统计学理论得以发展,主要还是因为无法观测到全体,需要抽样,需要通过样本推断总体,才发展了许多方法。
居然有这么多说大数据时代统计无用的观点!?楼上各位的眼中统计似乎只是门抽样学。
以前当n大于30的时候我们就认为样本量足够大可以套用大数定
律了,和现在所谓的大数据比起来真是小巫见大巫。数据量的爆发式增长和硬件存储技术的发展让大量数据成为了潜力无穷的财富,各行各业的人都开始说自己在搞
大数据。计算机科学,信息技术,应用数学,计算数学,运筹学,工业工程,电子工程,连政治领域都有人开始拿大数据在文章,只要想拿经费,都声称自己在做大
数据。可又似乎唯独听不到统计的声音。
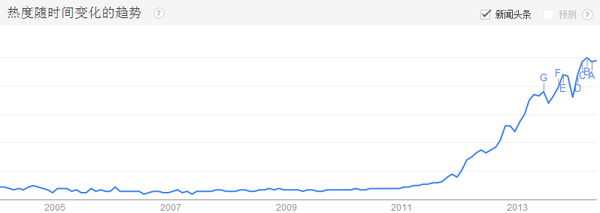
google上"big data"的搜索热度趋势:
![]()
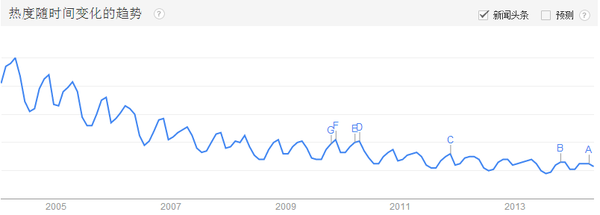
"statistics"一词的搜索热度趋势:
![]()
大数据时代的到来似乎反而让统计变得边缘化。
但是必须在开头就阐释清楚:
大数据并意味着全面,准确和真实。统计对大数据的生命力和应用价值都有着至关重要的作用。很多人支持这样一种观点:数据中包含了所有的意义,不需要什么理论。更有甚者把value作为大数据
3V定义之后的第四个V ,大数据就意味着价值,是吗?
我
们似乎忘了,数据≠信息/知识。大数据很大,这通常是因为它是自动收集的,这也意味着很多的噪声信息。这有时候就被称作DRIP---Data Rich
Information Poor
。打个简单的比方,把大数据比作一座煤矿,如果它自身已经包含了全部的价值,那也就不需要统计学家做什么事儿了,不用挖掘直接拿过来就是了。好像只要计算
能力足够强大,一种潜在的模式就会显现。还有人说数据量的增加使得显著性在任何时候都很强,p
value之类的检验方法已经死亡,这实际上是对统计明显的误解
。大数据不能代表统计的思维,相对于一种“算法倾向”的方法,一种“科学倾向”的方法在处理大数据时往往更加重要。
Google流感病毒预测是大数据应用的标志之一,搜索记录和流感感染的相关性是该模型得以成功的关键。但这些数据模型的成功应用离不开统计思维的支撑。统计学家会告诉你相关性替代不了因果关系,如果你不知道相关关系如何产生,也就不知道它何时会消失。
Data
have no meaning in themselves;they are meaningful only in relation to a
conceptual model of the phenomenon to be studied. ---George Box
统计学家太习惯处理结构良好的数据,需要对传统的统计方法和研究方向作出调整,以下列出一些方向仅作抛砖:
- 构造并解决“未定义”的问题。 统计学家往往很喜欢结构良好的数据和明确的统计问题,大数据带来了许多机会,但这些似乎都不在“传统的标准的”统计学框架中,统计学家需要花费力气把未知问题转化为可用统计方法方便处理的问题。
- 分析不同结构的数据。绝大部分现有的统计方法都局限在处理数字数据上,尽管现在已经有人在做函数数据或者文本数据,但还需要更多启发性的思考。
- 描述性统计的统计。这可能有些不太好理解,当处理大量问题时,很有可能会有很多的统计结果在其中,如何从中抽取有用的信息?比如当有数以千计的相关关系时,当有数以千计的方差分析时。从这些统计结果种提取我们想要的足够多的信息。
- 大多数还是极少数。这两个方面都会有重要的应用,需要有对这两个方面的特征获取和模式识别的基本方法。
这是统计的黄金时代,却不一定是统计学家的。 Data
science是一门纷杂的学科,大数据相比小样本就像是摩天大楼对比小平房,能将十个人装进平房,也能将更多的人装进摩天大楼。同样的,一座大楼的坍塌
带来的灾难比平房损毁要严重的多。 作为统计专业的学生,希望统计能够帮助甚至领导其它学科创造前沿的有用的方法,迎接这个数据时代。
![]() data science is a rocket science,be prepared.参考文献:Statistics for big data: are statisticians ready for big data
data science is a rocket science,be prepared.参考文献:Statistics for big data: are statisticians ready for big data
收藏
•
没有帮助
•
举报
•
作者保留权利
![]() 许靖银行/数据挖掘/andriod开发
许靖银行/数据挖掘/andriod开发
怎么感觉前面的答案都是门外汉在胡扯,现在业内流行一句话是,学数学的瞧不起学统计的,学统计的瞧不起学数据挖掘的。因为当你真的开始接触数据挖掘的算法的时候,你会发现几个瓶颈:
第一是精度和泛化性的问题,这是你不用测试集验证集通过样本内样本外测试是没法达到均衡的。
第
二是模型优化及调参问题,你不懂算法原理根本就不知道怎么调,这个时候绝大多数人就放弃了,少部分人开始研读算法,要知道大多数算法只有读国外大牛英文文
献才能搞懂的,结果一看,哇靠,LDA,SVD,SVM,随机森林,神经网络,贝叶斯,最大熵,EM,混合高斯,HMM等等,哪个不是根据严格的凸优化及
概率图模型或者信息论严格推导出来的?这些都是实打实的数学概率统计基础.
第三,业内标准的数据挖掘流程中最重要的一步是数据清洗和缺失填补,怎么洗,怎么填?现有的非监督算法都没办法很好的解决的哦!基础的还得计算每一个特征的显著性统计量,根据分位数,均值方差协方差相关系数进行过滤,填补,这一步是建模的关键哦!
最后,模型因子的显著性评价,在一些算法,虽然指标证明是优秀的,但是如果因子的假设性检验证明不显著的话,无疑是烂模型,稍微学过统计的应该可以理解。骚年,要玩数据挖掘还是老老实实地一步一步来吧。
我是分隔符
补充一句,数据是可增的,不管数据量多大,也只不过是一个时间断面的样本数据,不是全量。作为一个稳定的模型,必须是要保证长时间稳定的,在这个角度说,构建模型的始终只是用了某一个时间截面的样本数据而已。
![]() 何史提优秀回答者DIKW金字塔底层民工
何史提优秀回答者DIKW金字塔底层民工
看到大家的讨论,又说什麽统计有用无用之类的,我也忍不住插嘴了。
在现代,没有任何学科是独立成科的,很多工作和研究都是跨专业的
(inter-disciplinary),谈到大数据,这已经是一个跨专业的领域,包括了计算机科学、统计学、数学、语理学,而你所在行业的不同也使你
有不同类型的知识。我是唸物理的,但同事中有唸化学、数学、运筹学、商业管理、气象、影像处理等。由于各专业对统计的看法都不一样,所以大家的看法不一
样,甚至大家说统计有用或无用之类的可能还跟大家心目中统计学的定义之差异甚大关係。
谈到机器学习算法,那已经是统计的东西了。如果你用
Naive Bayes,那便是统计学。还有MaxEnt、HMM、MCMC等,又或graphical
model,本身都是统计学方法,更明确点说是用概率论的统计学,你要懂各种分佈,要懂Bayes’
rule、MLE,否则便无法明白箇中含义而变成number crunching了。还有一些抽样方法,如Gibbs
sampling、metropolis algorithm等,都是统计学的东西。有一些其他算法如neural
network、SVM等,本身不是统计,但你在收集结果分析时,你便要统计一下,算一算precision、recall等。
太多东西要学了,不是统计学背景的我每天都在赶路似的。
当
然还有一些传统的统计学如t-test、chi-square
test、ANOVA(我真的不太懂这些),在大数据中可能用得不多(如果你用得多,请扬声,我站在自己的情况说的了),但这些在科学研究上还用得上,因
为这些东西可使我们在抽样数据不多的情况下用以检验模型。这可理解,因为一个图上的一点,在实验上可能是花了九牛二虎之力(和以天文数字计的金钱)才可得
出的,那一点可能代表真实世界上的其他大量的点总合起来。在上一世纪,即使有大量数据,我们无电脑辅助处理。但这在大数据的情况下,点太多了,而电脑也有
能力处理这些数据,问题反而是我们如何取得有用的资料。所以,问题不是统计学有用或无用,而是我们需要统计学中的范筹可能跟传统的不同了。
![]() 优秀回答者五岳倒为轻。
优秀回答者五岳倒为轻。
大数据只是数据量大,不代表我们能观测到总体。有的时候,总体是可测的。比如总体是中国每个人的收入,中国李姓公民的数量;但在更多时候,总体从理论上就是无法观测的。比如即便我们知道纽约证交所自成立以来的全部股价数据,我们也没法知道主宰股价背后的机制模型。这时统计学就是必须的,它帮我们从数据里还原出数据背后的真实,如同感官将显象背后的物自体呈现给人类理性。
随着数据挖掘技术的发展,数据的获取自然会越来越容易,但统计学作为从数据中读取信息的科学,应该永远和获取数据的学问相伴相生。
谢Y。统计学习是一种方法,方法的好坏取决于人的使用。
数据挖掘是众多学科与统计学交叉产生的一门新兴学科。
- 共同的目标。两者都包含了大量的数学模型,都试图通过对数据的描述,建立模型找出数据之间的关系,从而解决商业问题。
- 共用模型。包括线性回归、logistic回归、聚类、时间序列、主成分分析等。
- 思想不一样。数据挖掘偏向计算机学科,所关注的某些领域和统计学家所关注的有很大不同。不一定要有精确的理论支撑,只要是有用的,能够解决问题的方式,都可以用来处理数据。而统计学是一门比较保守的学科,所沿用的模型一定要强调有理论依据(数学原理或经济学理论)。
- 处理数据量不一样。统计学通常使用样本数据,通过对样本数据的估计来估算总体变量。数据挖掘使用的往往是总体数据,这也在过去的年代生产力和技术限制所致。数据挖掘由于采用了数据库原理和计算机技术,它可以处理海量数据。
- 发现的知识方式不一样。数据挖掘的本质是很偶然的发现非预期但很有价值的知识和信息。这说明数据挖掘过程本质上是实验性的。而统计学强调确定性分析。确定性分析着眼于寻找一个最适合的模型——建立一个推荐模型,这个模型也许不能很好的解释观测到的数据。
以上。
![]() 徐昇金融数学,软件工程,不小心修了两个专业。
徐昇金融数学,软件工程,不小心修了两个专业。
反对
@Han Hsiao 把数据挖掘当作一门独立学科和统计学比较。数据挖掘和统计学的关系就好像熊猫和哺乳纲。有人比较哺乳纲和熊猫的相同点和不同点的么。
没有一定统计基础的大数据er,不是好的大数据er. 大数据发现的结果最终还是为了发现事物之间的普遍和联系。所以大数据归根到底是只是统计的技术实现手段,算是为统计学科服务发展出来的一个技术分支,但是也必须承认其扩展了统计学范畴的积极意义。
匿
名答案说统计学是伪科学很搞笑的。统计学研究样本的观点更加搞笑。如果能研究总体,谁愿意研究样本。只是以前没有那个技术能力。而且就算是大数据时代,研
究的对象也不可能是总体,只能说在截面数据的样本上无限逼近总体。因此在计算的时候,如果样本足够大,可以采用总体的计算公式,也可以采用
@姚信炫 提到的全样本分析 。至于时间序列,那么抱歉大数据还是很难解决问题。解决时间序列的抽样难题,无限逼近总体,需要平行空间和时光机。
---------------------------------------
我只是来嘲讽的。
不是有多大的效果,而是沒有統計為理論基礎就是死,就不要再談什麼大數據了,最好連數據都不要再談了。
統計學也不是「统计学理论得以发展,主要还是因为无法观测到全体,需要抽样,需要通过样本推断总体,才发展了许多方法」所說這個樣子的。
「我不懂統計還不是一樣會處理大數據」的情況肯定是有。如果即便如此也能應付「處理大數據」的需求也不錯啊那就好好做唄。觀點不同只是大家追求的東西不一樣罷了。
我始終認為該投入的學習成本不能減不能少。也許一時半會沒感覺,長久來看必有捉襟見肘之時。
要形成大数据的条件之一就是垄断,起码是规模经济,像google这样的大家伙,否则怎么能得到几乎覆盖总体的样本?这也就决定了数据也是会有垄断性的,所以我觉得以后的情况就是绝大多数机构根本取得不了大数据,何来大数据分析?当然不排除有数据交易或者其他新式的交换共享模式。传统统计学方法应该还是会有用武之地的
更多数据有助于 怎样(做) 而不只是做什么或者只是什么之类的。
what how 之前区别更有利于区分。
都不说现在了,咱们说一个二战的事吧。
二战盟军是用统计学推算出德国坦克的产量等数据,从而取得了胜利。具体的可以看下面的链接
概率统计在战争情报中的应用
首先,数据量的增加,有助于减小数据的误差,如抽样误差等,能够极大地提高各类分析的精准度,这是大数据对于统计学的直接影响之一。
尽管当今的”大数据“潮流使得我们获得了海量的数据,但掌握这些海量的数据本身并无意义。真正的意义体现在对于含有信息的数据进行专业化的处理。要对大数据进行处理,即在样本几乎等于总体的情况下,以目前的分析方法以及分析设备成本较高,耗时较长。
相比之下,统计学的抽样方法似乎显得更加”经济实惠“。在实际的运用中,统计学能够以较低的成本,较少的数据,对数据进行精确度相对较高的的分析,这是大数据分析所无法替代的。
甚至有学者指出,很多情况下,只要有一定的数据,无关数据数量,分析结果不会有太大差别,因此大数据也就显得不重要了。不敢说这话完全正确,但很大程度上
说明了统计学对于数据分析处理的意义。通过一定的数据即可满足人们对于数据处理的需要,统计学极大地提高了人们对于数据处理的效率。
大数据的来临会推动统计学的发展,衍生出更多的发展方向,但绝不会替代统计学,也不会减弱统计学的效果与意义。
今天刚刚看了部分《大数据时代 生活、工作与思维的大变革》这本书,讲到了大数据和统计学之间的关系,知乎上搜了下,居然有问到,就转一些作者的观点过来。回答lz的问题前
先要假定大数据时代是会来临的,即日后我们能较为容易的获得大数据,而且数据处理也相对较容易。
那么在此基础上,书中作者指出大数据带来的转变会有以下几点:
1. 可以了解到更为全面的情况
大数据时代,我们可以有更全面的数据来研究,如楼上所说,甚至可以认为是 样本==总体,那么,就不用再做一些统计上随机采样的工作了,基于大数据的研究可以关注到统计研究上难以关注到的一些小的、个别的情况,这些情况往往会呈现出更大的价值。
2.我们不再追求精确度。
在数据量很小的时候,研究往往会对精确度做很严格的要求,而大数据时代会把这些条件放的更加宽松,不然大数据很难应用于研究,这种情况下,尽管数据的准确度降低了,但大量的数据会给我们带来额外的收益
3.基于前两个转变,我们不再寻找因果关系,而是去关注关联关系,即倾向关注“是什么”,而不是“为什么”(翻译此书的周涛不太认同这个观点,他认为是现在一些基于机器学习的算法得出的结果驱使我们去仅仅关注关联关系,因为我们现在很难把这些复杂算法转换成因果关系了)
以上是大数据会带来的变化,第一点应该会直接影响统计学,后面两点可能也会有一些影响,我不太懂统计学,ls说的是在数据量小的情况下,统计学的作用是无可替代的。
但是,如果大数据时代真的来临,即如果我们每天的生活都离不开它的话,
那么我想部分统计学方法的价值可能会下降,就是不用特意去处理样本和整体的关系了,随机采样什么的也没什么必要了,当然也会推动新的统计方法的产生。谁不喜欢更为全面的分析呢,就比如正态分布一样,统计学可以用较少的代价描述中间的分布,但是当代价不成问题的时候,谁不希望多了解一下那些边边角角呢?
===================================================
11.28更新,我觉得上面说的还是有很多错误,最近看了一些机器学习的算法,有很多都是基于统计知识来做的,我不知道未来是不是真的如预料的那样能轻易获得大数据,但是对数据的处理的很多方法还真是需要统计知识的,统计学很重要!
顺便贴一个相关问题的连接
大数据时代和数据分析需求,统计还沾边吗?这个也是转载的
感觉前面一些回答并不特别懂统计学,题主所说的只是统计的一个方面。大且数据并不等于总体。对于传统的统计方法,当数据量过大的时候,会出现干扰信息或者
说噪音过大,聚类分析会变的困难。很多数据和我们想研究的东西并不相关,如何提出大量无关数据也是需要统计上的方法。而如果是测到的变量很多,也就是所谓
高纬,比如生物统计上对于基因的分析,传统的最大似然法,线性回归的方法的效果会变的很差,一些新的方法就会被提出来解决这些问题。所以大数据反而需要统
计上新的方法来解决其面临的问题,这正是最近统计学的热点。
统计学不只有那一点抽样技术&一大堆靠小样本猜大样本的东西
上面太多统计盲在看热闹
举了一大堆所谓的靠枚举来直接发现结果不需要统计,实质上主要过程都是主成分分析+属性数据分析好吗?
且不说生存分析、时间序列、假设检验这种大数据也做不到或者不能做全样本的领域
即使能做到,收集数据、分析数据的成本也都是直接与数据量相关的
统计学基础有置信度和置信区间的概念
通俗点说就是帮助你在成本、效率和精确度之间做平衡
不管你是商用、民用、军用还是科研用,没有人会不计成本地获得数据结果
如果丢个硬币正面为上的概率这样一个数据结果也要你上万美元去买单,你是否还会选择大数据?
大数据=大忽悠
抽样是不可避免的。不仅不是观测不到总体的问题,还有不能去观测总体的问题。我要统计一批火柴的点着合格率,不可能把所有火柴都点了。
Big data and high dimensional data is the key hot of Statisitcs
research. Actually, data mining and machine learning especially focus on
these kind if data analysis. So I think the more the big data, the more
improvement of Statistical science.
想要学好大数据,对培训机构的选择很重要,一定要慎重。想要学习这一行,就要抱着吃苦学习的决心,否则就是浪费时间和金钱。一般都会去一些技术贴吧了解、交流学习经验,比如普开数据贴吧。没事可以去逛逛,一定会有收获。
对于大数量的raw data以及big data, 统计学目前应该是遇到了危(险)机(遇),但看好统计在不久的将来会出现大量的新型的统计学家,统计模型和统计理论。
![]() 王涛cia cicpa 关注大数据下的审计问题
王涛cia cicpa 关注大数据下的审计问题
本人也在入门学习阶段,转发一篇链接仅供参考大数据时代,统计学还有用吗?--浙江频道--人民网
 data science is a rocket science,be prepared.
data science is a rocket science,be prepared.

 优秀回答者五岳倒为轻。
优秀回答者五岳倒为轻。













 浙公网安备 33010602011771号
浙公网安备 33010602011771号