clickhouse

- 经验帖
- 网易
- clickhouse-jdbc踩坑
-
ReplacingMergeTree
ReplacingMergeTree就是在MergeTree的基础上加入了去重的功能,参见ReplacingMergeTree
- 如何判断数据重复
ReplacingMergeTree在去除重复数据时,是以ORDERBY排序键为基准的,而不是PRIMARY KEY。
- 何时删除重复数据
在执行分区合并时,会触发删除重复数据。optimize的合并操作是在后台执行的,无法预测具体执行时间点,除非是手动执行。
- 不同分区的重复数据不会被去重
ReplacingMergeTree是以分区为单位删除重复数据的。只有在相同的数据分区内重复的数据才可以被删除,而不同数据分区之间的重复数据依然不能被剔除。
- 数据去重的策略是什么
-
- 若未指定ver参数,则会保留重复数据中最末的那一行数据
- 若指定了ver参数,则会保留重复数据中,ver字段最大的那一行,如果两条记录排序键相同,与未指定ver参数时策略相同
-
主键和排序键
- 创建主键会自动为主键的列创建索引,查询主键列比全表扫描会更快些;
- ClickHouse不要求主键唯一,所以可以插入多条相同主键的行;
- 创建表时,一般不需要指定主键,只要指定排序键即可。当没有指定主键(primary key)时,会把排序键(order by)后面的列作为主键;
- 可以同时指定排序键(order by)和主键(primary key),但主键最好是排序键的前缀
-
AggregatingMergeTree
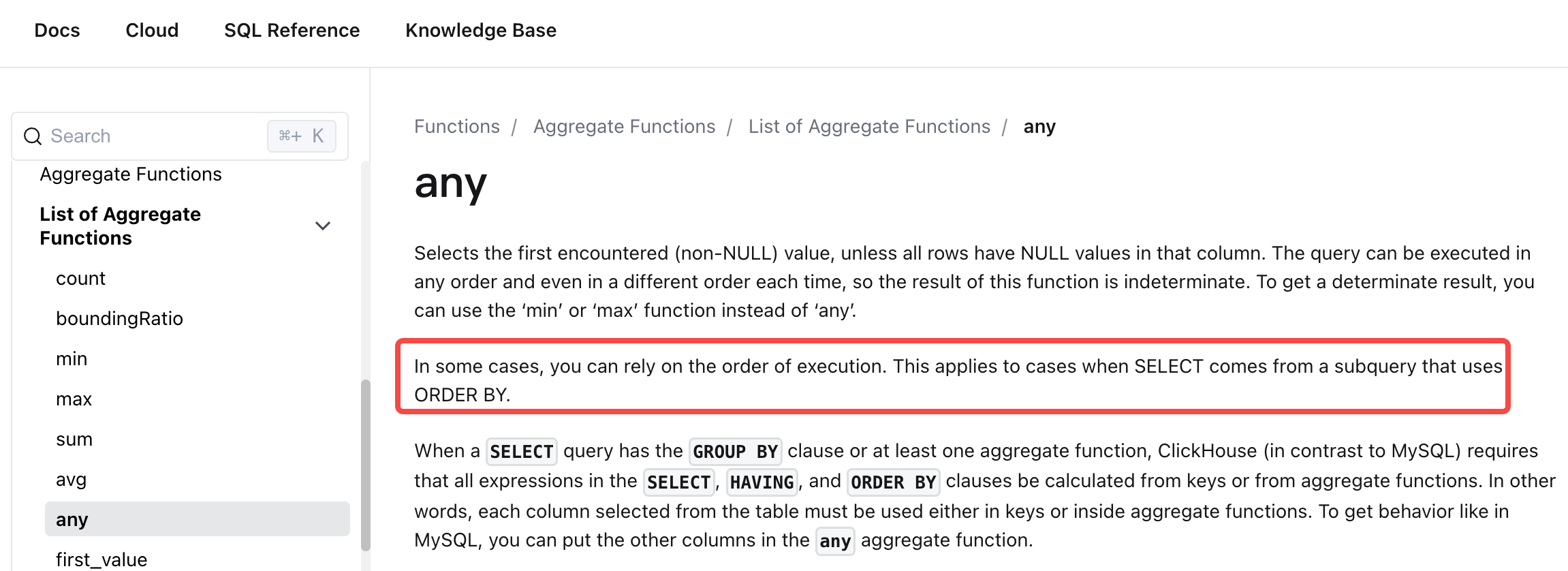
- 使用ORDER BY排序键作为聚合数据的依据,会定期合并,每个字段按合并函数合并,从而实现部分字段更新,anyLast取最后一个非空值,设置默认值不影响字段最终值
- 聚合只会发生在同分区内,不同分区的数据不会发生聚合,只有在合并分区的时候才会触发聚合计算的逻辑
-
在写入数据时,需要调用state函数;在读数据时,需要调用merge函数,*表示定义时使用的聚合函数
- AggregateMergeTree通常作为物化视图的引擎,与普通的MergeTree搭配使用
- pv和uv例子
- 为了保证anyLast获取的是最后一个非空值,要使用order by排序查询
-
flink-json-plus
-
flink-starrocks
-
![]() View Code
View CodeCREATE TABLE seats_binlog ( id bigint primary key, domain_account string, ready int, leave_reason string, `group` string, deleted boolean, create_time string, update_time string, op string ) WITH ( 'connector' = 'kafka', 'topic' = 'ods_pe_occ_realtime_prod_prod.seats_rt', 'properties.bootstrap.servers' = 'xxxx:9092', 'scan.startup.mode' = 'earliest-offset', -- 'properties.linger.ms' = '1000', 'format' = 'debezium-json-plus', 'debezium-json-plus.schema-include' = 'true', -- 'debezium-json.ignore-parse-errors' = 'true', 'properties.group.id'= 'seats_cdc_stg', 'properties.security.protocol' = 'SASL_PLAINTEXT', 'properties.sasl.mechanism' = 'SCRAM-SHA-256' ); create table sink_print ( domain_account string primary key, id bigint, ready int, leave_reason string, `group` string, deleted boolean, create_time string, update_time string, op string ) with ( 'connector' = 'print' ); create table seat_starrocks ( domain_account string primary key, id bigint, ready int, leave_reason string, `group` string, deleted boolean, create_time string, update_time string, op string ) with ( 'connector' = 'starrocks', 'jdbc-url'='jdbc:mysql://10.xxx.xxx.xxx:9030', 'load-url'='10.xxx.xxx.xxx:8030', 'database-name' = 'xxx', 'table-name' = 'dim_seats', 'username' = 'xx', 'password' = 'xxxxxx', 'sink.properties.format' = 'json', 'sink.properties.strip_outer_array' = 'true', 'sink.buffer-flush.interval-ms' = '5000' ); insert into seat_starrocks select IFNULL(domain_account, ''), id, ready, leave_reason, `group`, deleted, CONVERT_TZ(REGEXP_REPLACE(create_time, 'T', ' '), 'UTC', 'Asia/Shanghai'), -- UNIX_TIMESTAMP(date_format(timestampadd(HOUR, 8, to_timestamp(REGEXP_REPLACE(REGEXP_REPLACE(create_time, 'T', ' '), 'Z', ''), 'yyyy-MM-dd HH:mm:ss.SSS')), 'yyyy-MM-dd HH:mm:ss')), CONVERT_TZ(REGEXP_REPLACE(update_time, 'T', ' '), 'UTC', 'Asia/Shanghai'), -- UNIX_TIMESTAMP(date_format(timestampadd(HOUR, 8, to_timestamp(REGEXP_REPLACE(REGEXP_REPLACE(update_time, 'T', ' '), 'Z', ''), 'yyyy-MM-dd HH:mm:ss.SSS')), 'yyyy-MM-dd HH:mm:ss')) op from seats_binlog;



 浙公网安备 33010602011771号
浙公网安备 33010602011771号