在 / 的路径下建立mongodb的文件夹
cd /
mkdir -p mongodb/data #其中 -p 是递归的创建文件夹创建mongodb日志所在的文件夹log及log的日志文件mongodb.db
mkdir -p mongodb/log
touch mongodb/log/mongodb.log4.第四步,启动mongodb服务:
mongod --dbpath /mongodb/data --logpath /mongodb/log/mongodb.log --logappend&--dbpath: 对应上面设置的数据库文件所在的目录data
--logappend: 日志以追加的形式添加log文件中,如果不设置,则日志以覆盖的形式。
&:此符号表示将mongod进程后台进行
通过pgrep命令查看mongod是否已经成功启动:
pgrep mongo -l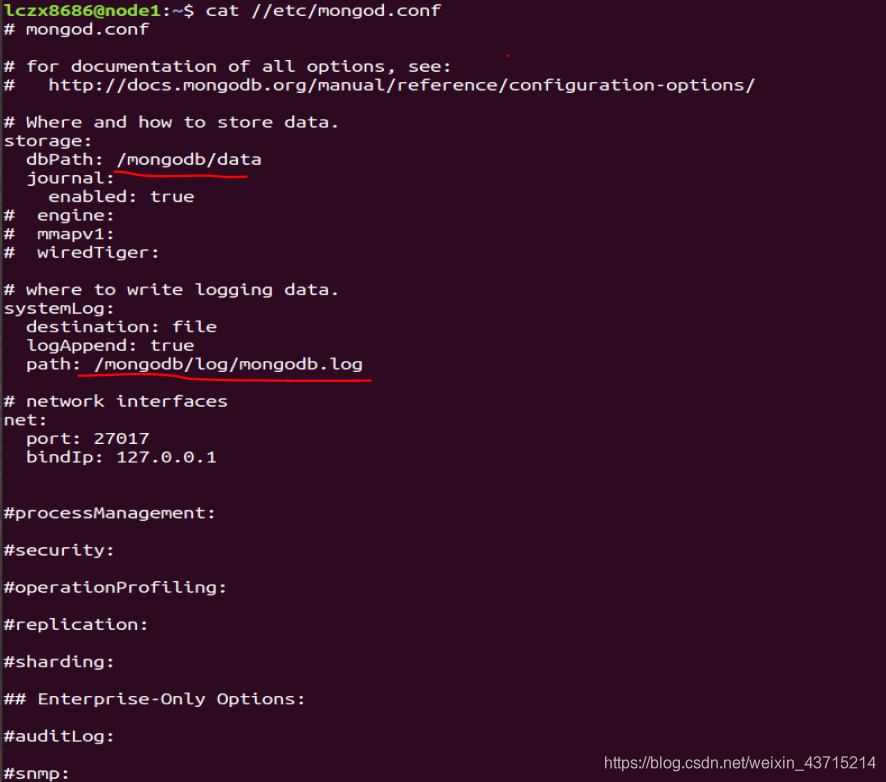
注意:上述图片中的dbpath与path要与刚刚新建的文件目录相对应!!!
二.MongoDB的简单的增删改查
查看所有数据库:
show dbs;
或者
show databases;使用XXX数据库:
use db_name;删除XXX数据库:
db.dropDatabase(); #先要use一下XXX数据库,然后再使用这一条命令删除注意:
MongoDB中,不需要像MySQL一样使用create来创建数据库,只需要使用 ”use + 数据库名“ 命令使用XXX数据库,
然后只要使用 插入/添加集合 数据库就会被自动创建!
在MongoDB中没有”表“这个概念!(表 => 集合)
手动创建一个集合:
db.createCollection(name,option);
--name 数据库名
--option 可选属性样例:
db.createCollection("stu01"); #创建一个名为stu01的集合
db.createCollection("stu02",{capped:true,size:10});
--capped : 默认为false,若为true表示集合大小有上限!
--size : 当capped为 true 时需要指定size,size为集合的大小,单位为字节,若达到设定的大小的时候,则以队列的形式向前覆盖信息。查看集合:
show collections;
例如:
show stu01;删除集合:
db.集合名称.drop();MongoDB常用的数据类型:

1.插入数据:
db.集合名称.insert(document);以“stu01”为例:
db.stu01.insert({name:"LiHong",gender:18});
db.stu01.insert({_id:"20181010",name:"LiHong",gender:18});
#插入文档的输入,如果不指定”_id“,MongoDB就会自动分配一个唯一ObjectID。2.保存:
db.集合名称.save(document);
#如果文档的_id存在,就修改;反之就创建。
db.demo.save({"_id":ObjectId("5fe05850f2940020e71199aa"),"name":"wq",age:213})3.更新:
db.集合名称.update(<query>,<update>,{multi:<boolean>});
--query:查询条件
--update:更新操作符
--multi:可选参数,默认为false,就更新符合条件的第一条数据;反之为true,更新满足条件的所有数据。例如:

上图所述:
db.shu01.update({name:"MZC"},{age:40});
#会将第一次出现的name为 “MZC” 的数据,整条替换为age : 40 (即name的字段会不见)想要避免上述情况:
db.stu01.update({name:"LiMing"},{$set:{age:100}});
#只更新首次出现满足条件的 age 属性值! 
更新满足条件的多条数据:
db.stu01.updatae({},{$set:{age:20}},{multi:true});
--multi:改变所有满足条件的数据!4.删除:
db.集合名称.remove(<jquery>,{justOne:<boolean>});
--jquery:删除满足条件的
--justOne:默认为false,删除多条;若设置为true or 1 ,则只删除一条。 5.查找:
db.stu01.find();三. MongoDB的数据备份与恢复
MongoDB备份的基本语法:
mongodump -h dbhost -d dbname -o dbdirectory 注意:
该命令要在终端使用。
其中:
-h:服务器地址,也可以是指定的端口号。
-d:需要备份的数据库的名称。
-o:备份数据存放的位置,此目录中存放着备份出来的数据。
MongoDB数据恢复的基本语法:
mongorestore -h dbhost -d dbname --dir dbdirectory其中:
-h:服务器地址,也可以是指定的端口号。
-d:需要恢复的数据库的名称。
--dir:备份数据所在的位置。
其中bson与json的区别:BSON是一种类json的一种二进制形式的存储格式,简称Binary JSON,它和JSON一样,支持内嵌的文档对象和数组对象,但是BSON有JSON没有的一些数据类型,如Date和BinData类型。BSON是由10gen开发的一个数据格式,目前主要用于MongoDB中,是mongodb的数据存储格式。BSON基于JSON格式,选择JSON进行改造的原因主要是JSON的通用性及JSON的schemaless的特性。BSON主要会实现以下三点目标:(1)更快的遍历速度对JSON格式来说,太大的JSON结构会导致数据遍历非常慢。在JSON中,要跳过一个文档进行数据读取,需要对此文档进行扫描才行,需要进行麻烦的数据结构匹配,比如括号的匹配,而BSON对JSON的一大改进就是,它会将JSON的每一个元素的长度存在元素的头部,这样你只需要读取到元素长度就能直接seek到指定的点上进行读取了。(2)操作更简易对JSON来说,数据存储是无类型的,比如你要修改基本一个值,从9到10,由于从一个字符变成了两个,所以可能其后面的所有内容都需要往后移一位才可以。而使用BSON,你可以指定这个列为数字列,那么无论数字从9长到10还是100,我们都只是在存储数字的那一位上进行修改,不会导致数据总长变大。当然,在MongoDB中,如果数字从整形增大到长整型,还是会导致数据总长变大的。(3)增加了额外的数据类型JSON是一个很方便的数据交换格式,但是其类型比较有限。BSON在其基础上增加了“byte array”数据类型。这使得二进制的存储不再需要先base64转换后再存成JSON。大大减少了计算开销和数据大小。但是,在有的时候, BSON相对JSON来说也并没有空间上的优势 ,比如对{“field”:7},在JSON的存储上7只使用了一个字节,而如果用BSON,那就是至少4个字节(32位)目前在10gen的努力下,BSON已经有了针对多种语言的编码解码包。并且都是Apache 2 license下开源的。并且还在随着MongoDB进一步地发展。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 记一次.NET内存居高不下排查解决与启示
· 探究高空视频全景AR技术的实现原理
· 理解Rust引用及其生命周期标识(上)
· 浏览器原生「磁吸」效果!Anchor Positioning 锚点定位神器解析
· 没有源码,如何修改代码逻辑?
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· MongoDB 8.0这个新功能碉堡了,比商业数据库还牛
· .NET10 - 预览版1新功能体验(一)