java核心数据结构总结
JDK提供了一组主要的数据结构的实现,如List、Set、Map等常用结构,这些结构都继承自java.util.collection接口。
- List接口
List有三种不同的实现,ArrayList和Vector使用数组实现,其封装了对内部数组的操作。LinkedList使用了循环双向链表的数据结构,LinkedList链表是由一系列的链表项连接而成,一个链表项包括三部分:链表内容、前驱表项和后驱表项。
LinkedList的表项结构如图:
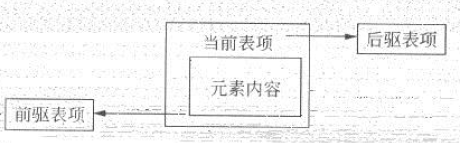
LinkedList表项间的连接关系如图:

可以看出,无论LinkedList是否为空,链表都有一个header表项,它即表示链表的开头也表示链表的结尾。表项header的后驱表项便是链表的第一个元素,其前驱表项就是链表的最后一个元素。
对基于链表和基于数组的两种List的不同实现做一些比较:
1、增加元素到列表的末尾:
在ArrayList中源代码如下:
1 public boolean add(E e) { 2 ensureCapacityInternal(size + 1); // Increments modCount!! 3 elementData[size++] = e; 4 return true; 5 }
add()方法性能的好坏取决于grow()方法的性能:
1 private void grow(int minCapacity) { 2 // overflow-conscious code 3 int oldCapacity = elementData.length; 4 int newCapacity = oldCapacity + (oldCapacity >> 1); 5 if (newCapacity - minCapacity < 0) 6 newCapacity = minCapacity; 7 if (newCapacity - MAX_ARRAY_SIZE > 0) 8 newCapacity = hugeCapacity(minCapacity); 9 // minCapacity is usually close to size, so this is a win: 10 elementData = Arrays.copyOf(elementData, newCapacity); 11 }
可以看出,当ArrayList对容量的需求超过当前数组的大小是,会进行数组扩容,扩容的过程中需要大量的数组复制,数组复制调用System.arraycopy()方法,操作效率是非常快的。
在LinkedList源码中add()方法:
1 public boolean add(E e) { 2 linkLast(e); 3 return true; 4 }
linkLast()方法如下:
1 void linkLast(E e) { 2 final Node<E> l = last; 3 final Node<E> newNode = new Node<>(l, e, null); 4 last = newNode; 5 if (l == null) 6 first = newNode; 7 else 8 l.next = newNode; 9 size++; 10 modCount++; 11 }
LinkedList是基于链表实现,因此不需要维护容量大小,但是每次都新增元素都要新建一个Node对象,并进行一系列赋值,在频繁系统调用中,对系统性能有一定影响。性能测试得出,在列表末尾增加元素,ArrayList比LinkedList性能要好,因为数组是连续的,在末尾增加元素,只有在空间不足时才会进行数组扩容,大部分情况下追加操作效率还是比较高的。
2、增加元素到列表的任意位置:
List接口还提供了在任意位置插入元素的方法:void add(int index,E element)方法,由于实现方式不同,ArrayList和LinkedList在这个方法上存在一定的差异。由于ArrayList是基于数组实现的,而数组是一块连续的内存,如果在数组的任意位置插入元素,必然会导致该位置之后的所有元素重新排序,其效率相对较低。
ArrayList源码实现:
1 public void add(int index, E element) { 2 rangeCheckForAdd(index); 3 ensureCapacityInternal(size + 1); // Increments modCount!! 4 System.arraycopy(elementData, index, elementData, index + 1, 5 size - index); 6 elementData[index] = element; 7 size++; 8 }
可以看出每次插入都会进行数组复制,大量的数组复制操作导致系统性能效率低下。并且数组插入的位置越靠前,数组复制的开销就越大。因此,尽可能插入元素在其尾端附近,有助于提高该方法的性能。
LinkedList的源码实现:
1 public void add(int index, E element) { 2 checkPositionIndex(index); 3 4 if (index == size) 5 linkLast(element); 6 else 7 linkBefore(element, node(index)); 8 } 9 void linkBefore(E e, Node<E> succ) { 10 // assert succ != null; 11 final Node<E> pred = succ.prev; 12 final Node<E> newNode = new Node<>(pred, e, succ); 13 succ.prev = newNode; 14 if (pred == null) 15 first = newNode; 16 else 17 pred.next = newNode; 18 size++; 19 modCount++; 20 }
对于LinkedList的在尾端插入和对任意位置插入数据是一样的,并不会因为插入位置靠前而导致效率低下。因此,在应用中,如果经常往任意位置插入元素,可以考虑使用LinkedList提到ArrayList。
3、删除任意位置的元素:
List接口还提供了在任意位置删除元素的方法:remove(int index)方法。在ArrayList中,对于remove()方法和add()方法一样,在任意位置移除元素,都需要数组复制。
ArrayList的remove()方法的源码如下:
1 public E remove(int index) { 2 rangeCheck(index); 3 4 modCount++; 5 E oldValue = elementData(index); 6 7 int numMoved = size - index - 1; 8 if (numMoved > 0) 9 System.arraycopy(elementData, index+1, elementData, index, 10 numMoved); 11 elementData[--size] = null; // clear to let GC do its work 12 13 return oldValue; 14 }
可以看出,在ArrayList的每一次删除操作,都需要进行数组重组,并且删除元素的位置越靠前,数组重组的开销就越大。
LinkedList的remove()方法的源码:
1 public E remove(int index) { 2 checkElementIndex(index); 3 return unlink(node(index)); 4 } 5 E unlink(Node<E> x) { 6 // assert x != null; 7 final E element = x.item; 8 final Node<E> next = x.next; 9 final Node<E> prev = x.prev; 10 11 if (prev == null) { 12 first = next; 13 } else { 14 prev.next = next; 15 x.prev = null; 16 } 17 18 if (next == null) { 19 last = prev; 20 } else { 21 next.prev = prev; 22 x.next = null; 23 } 24 25 x.item = null; 26 size--; 27 modCount++; 28 return element; 29 }
1 Node<E> node(int index) { 2 // assert isElementIndex(index); 3 4 if (index < (size >> 1)) { 5 Node<E> x = first; 6 for (int i = 0; i < index; i++) 7 x = x.next; 8 return x; 9 } else { 10 Node<E> x = last; 11 for (int i = size - 1; i > index; i--) 12 x = x.prev; 13 return x; 14 } 15 }
在LinkedList中首先通过循环找到要删除的元素,如果元素位于前半段则,从前往后找;若位置位于后半段,则从后往前找,但是要移除中间的元素,却几乎要遍历半个List。所有,无论元素位于较前还是较后,效率都比较高,但是位于中间效率就非常低。
4、容量参数:
容量参数是ArrayList和Vector等基于数组的List特有的性能参数,它表示初始化数组的大小。当数组所存储的元素的数量超过其原有的大小时,它就会进行扩容,即进行一次数组复制,因此,合理设置数组大小有助于减少扩容次数,从而提升系统性能。
5、遍历列表:
在JDK1.5之后,至少有三种遍历列表的方式:forEach操作,迭代器,for循环。通过测试发现,forEach综合性能不如迭代器,而for循环遍历列表时,ArrayList的性能表现最好,而LinkedList的性能差的无法忍受,因为LinkedList进行随机访问,总会进行一次列表的遍历操作。
对于ArrayList是基于数组来实现的,随机访问效率快,因此有限选择随机访问。而LinkedList是基于链表实现的,随机访问的性能差,应该避免使用。
- Map接口
围绕着Map接口,最主要的实现类有:HashMap、hashTable、LinkedHashMap和TreeMap。在HashMap的子类中还有Properties类的实现。
1、HashMap和Hashtable
首先说一下,HashMap和Hashtable的区别:Hashtable的大部分方法都实现了同步,而HashMap没有。因此,HashMap不是线程安全的。其次,Hashtable不允许key或value使用null值,而HashMap可以。第三是内部的算法不同,它们对key的hash算法和hash值到内存索引的映射算法不同。
HashMap就是将key做hash算法,然后将hash值映射到内存地址,直接取得key所对应的数据。在HashMap的底层使用的是数组,所谓的内存地址即数组的下标索引。
HashMap中不得不提的就是hash冲突,需要存放到HashMap中的元素1和元素2经过hash计算,发现对应的内存地址一样。如下图:
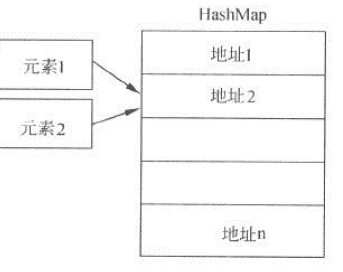
HashMap底层使用的是数组,但是数组内的元素不是简单的值,而是一个Entry对象。如下图所示:

可以看出,HashMap的内部维护了一个Entry数组,每个entry表项包括:key、value、next、hash。next部分表示指向另一个Entry。在HashMap的put()方法中,可以看到当put()方法有冲突时,新的entry依然会安放在对应的索引下标内,并替换掉原来的值,同时为了保证旧值不丢失,会将新的entry的next指向旧值。这样便实现了在一个数组索引空间内存放多个值。
HashMap的put()操作的源码:
1 public V put(K key, V value) { 2 if (table == EMPTY_TABLE) { 3 inflateTable(threshold); 4 } 5 if (key == null) 6 return putForNullKey(value); 7 int hash = hash(key); 8 int i = indexFor(hash, table.length); 9 for (Entry<K,V> e = table[i]; e != null; e = e.next) { 10 Object k; 11 if (e.hash == hash && ((k = e.key) == key || key.equals(k))) { 12 V oldValue = e.value;//取得旧值 13 e.value = value; 14 e.recordAccess(this); 15 return oldValue;//返回旧值 16 } 17 } 18 19 modCount++; 20 addEntry(hash, key, value, i);//添加当前表项到i位置 21 return null; 22 } 23 void addEntry(int hash, K key, V value, int bucketIndex) { 24 if ((size >= threshold) && (null != table[bucketIndex])) { 25 resize(2 * table.length); 26 hash = (null != key) ? hash(key) : 0; 27 bucketIndex = indexFor(hash, table.length); 28 } 29 30 createEntry(hash, key, value, bucketIndex); 31 } 32 void createEntry(int hash, K key, V value, int bucketIndex) { 33 Entry<K,V> e = table[bucketIndex]; 34 table[bucketIndex] = new Entry<>(hash, key, value, e);//将新增元素放到i位置,并把它的next指向旧值 35 size++; 36 }
基于HashMap的这种实现,只要对hashCode()和hash()的方法实现的够好,就能尽可能的减少冲突,那么对HashMap的操作就等价于对数组随机访问的操作,具有很好的性能。但是,如果处理不好,在产生大量冲突的情况下,HashMap就退化为几个链表,性能极差。
2、容量参数:
因为HashMap和Hashtable底层是基于数组实现的,当数组空间不足时,就会进行数组扩容,数组扩容就会进行数组复制,是十分影响性能的。
HashMap的构造函数:
1 public HashMap(int initialCapacity) 2 public HashMap(int initialCapacity, float loadFactor)
initialCapacity指定HashMap的初始容量,loadFactor是指负载因子(元素个数/元素总量),HashMap中还定义了一个阈值,它是当前数组容量和负载因子的乘积,当数组的实际容量超过阈值时,就会进行数组扩容。
另外,HashMap的性能一定程度上取决于hashCode()的实现,一个好的hashCode()的实现,可以尽可能减少冲突,提升hashMap的访问速度。
3、LinkedHashMap
HashMap的一大缺点就是无序性,放入的数据,在遍历取出时候是无序的。如果需要保证元素输入时的顺序,可以使用LinkedHashMap。
LinkedHashMap继承自HashMap,因此,其性能是比较好。在HashMap的基础上,LinkedHashMap内部又增加了一个链表,用于存放元素的顺序。LinkedHashMap提供了两种类型的顺序,一种是元素插入时的顺序,一种是最近访问的顺序。
1 public LinkedHashMap(int initialCapacity, 2 float loadFactor, 3 boolean accessOrder)
其中,accessOrder为true是,是按元素最后访问时间排序,当accessOrder为false时,按插入顺序排序。
4、TreeMap
TreeMap可以对元素进行排序,TreeMap是基于元素的固有顺序而排序的(有Comparable或Comparator确定)。
TreeMap是根据key进行排序的,为了确定key的排序算法,可以使用两种方法指定:
1:在TreeMap的构造函数中注入Comparator
TreeMap(Comparator<? super K> comparator);
2:使用一个实现了Comparable接口的key。
TreeMap是内部是基于红黑树实现,红黑树是一种平衡查找树,其统计性能优于平衡二叉树。
- Set接口
set集合中的元素是不能重复的,其中最主要的实现就是HashSet、LinkedHashSrt和TreeSet。查看Set接口实现类,可以发现所有的Set的一些实现都是相应Map的一种封装。
set特性如图所示:

- 集合操作的一些优化建议
1、分离循环中被重复调用的代码。如:for(int i=0;i<list.size();i++),可以将list.size()分离出来。
2、省略相同的操作
3、减少方法的调用,方法调用时消耗系统堆栈的,会牺牲系统的性能。
- RandomAccess接口
RandomAccess接口是一个标识接口,本身没有提供任何方法。主要的目的是为了标识出那些可以支持快速随机访问的List的实现。例如,根据是否实现RandomAccess接口在变量的时候选择不同的遍历实现,以提升性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号